 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeLLM: Scaling up Spiking Neural Network to Large Language Models via Saliency-based Spiking
Paper and Code
Jul 05, 2024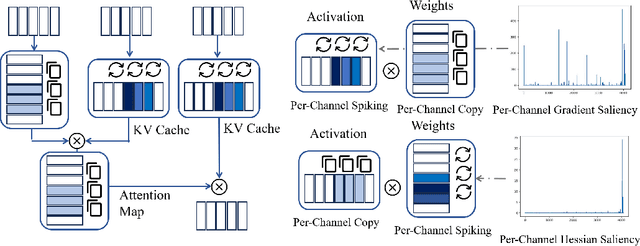
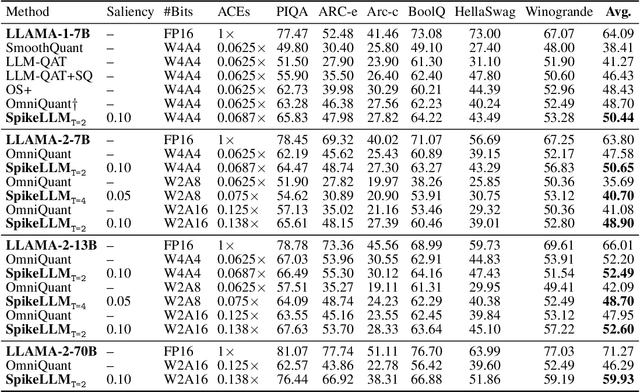

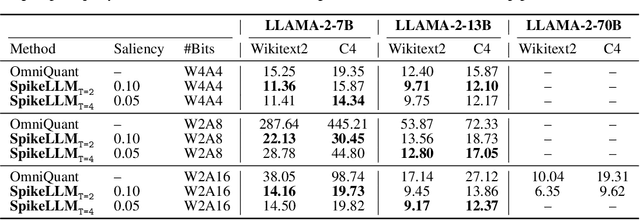
The recent advancements in large language models (LLMs) with billions of parameters have significantly boosted their performance across various real-world applications. However, the inference processes for these models require substantial energy and computational resources, presenting considerable deployment challenges. In contrast, human brains, which contain approximately 86 billion biological neurons, exhibit significantly greater energy efficiency compared to LLMs with a similar number of parameters. Inspired by this, we redesign 7 to 70 billion parameter LLMs using bio-plausible spiking mechanisms, emulating the efficient behavior of the human brain. We propose the first spiking large language model as recent LLMs termed SpikeLLM. Coupled with the proposed model, a novel spike-driven quantization framework named Optimal Brain Spiking is introduced to reduce the energy cost and accelerate inference speed via two essential approaches: first (second)-order differentiation-based salient channel detection, and per-channel salient outlier expansion with Generalized Integrate-and-Fire neurons. Our proposed spike-driven quantization can plug in main streams of quantization training methods. In the OmniQuant pipeline, SpikeLLM significantly reduces 25.51% WikiText2 perplexity and improves 3.08% average accuracy of 6 zero-shot datasets on a LLAMA2-7B 4A4W model. In the GPTQ pipeline, SpikeLLM realizes a sparse ternary quantization, which achieves additive in all linear layers. Compared with PB-LLM with similar operations, SpikeLLM also exceeds significantly. We will release our code on GitHub.