 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGen: Unified Image Generation
Paper and Code

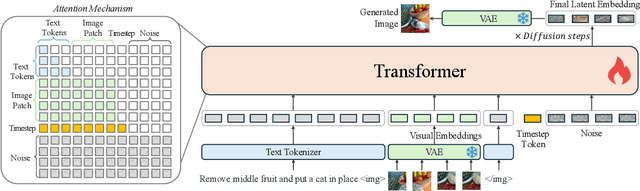
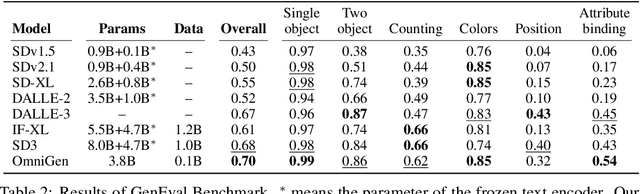

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.