 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepAgent: A General Reasoning Agent with Scalable Toolsets
Oct 24, 2025Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow predefined workflows, which limit autonomous and global task completion. In this paper, we introduce DeepAgent, an end-to-end deep reasoning agent that performs autonomous thinking, tool discovery, and action execution within a single, coherent reasoning process. To address the challenges of long-horizon interactions, particularly the context length explosion from multiple tool calls and the accumulation of interaction history, we introduce an autonomous memory folding mechanism that compresses past interactions into structured episodic, working, and tool memories, reducing error accumulation while preserving critical information. To teach general-purpose tool use efficiently and stably, we develop an end-to-end reinforcement learning strategy, namely ToolPO, that leverages LLM-simulated APIs and applies tool-call advantage attribution to assign fine-grained credit to the tool invocation tokens. Extensive experiments on eight benchmarks, including general tool-use tasks (ToolBench, API-Bank, TMDB, Spotify, ToolHop) and downstream applications (ALFWorld, WebShop, GAIA, HLE), demonstrate that DeepAgent consistently outperforms baselines across both labeled-tool and open-set tool retrieval scenarios. This work takes a step toward more general and capable agents for real-world applications. The code and demo are available at https://github.com/RUC-NLPIR/DeepAgent.
Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search
Jul 03, 2025Complex information needs in real-world search scenarios demand deep reasoning and knowledge synthesis across diverse sources, which traditional retrieval-augmented generation (RAG) pipelines struggle to address effectively. Current reasoning-based approaches suffer from a fundamental limitation: they use a single model to handle both high-level planning and detailed execution, leading to inefficient reasoning and limited scalability. In this paper, we introduce HiRA, a hierarchical framework that separates strategic planning from specialized execution. Our approach decomposes complex search tasks into focused subtasks, assigns each subtask to domain-specific agents equipped with external tools and reasoning capabilities, and coordinates the results through a structured integration mechanism. This separation prevents execution details from disrupting high-level reasoning while enabling the system to leverage specialized expertise for different types of information processing. Experiments on four complex, cross-modal deep search benchmarks demonstrate that HiRA significantly outperforms state-of-the-art RAG and agent-based systems. Our results show improvements in both answer quality and system efficiency, highlighting the effectiveness of decoupled planning and execution for multi-step information seeking tasks. Our code is available at https://github.com/ignorejjj/HiRA.
Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning
May 22, 2025Recently, large language models (LLMs) have shown remarkable reasoning capabilities via large-scale reinforcement learning (RL). However, leveraging the RL algorithm to empower effective multi-tool collaborative reasoning in LLMs remains an open challenge. In this paper, we introduce Tool-Star, an RL-based framework designed to empower LLMs to autonomously invoke multiple external tools during stepwise reasoning. Tool-Star integrates six types of tools and incorporates systematic designs in both data synthesis and training. To address the scarcity of tool-use data, we propose a general tool-integrated reasoning data synthesis pipeline, which combines tool-integrated prompting with hint-based sampling to automatically and scalably generate tool-use trajectories. A subsequent quality normalization and difficulty-aware classification process filters out low-quality samples and organizes the dataset from easy to hard. Furthermore, we propose a two-stage training framework to enhance multi-tool collaborative reasoning by: (1) cold-start fine-tuning, which guides LLMs to explore reasoning patterns via tool-invocation feedback; and (2) a multi-tool self-critic RL algorithm with hierarchical reward design, which reinforces reward understanding and promotes effective tool collaboration. Experimental analyses on over 10 challenging reasoning benchmarks highlight the effectiveness and efficiency of Tool-Star. The code is available at https://github.com/dongguanting/Tool-Star.
Single LLM, Multiple Roles: A Unified Retrieval-Augmented Generation Framework Using Role-Specific Token Optimization
May 21, 2025Existing studies have optimized retrieval-augmented generation (RAG) across various sub-tasks, such as query understanding and retrieval refinement, but integrating these optimizations into a unified framework remains challenging. To tackle this problem, this work proposes RoleRAG, a unified RAG framework that achieves efficient multi-task processing through role-specific token optimization. RoleRAG comprises six modules, each handling a specific sub-task within the RAG process. Additionally, we introduce a query graph to represent the decomposition of the query, which can be dynamically resolved according to the decomposing state. All modules are driven by the same underlying LLM, distinguished by task-specific role tokens that are individually optimized. This design allows RoleRAG to dynamically activate different modules within a single LLM instance, thereby streamlining deployment and reducing resource consumption. Experimental results on five open-domain question-answering datasets demonstrate the effectiveness, generalizability, and flexibility of our framework.
Neuro-Symbolic Query Compiler
May 17, 2025Precise recognition of search intent in Retrieval-Augmented Generation (RAG) systems remains a challenging goal, especially under resource constraints and for complex queries with nested structures and dependencies. This paper presents QCompiler, a neuro-symbolic framework inspired by linguistic grammar rules and compiler design, to bridge this gap. It theoretically designs a minimal yet sufficient Backus-Naur Form (BNF) grammar $G[q]$ to formalize complex queries. Unlike previous methods, this grammar maintains completeness while minimizing redundancy. Based on this, QCompiler includes a Query Expression Translator, a Lexical Syntax Parser, and a Recursive Descent Processor to compile queries into Abstract Syntax Trees (ASTs) for execution. The atomicity of the sub-queries in the leaf nodes ensures more precise document retrieval and response generation, significantly improving the RAG system's ability to address complex queries.
Hierarchical Document Refinement for Long-context Retrieval-augmented Generation
May 15, 2025Real-world RAG applications often encounter long-context input scenarios, where redundant information and noise results in higher inference costs and reduced performance. To address these challenges, we propose LongRefiner, an efficient plug-and-play refiner that leverages the inherent structural characteristics of long documents. LongRefiner employs dual-level query analysis, hierarchical document structuring, and adaptive refinement through multi-task learning on a single foundation model. Experiments on seven QA datasets demonstrate that LongRefiner achieves competitive performance in various scenarios while using 10x fewer computational costs and latency compared to the best baseline. Further analysis validates that LongRefiner is scalable, efficient, and effective, providing practical insights for real-world long-text RAG applications. Our code is available at https://github.com/ignorejjj/LongRefiner.
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Apr 30, 2025Large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, demonstrate impressive long-horizon reasoning capabilities. However, their reliance on static internal knowledge limits their performance on complex, knowledge-intensive tasks and hinders their ability to produce comprehensive research reports requiring synthesis of diverse web information. To address this, we propose \textbf{WebThinker}, a deep research agent that empowers LRMs to autonomously search the web, navigate web pages, and draft research reports during the reasoning process. WebThinker integrates a \textbf{Deep Web Explorer} module, enabling LRMs to dynamically search, navigate, and extract information from the web when encountering knowledge gaps. It also employs an \textbf{Autonomous Think-Search-and-Draft strategy}, allowing the model to seamlessly interleave reasoning, information gathering, and report writing in real time. To further enhance research tool utilization, we introduce an \textbf{RL-based training strategy} via iterative online Direct Preference Optimization (DPO). Extensive experiments on complex reasoning benchmarks (GPQA, GAIA, WebWalkerQA, HLE) and scientific report generation tasks (Glaive) demonstrate that WebThinker significantly outperforms existing methods and strong proprietary systems. Our approach enhances LRM reliability and applicability in complex scenarios, paving the way for more capable and versatile deep research systems. The code is available at https://github.com/RUC-NLPIR/WebThinker.
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Jan 09, 2025



Large reasoning models (LRMs) like OpenAI-o1 have demonstrated impressive long stepwise reasoning capabilities through large-scale reinforcement learning. However, their extended reasoning processes often suffer from knowledge insufficiency, leading to frequent uncertainties and potential errors. To address this limitation, we introduce \textbf{Search-o1}, a framework that enhances LRMs with an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module for refining retrieved documents. Search-o1 integrates an agentic search workflow into the reasoning process, enabling dynamic retrieval of external knowledge when LRMs encounter uncertain knowledge points. Additionally, due to the verbose nature of retrieved documents, we design a separate Reason-in-Documents module to deeply analyze the retrieved information before injecting it into the reasoning chain, minimizing noise and preserving coherent reasoning flow. Extensive experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1. This approach enhances the trustworthiness and applicability of LRMs in complex reasoning tasks, paving the way for more reliable and versatile intelligent systems. The code is available at \url{https://github.com/sunnynexus/Search-o1}.
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
Dec 16, 2024



Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation. To address these issues, we propose \textbf{RetroLLM}, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding. Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy. Extensive experiments on five open-domain QA datasets demonstrate RetroLLM's superior performance across both in-domain and out-of-domain tasks. The code is available at \url{https://github.com/sunnynexus/RetroLLM}.
Trustworthiness in Retrieval-Augmented Generation Systems: A Survey
Sep 16, 2024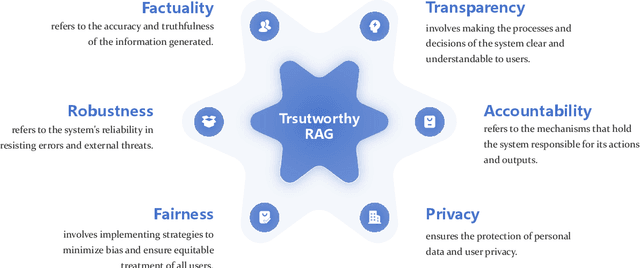
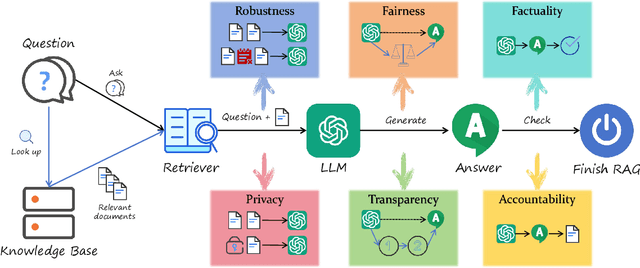
Retrieval-Augmented Generation (RAG) has quickly grown into a pivotal paradigm in the development of Large Language Models (LLMs). While much of the current research in this field focuses on performance optimization, particularly in terms of accuracy and efficiency, the trustworthiness of RAG systems remains an area still under exploration. From a positive perspective, RAG systems are promising to enhance LLMs by providing them with useful and up-to-date knowledge from vast external databases, thereby mitigating the long-standing problem of hallucination. While from a negative perspective, RAG systems are at the risk of generating undesirable contents if the retrieved information is either inappropriate or poorly utilized. To address these concerns, we propose a unified framework that assesses the trustworthiness of RAG systems across six key dimensions: factuality, robustness, fairness, transparency, accountability, and privacy. Within this framework, we thoroughly review the existing literature on each dimension. Additionally, we create the evaluation benchmark regarding the six dimensions and conduct comprehensive evaluations for a variety of proprietary and open-source models. Finally, we identify the potential challenges for future research based on our investigation results. Through this work, we aim to lay a structured foundation for future investigations and provide practical insights for enhancing the trustworthiness of RAG systems in real-world applications.