 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalOne: A Family of Foundation Models for Reliable Legal Reasoning
Feb 03, 2026While Large Language Models (LLMs) have demonstrated impressive general capabilities, their direct application in the legal domain is often hindered by a lack of precise domain knowledge and complexity of performing rigorous multi-step judicial reasoning. To address this gap, we present LegalOne, a family of foundational models specifically tailored for the Chinese legal domain. LegalOne is developed through a comprehensive three-phase pipeline designed to master legal reasoning. First, during mid-training phase, we propose Plasticity-Adjusted Sampling (PAS) to address the challenge of domain adaptation. This perplexity-based scheduler strikes a balance between the acquisition of new knowledge and the retention of original capabilities, effectively establishing a robust legal foundation. Second, during supervised fine-tuning, we employ Legal Agentic CoT Distillation (LEAD) to distill explicit reasoning from raw legal texts. Unlike naive distillation, LEAD utilizes an agentic workflow to convert complex judicial processes into structured reasoning trajectories, thereby enforcing factual grounding and logical rigor. Finally, we implement a Curriculum Reinforcement Learning (RL) strategy. Through a progressive reinforcement process spanning memorization, understanding, and reasoning, LegalOne evolves from simple pattern matching to autonomous and reliable legal reasoning. Experimental results demonstrate that LegalOne achieves state-of-the-art performance across a wide range of legal tasks, surpassing general-purpose LLMs with vastly larger parameter counts through enhanced knowledge density and efficiency. We publicly release the LegalOne weights and the LegalKit evaluation framework to advance the field of Legal AI, paving the way for deploying trustworthy and interpretable foundation models in high-stakes judicial applications.
Video-BrowseComp: Benchmarking Agentic Video Research on Open Web
Dec 28, 2025The evolution of autonomous agents is redefining information seeking, transitioning from passive retrieval to proactive, open-ended web research. However, while textual and static multimodal agents have seen rapid progress, a significant modality gap remains in processing the web's most dynamic modality: video. Existing video benchmarks predominantly focus on passive perception, feeding curated clips to models without requiring external retrieval. They fail to evaluate agentic video research, which necessitates actively interrogating video timelines, cross-referencing dispersed evidence, and verifying claims against the open web. To bridge this gap, we present \textbf{Video-BrowseComp}, a challenging benchmark comprising 210 questions tailored for open-web agentic video reasoning. Unlike prior benchmarks, Video-BrowseComp enforces a mandatory dependency on temporal visual evidence, ensuring that answers cannot be derived solely through text search but require navigating video timelines to verify external claims. Our evaluation of state-of-the-art models reveals a critical bottleneck: even advanced search-augmented models like GPT-5.1 (w/ Search) achieve only 15.24\% accuracy. Our analysis reveals that these models largely rely on textual proxies, excelling in metadata-rich domains (e.g., TV shows with plot summaries) but collapsing in metadata-sparse, dynamic environments (e.g., sports, gameplay) where visual grounding is essential. As the first open-web video research benchmark, Video-BrowseComp advances the field beyond passive perception toward proactive video reasoning.
Video-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification
Jun 24, 2025Multi-modal large language models (MLLMs) models have made significant progress in video understanding over the past few years. However, processing long video inputs remains a major challenge due to high memory and computational costs. This makes it difficult for current models to achieve both strong performance and high efficiency in long video understanding. To address this challenge, we propose Video-XL-2, a novel MLLM that delivers superior cost-effectiveness for long-video understanding based on task-aware KV sparsification. The proposed framework operates with two key steps: chunk-based pre-filling and bi-level key-value decoding. Chunk-based pre-filling divides the visual token sequence into chunks, applying full attention within each chunk and sparse attention across chunks. This significantly reduces computational and memory overhead. During decoding, bi-level key-value decoding selectively reloads either dense or sparse key-values for each chunk based on its relevance to the task. This approach further improves memory efficiency and enhances the model's ability to capture fine-grained information. Video-XL-2 achieves state-of-the-art performance on various long video understanding benchmarks, outperforming existing open-source lightweight models. It also demonstrates exceptional efficiency, capable of processing over 10,000 frames on a single NVIDIA A100 (80GB) GPU and thousands of frames in just a few seconds.
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Sep 24, 2024


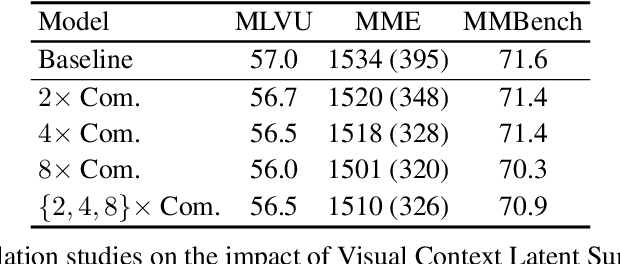
Although current Multi-modal Large Language Models (MLLMs) demonstrate promising results in video understanding, processing extremely long videos remains an ongoing challenge. Typically, MLLMs struggle with handling thousands of tokens that exceed the maximum context length of LLMs, and they experience reduced visual clarity due to token aggregation. Another challenge is the high computational cost stemming from the large number of video tokens. To tackle these issues, we propose Video-XL, an extra-long vision language model designed for efficient hour-scale video understanding. Specifically, we argue that LLMs can be adapted as effective visual condensers and introduce Visual Context Latent Summarization, which condenses visual contexts into highly compact forms. Extensive experiments demonstrate that our model achieves promising results on popular long video understanding benchmarks, despite being trained on limited image data. Moreover, Video-XL strikes a promising balance between efficiency and effectiveness, processing 1024 frames on a single 80GB GPU while achieving nearly 100\% accuracy in the Needle-in-a-Haystack evaluation. We envision Video-XL becoming a valuable tool for long video applications such as video summarization, surveillance anomaly detection, and Ad placement identification.
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Aug 23, 2024



Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.