 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Paper and Code



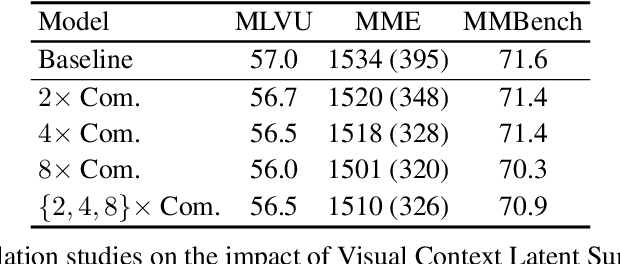
Although current Multi-modal Large Language Models (MLLMs) demonstrate promising results in video understanding, processing extremely long videos remains an ongoing challenge. Typically, MLLMs struggle with handling thousands of tokens that exceed the maximum context length of LLMs, and they experience reduced visual clarity due to token aggregation. Another challenge is the high computational cost stemming from the large number of video tokens. To tackle these issues, we propose Video-XL, an extra-long vision language model designed for efficient hour-scale video understanding. Specifically, we argue that LLMs can be adapted as effective visual condensers and introduce Visual Context Latent Summarization, which condenses visual contexts into highly compact forms. Extensive experiments demonstrate that our model achieves promising results on popular long video understanding benchmarks, despite being trained on limited image data. Moreover, Video-XL strikes a promising balance between efficiency and effectiveness, processing 1024 frames on a single 80GB GPU while achieving nearly 100\% accuracy in the Needle-in-a-Haystack evaluation. We envision Video-XL becoming a valuable tool for long video applications such as video summarization, surveillance anomaly detection, and Ad placement identification.