 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes RAG Really Perform Bad For Long-Context Processing?
Feb 17, 2025



The efficient processing of long context poses a serious challenge for large language models (LLMs). Recently, retrieval-augmented generation (RAG) has emerged as a promising strategy for this problem, as it enables LLMs to make selective use of the long context for efficient computation. However, existing RAG approaches lag behind other long-context processing methods due to inherent limitations on inaccurate retrieval and fragmented contexts. To address these challenges, we introduce RetroLM, a novel RAG framework for long-context processing. Unlike traditional methods, RetroLM employs KV-level retrieval augmentation, where it partitions the LLM's KV cache into contiguous pages and retrieves the most crucial ones for efficient computation. This approach enhances robustness to retrieval inaccuracy, facilitates effective utilization of fragmented contexts, and saves the cost from repeated computation. Building on this framework, we further develop a specialized retriever for precise retrieval of critical pages and conduct unsupervised post-training to optimize the model's ability to leverage retrieved information. We conduct comprehensive evaluations with a variety of benchmarks, including LongBench, InfiniteBench, and RULER, where RetroLM significantly outperforms existing long-context LLMs and efficient long-context processing methods, particularly in tasks requiring intensive reasoning or extremely long-context comprehension.
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Jan 09, 2025



Large reasoning models (LRMs) like OpenAI-o1 have demonstrated impressive long stepwise reasoning capabilities through large-scale reinforcement learning. However, their extended reasoning processes often suffer from knowledge insufficiency, leading to frequent uncertainties and potential errors. To address this limitation, we introduce \textbf{Search-o1}, a framework that enhances LRMs with an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module for refining retrieved documents. Search-o1 integrates an agentic search workflow into the reasoning process, enabling dynamic retrieval of external knowledge when LRMs encounter uncertain knowledge points. Additionally, due to the verbose nature of retrieved documents, we design a separate Reason-in-Documents module to deeply analyze the retrieved information before injecting it into the reasoning chain, minimizing noise and preserving coherent reasoning flow. Extensive experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1. This approach enhances the trustworthiness and applicability of LRMs in complex reasoning tasks, paving the way for more reliable and versatile intelligent systems. The code is available at \url{https://github.com/sunnynexus/Search-o1}.
Boosting Long-Context Management via Query-Guided Activation Refilling
Dec 18, 2024



Processing long contexts poses a significant challenge for large language models (LLMs) due to their inherent context-window limitations and the computational burden of extensive key-value (KV) activations, which severely impact efficiency. For information-seeking tasks, full context perception is often unnecessary, as a query's information needs can dynamically range from localized details to a global perspective, depending on its complexity. However, existing methods struggle to adapt effectively to these dynamic information needs. In the paper, we propose a method for processing long-context information-seeking tasks via query-guided Activation Refilling (ACRE). ACRE constructs a Bi-layer KV Cache for long contexts, where the layer-1 (L1) cache compactly captures global information, and the layer-2 (L2) cache provides detailed and localized information. ACRE establishes a proxying relationship between the two caches, allowing the input query to attend to the L1 cache and dynamically refill it with relevant entries from the L2 cache. This mechanism integrates global understanding with query-specific local details, thus improving answer decoding. Experiments on a variety of long-context information-seeking datasets demonstrate ACRE's effectiveness, achieving improvements in both performance and efficiency.
Boosting Long-Context Information Seeking via Query-Guided Activation Refilling
Dec 17, 2024Processing long contexts poses a significant challenge for large language models (LLMs) due to their inherent context-window limitations and the computational burden of extensive key-value (KV) activations, which severely impact efficiency. For information-seeking tasks, full context perception is often unnecessary, as a query's information needs can dynamically range from localized details to a global perspective, depending on its complexity. However, existing methods struggle to adapt effectively to these dynamic information needs. In the paper, we propose a method for processing long-context information-seeking tasks via query-guided Activation Refilling (ACRE). ACRE constructs a Bi-layer KV Cache for long contexts, where the layer-1 (L1) cache compactly captures global information, and the layer-2 (L2) cache provides detailed and localized information. ACRE establishes a proxying relationship between the two caches, allowing the input query to attend to the L1 cache and dynamically refill it with relevant entries from the L2 cache. This mechanism integrates global understanding with query-specific local details, thus improving answer decoding. Experiments on a variety of long-context information-seeking datasets demonstrate ACRE's effectiveness, achieving improvements in both performance and efficiency.
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Sep 24, 2024


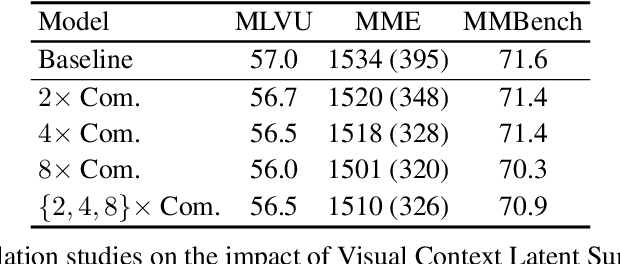
Although current Multi-modal Large Language Models (MLLMs) demonstrate promising results in video understanding, processing extremely long videos remains an ongoing challenge. Typically, MLLMs struggle with handling thousands of tokens that exceed the maximum context length of LLMs, and they experience reduced visual clarity due to token aggregation. Another challenge is the high computational cost stemming from the large number of video tokens. To tackle these issues, we propose Video-XL, an extra-long vision language model designed for efficient hour-scale video understanding. Specifically, we argue that LLMs can be adapted as effective visual condensers and introduce Visual Context Latent Summarization, which condenses visual contexts into highly compact forms. Extensive experiments demonstrate that our model achieves promising results on popular long video understanding benchmarks, despite being trained on limited image data. Moreover, Video-XL strikes a promising balance between efficiency and effectiveness, processing 1024 frames on a single 80GB GPU while achieving nearly 100\% accuracy in the Needle-in-a-Haystack evaluation. We envision Video-XL becoming a valuable tool for long video applications such as video summarization, surveillance anomaly detection, and Ad placement identification.
MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery
Sep 10, 2024


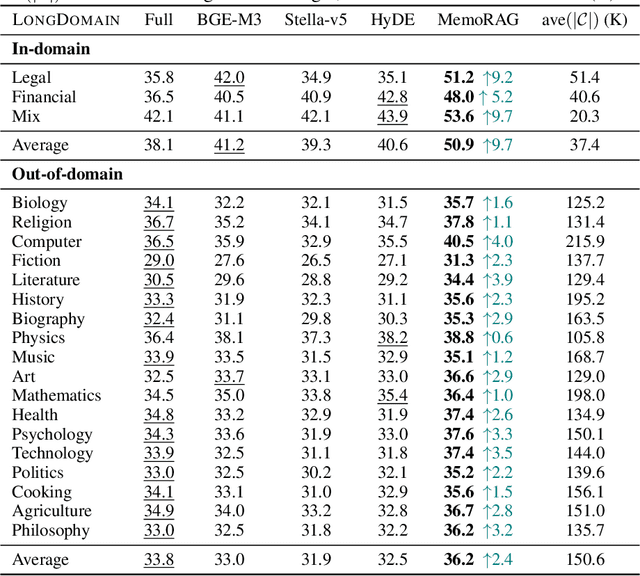
Retrieval-Augmented Generation (RAG) leverages retrieval tools to access external databases, thereby enhancing the generation quality of large language models (LLMs) through optimized context. However, the existing retrieval methods are constrained inherently, as they can only perform relevance matching between explicitly stated queries and well-formed knowledge, but unable to handle tasks involving ambiguous information needs or unstructured knowledge. Consequently, existing RAG systems are primarily effective for straightforward question-answering tasks. In this work, we propose MemoRAG, a novel retrieval-augmented generation paradigm empowered by long-term memory. MemoRAG adopts a dual-system architecture. On the one hand, it employs a light but long-range LLM to form the global memory of database. Once a task is presented, it generates draft answers, cluing the retrieval tools to locate useful information within the database. On the other hand, it leverages an expensive but expressive LLM, which generates the ultimate answer based on the retrieved information. Building on this general framework, we further optimize MemoRAG's performance by enhancing its cluing mechanism and memorization capacity. In our experiment, MemoRAG achieves superior performance across a variety of evaluation tasks, including both complex ones where conventional RAG fails and straightforward ones where RAG is commonly applied.
Compressing Lengthy Context With UltraGist
May 26, 2024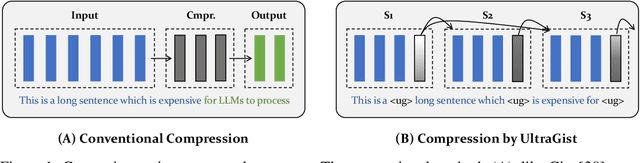
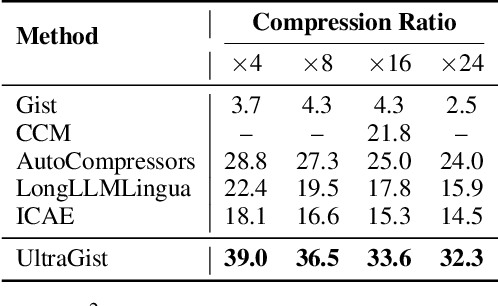
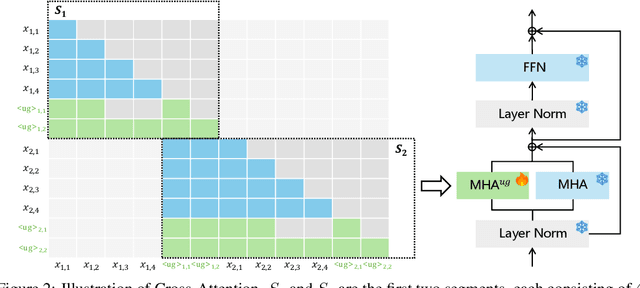
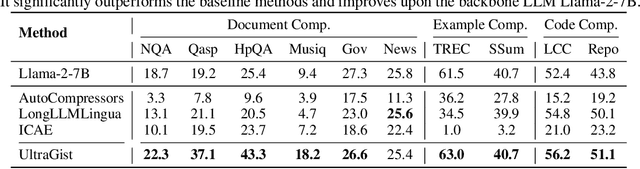
Compressing lengthy context is a critical but technically challenging problem. In this paper, we propose a new method called UltraGist, which is distinguished for its high-quality compression of lengthy context due to the innovative design of the compression and learning algorithm. UltraGist brings forth the following important benefits. Firstly, it notably contributes to the flexibility of compression, as it can be effectively learned to support a broad range of context lengths and compression ratios. Secondly, it helps to produce fine-grained compression for the lengthy context, where each small segment of the context is progressively processed on top of a tailored cross-attention mechanism. Thirdly, it makes the training process sample-efficient and thus maximizes the use of training data. Finally, it facilitates the efficient running of compression for dynamic context, as the compression result can be progressively generated and hence incrementally updated. UltraGist is evaluated on a wide variety of tasks associated with lengthy context, such as document QA and summarization, few-shot learning, multi-session conversation, et al. Whilst the existing methods fail to handle these challenging scenarios, our approach is able to preserve a near-lossless compression performance throughout all the evaluations. Our data, model, and code have been released at \url{https://github.com/namespace-Pt/UltraGist}.
Are Long-LLMs A Necessity For Long-Context Tasks?
May 24, 2024The learning and deployment of long-LLMs remains a challenging problem despite recent progresses. In this work, we argue that the long-LLMs are not a necessity to solve long-context tasks, as common long-context tasks are short-context solvable, i.e. they can be solved by purely working with oracle short-contexts within the long-context tasks' inputs. On top of this argument, we propose a framework called LC-Boost (Long-Context Bootstrapper), which enables a short-LLM to address the long-context tasks in a bootstrapping manner. In our framework, the short-LLM prompts itself to reason for two critical decisions: 1) how to access to the appropriate part of context within the input, 2) how to make effective use of the accessed context. By adaptively accessing and utilizing the context based on the presented tasks, LC-Boost can serve as a general framework to handle diversified long-context processing problems. We comprehensively evaluate different types of tasks from popular long-context benchmarks, where LC-Boost is able to achieve a substantially improved performance with a much smaller consumption of resource.
Extending Llama-3's Context Ten-Fold Overnight
Apr 30, 2024
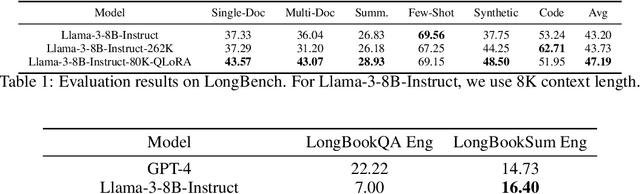
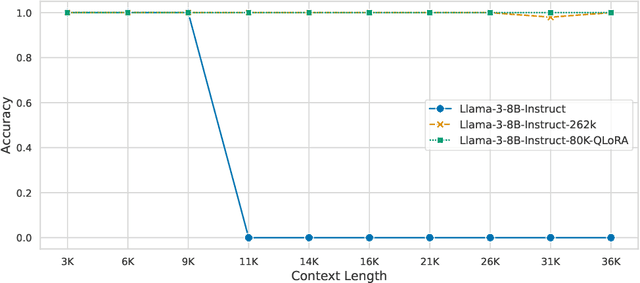
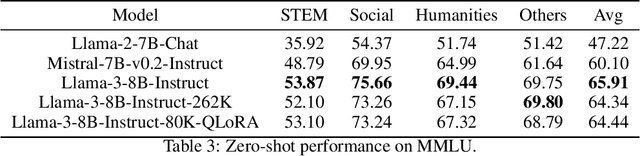
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: \url{https://github.com/FlagOpen/FlagEmbedding}.
From Matching to Generation: A Survey on Generative Information Retrieval
Apr 23, 2024



Information Retrieval (IR) systems are crucial tools for users to access information, widely applied in scenarios like search engines, question answering, and recommendation systems. Traditional IR methods, based on similarity matching to return ranked lists of documents, have been reliable means of information acquisition, dominating the IR field for years. With the advancement of pre-trained language models, generative information retrieval (GenIR) has emerged as a novel paradigm, gaining increasing attention in recent years. Currently, research in GenIR can be categorized into two aspects: generative document retrieval (GR) and reliable response generation. GR leverages the generative model's parameters for memorizing documents, enabling retrieval by directly generating relevant document identifiers without explicit indexing. Reliable response generation, on the other hand, employs language models to directly generate the information users seek, breaking the limitations of traditional IR in terms of document granularity and relevance matching, offering more flexibility, efficiency, and creativity, thus better meeting practical needs. This paper aims to systematically review the latest research progress in GenIR. We will summarize the advancements in GR regarding model training, document identifier, incremental learning, downstream tasks adaptation, multi-modal GR and generative recommendation, as well as progress in reliable response generation in aspects of internal knowledge memorization, external knowledge augmentation, generating response with citations and personal information assistant. We also review the evaluation, challenges and future prospects in GenIR systems. This review aims to offer a comprehensive reference for researchers in the GenIR field, encouraging further development in this area.