 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPFT: Binary Pre-trained Foundation Transformer with Low-rank Estimation of Binarization Residual Polynomials
Paper and Code
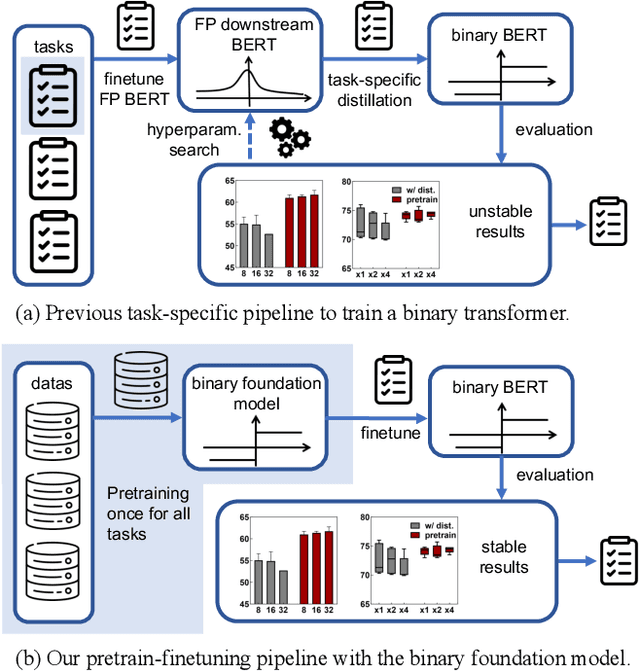
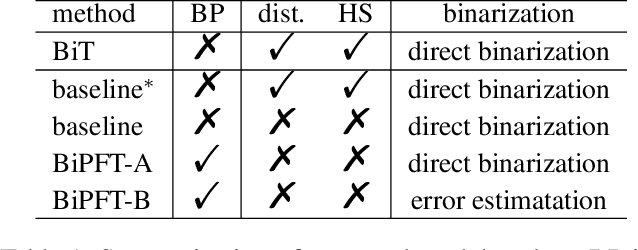
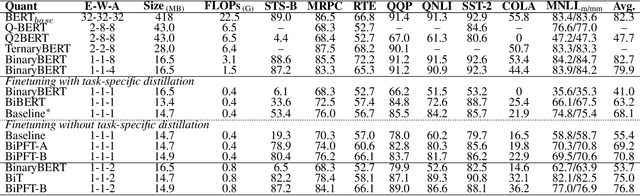
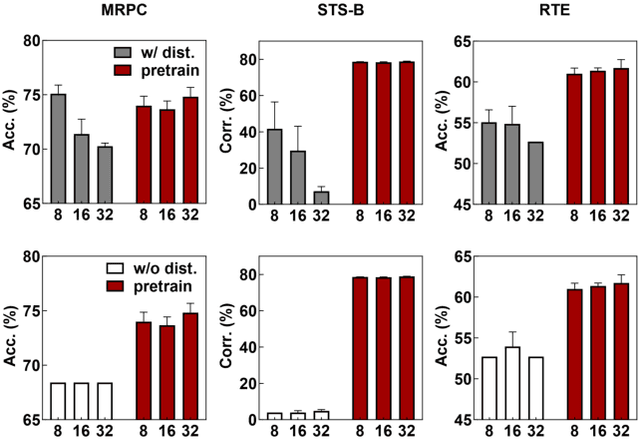
Pretrained foundation models offer substantial benefits for a wide range of downstream tasks, which can be one of the most potential techniques to access artificial general intelligence. However, scaling up foundation transformers for maximal task-agnostic knowledge has brought about computational challenges, especially on resource-limited devices such as mobiles. This work proposes the first Binary Pretrained Foundation Transformer (BiPFT) for natural language understanding (NLU) tasks, which remarkably saves 56 times operations and 28 times memory. In contrast to previous task-specific binary transformers, BiPFT exhibits a substantial enhancement in the learning capabilities of binary neural networks (BNNs), promoting BNNs into the era of pre-training. Benefiting from extensive pretraining data, we further propose a data-driven binarization method. Specifically, we first analyze the binarization error in self-attention operations and derive the polynomials of binarization error. To simulate full-precision self-attention, we define binarization error as binarization residual polynomials, and then introduce low-rank estimators to model these polynomials. Extensive experiments validate the effectiveness of BiPFTs, surpassing task-specific baseline by 15.4% average performance on the GLUE benchmark. BiPFT also demonstrates improved robustness to hyperparameter changes, improved optimization efficiency, and reduced reliance on downstream distillation, which consequently generalize on various NLU tasks and simplify the downstream pipeline of BNNs. Our code and pretrained models are publicly available at https://github.com/Xingrun-Xing/BiPFT.