 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
O1 Embedder: Let Retrievers Think Before Action
Feb 12, 2025The growing power of large language models (LLMs) has revolutionized how people access and utilize information. Notably, the LLMs excel at performing fine-grained data representation, which facilitates precise retrieval of information. They also generate high-quality answers based on external references, enabling the production of useful knowledge. The recent introduction of reasoning models, like OpenAI O1 and DeepSeek R1, marks another leap forward, highlighting LLMs' ability to think progressively before delivering final answers. This breakthrough significantly improves the ability to address complex tasks, e.g., coding and math proofs. Inspired by this progress, we aim to develop similar capabilities for retrieval models, which hold great promise for tackling critical challenges in the field, including multi-task retrieval, zero-shot retrieval, and tasks requiring intensive reasoning of complex relationships. With this motivation, we propose a novel approach called O1 Embedder, which generates useful thoughts for the input query before making retrieval for the target documents. To realize this objective, we conquer two technical difficulties. First, we design a data synthesis workflow, creating training signals for O1 Embedder by generating initial thoughts from an LLM-expert and subsequently refining them using a retrieval committee. Second, we optimize the training process, enabling a pre-trained model to be jointly fine-tuned to generate retrieval thoughts via behavior cloning and perform dense retrieval through contrastive learning. Our approach is evaluated by comprehensive experiments, where substantial improvements are achieved across 12 popular datasets, spanning both in-domain and out-of-domain scenarios. These results highlight O1 Embedder's remarkable accuracy and generalizability, paving the way for the development of next-generation IR foundation models.
Molar: Multimodal LLMs with Collaborative Filtering Alignment for Enhanced Sequential Recommendation
Dec 24, 2024Sequential recommendation (SR) systems have evolved significantly over the past decade, transitioning from traditional collaborative filtering to deep learning approaches and, more recently, to large language models (LLMs). While the adoption of LLMs has driven substantial advancements, these models inherently lack collaborative filtering information, relying primarily on textual content data neglecting other modalities and thus failing to achieve optimal recommendation performance. To address this limitation, we propose Molar, a Multimodal large language sequential recommendation framework that integrates multiple content modalities with ID information to capture collaborative signals effectively. Molar employs an MLLM to generate unified item representations from both textual and non-textual data, facilitating comprehensive multimodal modeling and enriching item embeddings. Additionally, it incorporates collaborative filtering signals through a post-alignment mechanism, which aligns user representations from content-based and ID-based models, ensuring precise personalization and robust performance. By seamlessly combining multimodal content with collaborative filtering insights, Molar captures both user interests and contextual semantics, leading to superior recommendation accuracy. Extensive experiments validate that Molar significantly outperforms traditional and LLM-based baselines, highlighting its strength in utilizing multimodal data and collaborative signals for sequential recommendation tasks. The source code is available at https://anonymous.4open.science/r/Molar-8B06/.
OmniGen: Unified Image Generation
Sep 17, 2024
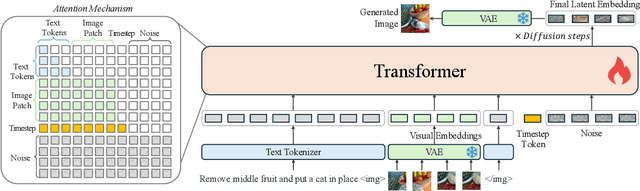
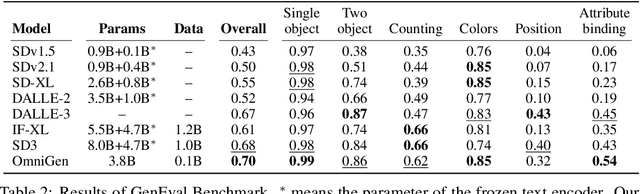

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.