 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM-Cocktail: Resilient Tuning of Language Models via Model Merging
Paper and Code
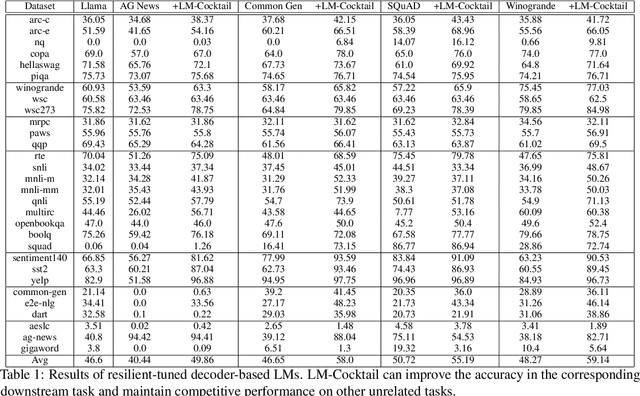
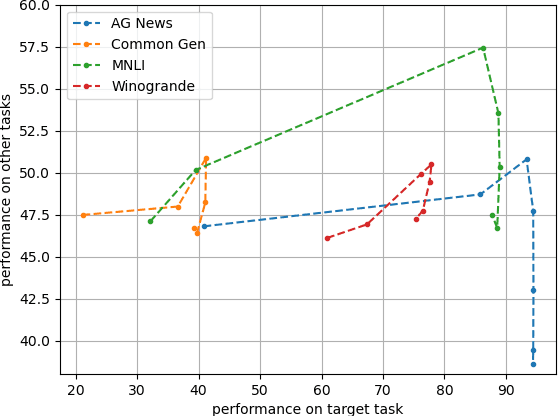
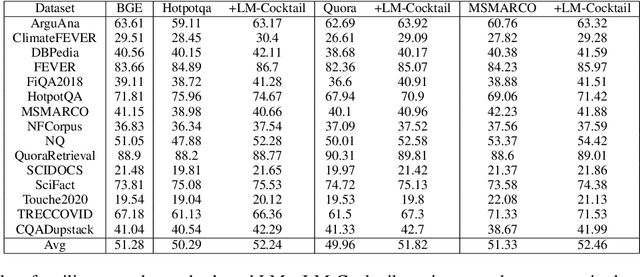
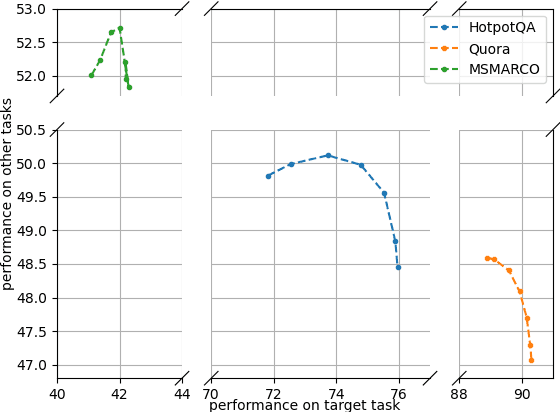
The pre-trained language models are continually fine-tuned to better support downstream applications. However, this operation may result in significant performance degeneration on general tasks beyond the targeted domain. To overcome this problem, we propose LM-Cocktail which enables the fine-tuned model to stay resilient in general perspectives. Our method is conducted in the form of model merging, where the fine-tuned language model is merged with the pre-trained base model or the peer models from other domains through weighted average. Despite simplicity, LM-Cocktail is surprisingly effective: the resulted model is able to achieve a strong empirical performance in the whole scope of general tasks while preserving a superior capacity in its targeted domain. We conduct comprehensive experiments with LLama and BGE model on popular benchmarks, including FLAN, MMLU, MTEB, whose results validate the efficacy of our proposed method. The code and checkpoints are available at https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail.