 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection
Mar 04, 2026Constructing computer-aided design (CAD) models is labor-intensive but essential for engineering and manufacturing. Recent advances in Large Language Models (LLMs) have inspired the LLM-based CAD generation by representing CAD as command sequences. But these methods struggle in practical scenarios because command sequence representation does not support entity selection (e.g. faces or edges), limiting its ability to support complex editing operations such as chamfer or fillet. Further, the discretization of a continuous variable during sketch and extrude operations may result in topological errors. To address these limitations, we present Pointer-CAD, a novel LLM-based CAD generation framework that leverages a pointer-based command sequence representation to explicitly incorporate the geometric information of B-rep models into sequential modeling. In particular, Pointer-CAD decomposes CAD model generation into steps, conditioning the generation of each subsequent step on both the textual description and the B-rep generated from previous steps. Whenever an operation requires the selection of a specific geometric entity, the LLM predicts a Pointer that selects the most feature-consistent candidate from the available set. Such a selection operation also reduces the quantization error in the command sequence-based representation. To support the training of Pointer-CAD, we develop a data annotation pipeline that produces expert-level natural language descriptions and apply it to build a dataset of approximately 575K CAD models. Extensive experimental results demonstrate that Pointer-CAD effectively supports the generation of complex geometric structures and reduces segmentation error to an extremely low level, achieving a significant improvement over prior command sequence methods, thereby significantly mitigating the topological inaccuracies introduced by quantization error.
Dropping Anchor and Spherical Harmonics for Sparse-view Gaussian Splatting
Feb 24, 2026Recent 3D Gaussian Splatting (3DGS) Dropout methods address overfitting under sparse-view conditions by randomly nullifying Gaussian opacities. However, we identify a neighbor compensation effect in these approaches: dropped Gaussians are often compensated by their neighbors, weakening the intended regularization. Moreover, these methods overlook the contribution of high-degree spherical harmonic coefficients (SH) to overfitting. To address these issues, we propose DropAnSH-GS, a novel anchor-based Dropout strategy. Rather than dropping Gaussians independently, our method randomly selects certain Gaussians as anchors and simultaneously removes their spatial neighbors. This effectively disrupts local redundancies near anchors and encourages the model to learn more robust, globally informed representations. Furthermore, we extend the Dropout to color attributes by randomly dropping higher-degree SH to concentrate appearance information in lower-degree SH. This strategy further mitigates overfitting and enables flexible post-training model compression via SH truncation. Experimental results demonstrate that DropAnSH-GS substantially outperforms existing Dropout methods with negligible computational overhead, and can be readily integrated into various 3DGS variants to enhance their performances. Project Website: https://sk-fun.fun/DropAnSH-GS
WaterClear-GS: Optical-Aware Gaussian Splatting for Underwater Reconstruction and Restoration
Jan 27, 2026Underwater 3D reconstruction and appearance restoration are hindered by the complex optical properties of water, such as wavelength-dependent attenuation and scattering. Existing Neural Radiance Fields (NeRF)-based methods struggle with slow rendering speeds and suboptimal color restoration, while 3D Gaussian Splatting (3DGS) inherently lacks the capability to model complex volumetric scattering effects. To address these issues, we introduce WaterClear-GS, the first pure 3DGS-based framework that explicitly integrates underwater optical properties of local attenuation and scattering into Gaussian primitives, eliminating the need for an auxiliary medium network. Our method employs a dual-branch optimization strategy to ensure underwater photometric consistency while naturally recovering water-free appearances. This strategy is enhanced by depth-guided geometry regularization and perception-driven image loss, together with exposure constraints, spatially-adaptive regularization, and physically guided spectral regularization, which collectively enforce local 3D coherence and maintain natural visual perception. Experiments on standard benchmarks and our newly collected dataset demonstrate that WaterClear-GS achieves outstanding performance on both novel view synthesis (NVS) and underwater image restoration (UIR) tasks, while maintaining real-time rendering. The code will be available at https://buaaxrzhang.github.io/WaterClear-GS/.
Graph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
Multi-periodicity dependency Transformer based on spectrum offset for radio frequency fingerprint identification
Aug 14, 2024



Radio Frequency Fingerprint Identification (RFFI) has emerged as a pivotal task for reliable device authentication. Despite advancements in RFFI methods, background noise and intentional modulation features result in weak energy and subtle differences in the RFF features. These challenges diminish the capability of RFFI methods in feature representation, complicating the effective identification of device identities. This paper proposes a novel Multi-Periodicity Dependency Transformer (MPDFormer) to address these challenges. The MPDFormer employs a spectrum offset-based periodic embedding representation to augment the discrepency of intrinsic features. We delve into the intricacies of the periodicity-dependency attention mechanism, integrating both inter-period and intra-period attention mechanisms. This mechanism facilitates the extraction of both long and short-range periodicity-dependency features , accentuating the feature distinction whilst concurrently attenuating the perturbations caused by background noise and weak-periodicity features. Empirical results demonstrate MPDFormer's superiority over established baseline methods, achieving a 0.07s inference time on NVIDIA Jetson Orin NX.
Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts
Jul 10, 2024



Recent work on image content manipulation based on vision-language pre-training models has been effectively extended to text-driven 3D scene editing. However, existing schemes for 3D scene editing still exhibit certain shortcomings, hindering their further interactive design. Such schemes typically adhere to fixed input patterns, limiting users' flexibility in text input. Moreover, their editing capabilities are constrained by a single or a few 2D visual models and require intricate pipeline design to integrate these models into 3D reconstruction processes. To address the aforementioned issues, we propose a dialogue-based 3D scene editing approach, termed CE3D, which is centered around a large language model that allows for arbitrary textual input from users and interprets their intentions, subsequently facilitating the autonomous invocation of the corresponding visual expert models. Furthermore, we design a scheme utilizing Hash-Atlas to represent 3D scene views, which transfers the editing of 3D scenes onto 2D atlas images. This design achieves complete decoupling between the 2D editing and 3D reconstruction processes, enabling CE3D to flexibly integrate a wide range of existing 2D or 3D visual models without necessitating intricate fusion designs. Experimental results demonstrate that CE3D effectively integrates multiple visual models to achieve diverse editing visual effects, possessing strong scene comprehension and multi-round dialog capabilities. The code is available at https://sk-fun.fun/CE3D.
Text-driven Editing of 3D Scenes without Retraining
Sep 10, 2023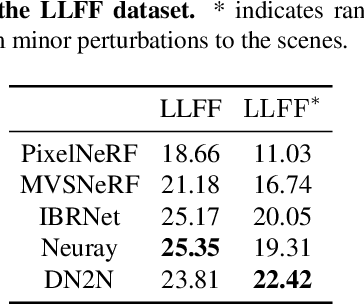



Numerous diffusion models have recently been applied to image synthesis and editing. However, editing 3D scenes is still in its early stages. It poses various challenges, such as the requirement to design specific methods for different editing types, retraining new models for various 3D scenes, and the absence of convenient human interaction during editing. To tackle these issues, we introduce a text-driven editing method, termed DN2N, which allows for the direct acquisition of a NeRF model with universal editing capabilities, eliminating the requirement for retraining. Our method employs off-the-shelf text-based editing models of 2D images to modify the 3D scene images, followed by a filtering process to discard poorly edited images that disrupt 3D consistency. We then consider the remaining inconsistency as a problem of removing noise perturbation, which can be solved by generating training data with similar perturbation characteristics for training. We further propose cross-view regularization terms to help the generalized NeRF model mitigate these perturbations. Our text-driven method allows users to edit a 3D scene with their desired description, which is more friendly, intuitive, and practical than prior works. Empirical results show that our method achieves multiple editing types, including but not limited to appearance editing, weather transition, material changing, and style transfer. Most importantly, our method generalizes well with editing abilities shared among a set of model parameters without requiring a customized editing model for some specific scenes, thus inferring novel views with editing effects directly from user input. The project website is available at http://sk-fun.fun/DN2N
PVD-AL: Progressive Volume Distillation with Active Learning for Efficient Conversion Between Different NeRF Architectures
Apr 08, 2023Neural Radiance Fields (NeRF) have been widely adopted as practical and versatile representations for 3D scenes, facilitating various downstream tasks. However, different architectures, including plain Multi-Layer Perceptron (MLP), Tensors, low-rank Tensors, Hashtables, and their compositions, have their trade-offs. For instance, Hashtables-based representations allow for faster rendering but lack clear geometric meaning, making spatial-relation-aware editing challenging. To address this limitation and maximize the potential of each architecture, we propose Progressive Volume Distillation with Active Learning (PVD-AL), a systematic distillation method that enables any-to-any conversions between different architectures. PVD-AL decomposes each structure into two parts and progressively performs distillation from shallower to deeper volume representation, leveraging effective information retrieved from the rendering process. Additionally, a Three-Levels of active learning technique provides continuous feedback during the distillation process, resulting in high-performance results. Empirical evidence is presented to validate our method on multiple benchmark datasets. For example, PVD-AL can distill an MLP-based model from a Hashtables-based model at a 10~20X faster speed and 0.8dB~2dB higher PSNR than training the NeRF model from scratch. Moreover, PVD-AL permits the fusion of diverse features among distinct structures, enabling models with multiple editing properties and providing a more efficient model to meet real-time requirements. Project website:http://sk-fun.fun/PVD-AL.
Video Pose Track with Graph-Guided Sparse Motion Estimation
Mar 04, 2023In this paper, we propose a novel framework for multi-person pose estimation and tracking under occlusions and motion blurs. Specifically, the consistency in graph structures from consecutive frames is improved by concentrating on visible body joints and estimating the motion vectors of sparse key-points surrounding visible joints. The proposed framework involves three components: (i) A Sparse Key-point Flow Estimating Module (SKFEM) for sampling key-points from around body joints and estimating the motion vectors of key-points which contribute to the refinement of body joint locations and fine-tuning of pose estimators; (ii) A Hierarchical Graph Distance Minimizing Module (HGMM) for evaluating the visibility scores of nodes from hierarchical graphs with the visibility score of a node determining the number of samples around that node; and (iii) The combination of multiple historical frames for matching identities. Graph matching with HGMM facilitates more accurate tracking even under partial occlusions. The proposed approach not only achieves state-of-the-art performance on the PoseTrack dataset but also contributes to significant improvements in human-related anomaly detection. Besides a higher accuracy, the proposed SKFEM also shows a much higher efficiency than dense optical flow estimation.
Towards Accurate Binary Neural Networks via Modeling Contextual Dependencies
Sep 03, 2022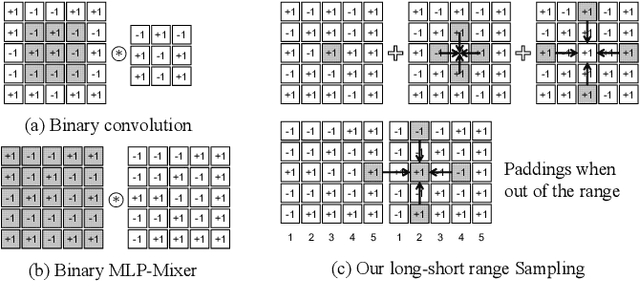
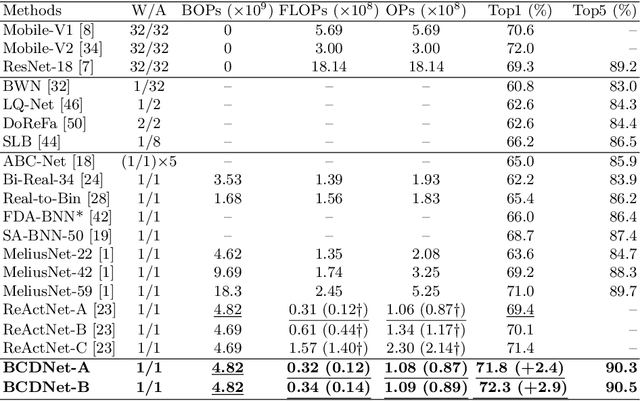
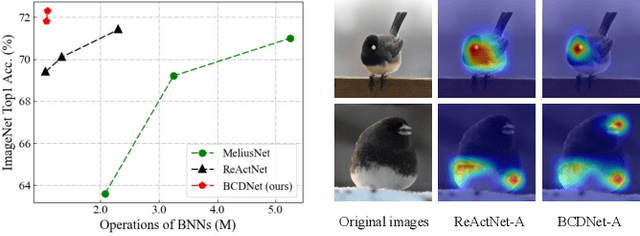
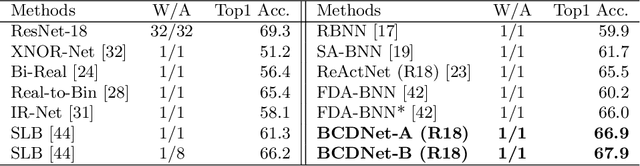
Existing Binary Neural Networks (BNNs) mainly operate on local convolutions with binarization function. However, such simple bit operations lack the ability of modeling contextual dependencies, which is critical for learning discriminative deep representations in vision models. In this work, we tackle this issue by presenting new designs of binary neural modules, which enables BNNs to learn effective contextual dependencies. First, we propose a binary multi-layer perceptron (MLP) block as an alternative to binary convolution blocks to directly model contextual dependencies. Both short-range and long-range feature dependencies are modeled by binary MLPs, where the former provides local inductive bias and the latter breaks limited receptive field in binary convolutions. Second, to improve the robustness of binary models with contextual dependencies, we compute the contextual dynamic embeddings to determine the binarization thresholds in general binary convolutional blocks. Armed with our binary MLP blocks and improved binary convolution, we build the BNNs with explicit Contextual Dependency modeling, termed as BCDNet. On the standard ImageNet-1K classification benchmark, the BCDNet achieves 72.3% Top-1 accuracy and outperforms leading binary methods by a large margin. In particular, the proposed BCDNet exceeds the state-of-the-art ReActNet-A by 2.9% Top-1 accuracy with similar operations. Our code is available at https://github.com/Sense-GVT/BCDN