 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Foresight: Enhancing Neural Routing Policy via Multi-Node Lookahead Prediction
May 19, 2026Neural policies have shown promise in solving vehicle routing problems due to their reduced reliance on handcrafted heuristics. However, current training paradigms suffer from a fundamental limitation: they primarily focus on next-node prediction for solution construction, resulting in myopic decision-making that undermines long-horizon planning capacity. To this end, we introduce Multi-node Lookahead Prediction (MnLP), a novel training strategy that extends the supervised learning paradigm to predict multiple future nodes simultaneously. We incorporate causal and discardable MnLP modules that operate exclusively during training, facilitating models to anticipate multi-step decisions while preserving inference-time efficiency. By incorporating multi-depth auxiliary supervision into the loss function, MnLP equips neural policies with the ability of long-range contextual understanding. Experimentally, MnLP outperforms existing training methods, improving the generalization capability of neural policies across various problem sizes, distributions, and real-world benchmarks. Moreover, MnLP can be seamlessly integrated into diverse neural architectures without introducing additional inference overhead.
Reasoning in a Combinatorial and Constrained World: Benchmarking LLMs on Natural-Language Combinatorial Optimization
Feb 02, 2026While large language models (LLMs) have shown strong performance in math and logic reasoning, their ability to handle combinatorial optimization (CO) -- searching high-dimensional solution spaces under hard constraints -- remains underexplored. To bridge the gap, we introduce NLCO, a \textbf{N}atural \textbf{L}anguage \textbf{C}ombinatorial \textbf{O}ptimization benchmark that evaluates LLMs on end-to-end CO reasoning: given a language-described decision-making scenario, the model must output a discrete solution without writing code or calling external solvers. NLCO covers 43 CO problems and is organized using a four-layer taxonomy of variable types, constraint families, global patterns, and objective classes, enabling fine-grained evaluation. We provide solver-annotated solutions and comprehensively evaluate LLMs by feasibility, solution optimality, and reasoning efficiency. Experiments across a wide range of modern LLMs show that high-performing models achieve strong feasibility and solution quality on small instances, but both degrade as instance size grows, even if more tokens are used for reasoning. We also observe systematic effects across the taxonomy: set-based tasks are relatively easy, whereas graph-structured problems and bottleneck objectives lead to more frequent failures.
Empirical Bayesian Multi-Bandit Learning
Oct 30, 2025Multi-task learning in contextual bandits has attracted significant research interest due to its potential to enhance decision-making across multiple related tasks by leveraging shared structures and task-specific heterogeneity. In this article, we propose a novel hierarchical Bayesian framework for learning in various bandit instances. This framework captures both the heterogeneity and the correlations among different bandit instances through a hierarchical Bayesian model, enabling effective information sharing while accommodating instance-specific variations. Unlike previous methods that overlook the learning of the covariance structure across bandits, we introduce an empirical Bayesian approach to estimate the covariance matrix of the prior distribution.This enhances both the practicality and flexibility of learning across multi-bandits. Building on this approach, we develop two efficient algorithms: ebmTS (Empirical Bayesian Multi-Bandit Thompson Sampling) and ebmUCB (Empirical Bayesian Multi-Bandit Upper Confidence Bound), both of which incorporate the estimated prior into the decision-making process. We provide the frequentist regret upper bounds for the proposed algorithms, thereby filling a research gap in the field of multi-bandit problems. Extensive experiments on both synthetic and real-world datasets demonstrate the superior performance of our algorithms, particularly in complex environments. Our methods achieve lower cumulative regret compared to existing techniques, highlighting their effectiveness in balancing exploration and exploitation across multi-bandits.
Coalitions of AI-based Methods Predict 15-Year Risks of Breast Cancer Metastasis Using Real-World Clinical Data with AUC up to 0.9
Aug 29, 2024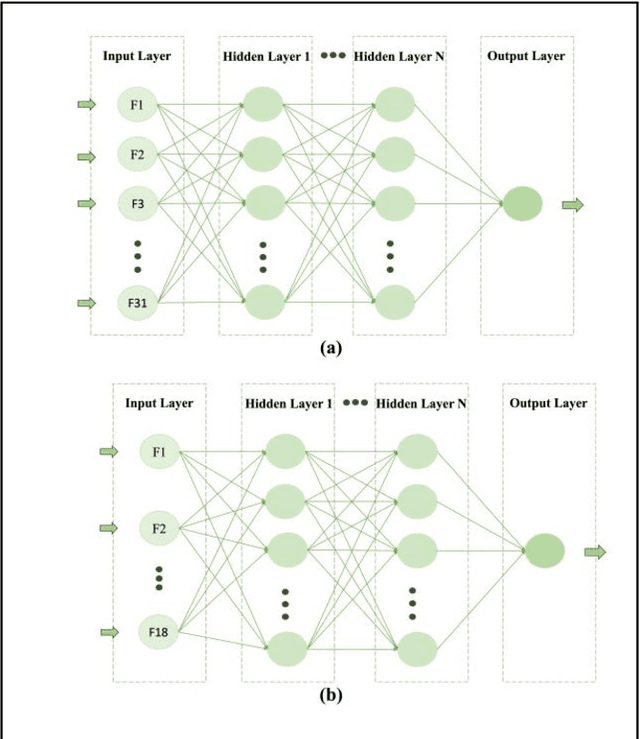
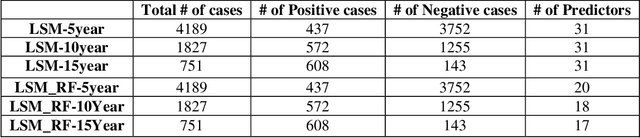
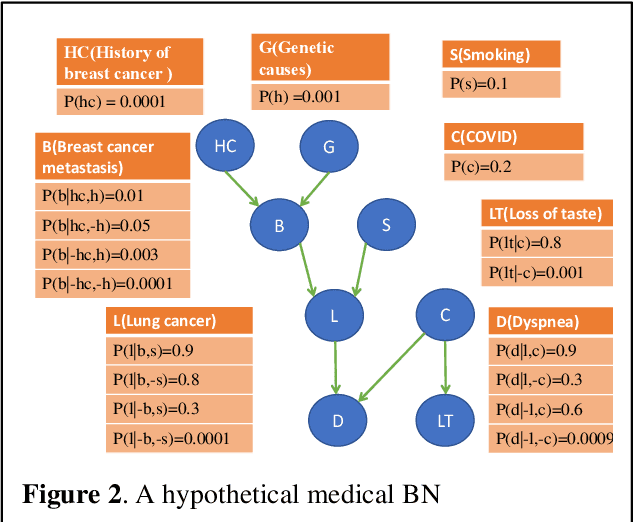
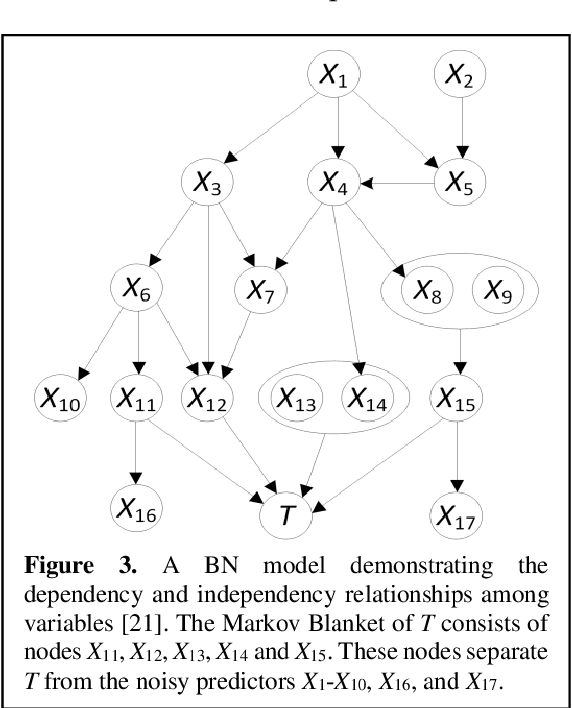
Breast cancer is one of the two cancers responsible for the most deaths in women, with about 42,000 deaths each year in the US. That there are over 300,000 breast cancers newly diagnosed each year suggests that only a fraction of the cancers result in mortality. Thus, most of the women undergo seemingly curative treatment for localized cancers, but a significant later succumb to metastatic disease for which current treatments are only temporizing for the vast majority. The current prognostic metrics are of little actionable value for 4 of the 5 women seemingly cured after local treatment, and many women are exposed to morbid and even mortal adjuvant therapies unnecessarily, with these adjuvant therapies reducing metastatic recurrence by only a third. Thus, there is a need for better prognostics to target aggressive treatment at those who are likely to relapse and spare those who were actually cured. While there is a plethora of molecular and tumor-marker assays in use and under-development to detect recurrence early, these are time consuming, expensive and still often un-validated as to actionable prognostic utility. A different approach would use large data techniques to determine clinical and histopathological parameters that would provide accurate prognostics using existing data. Herein, we report on machine learning, together with grid search and Bayesian Networks to develop algorithms that present a AUC of up to 0.9 in ROC analyses, using only extant data. Such algorithms could be rapidly translated to clinical management as they do not require testing beyond routine tumor evaluations.
Deep Learning to Predict Late-Onset Breast Cancer Metastasis: the Single Hyperparameter Grid Search (SHGS) Strategy for Meta Tuning Concerning Deep Feed-forward Neural Network
Aug 28, 2024

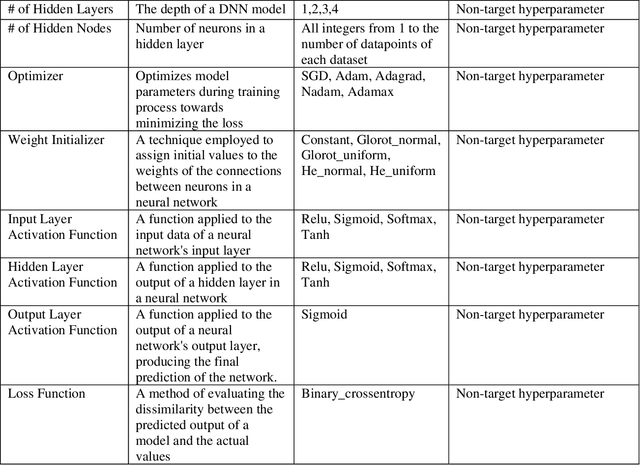
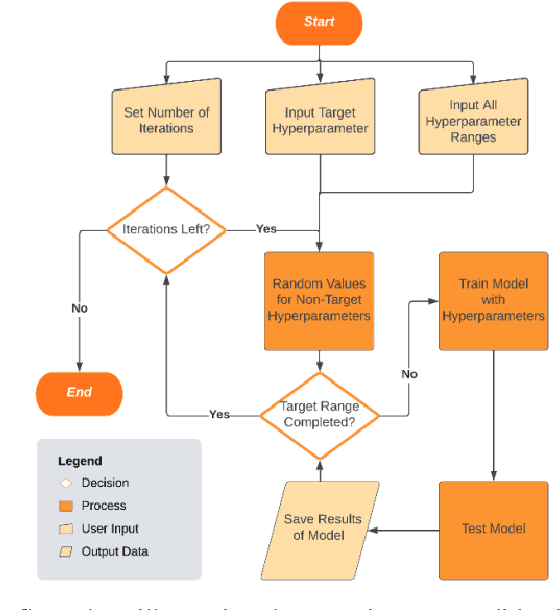
While machine learning has advanced in medicine, its widespread use in clinical applications, especially in predicting breast cancer metastasis, is still limited. We have been dedicated to constructing a DFNN model to predict breast cancer metastasis n years in advance. However, the challenge lies in efficiently identifying optimal hyperparameter values through grid search, given the constraints of time and resources. Issues such as the infinite possibilities for continuous hyperparameters like l1 and l2, as well as the time-consuming and costly process, further complicate the task. To address these challenges, we developed Single Hyperparameter Grid Search (SHGS) strategy, serving as a preselection method before grid search. Our experiments with SHGS applied to DFNN models for breast cancer metastasis prediction focus on analyzing eight target hyperparameters: epochs, batch size, dropout, L1, L2, learning rate, decay, and momentum. We created three figures, each depicting the experiment results obtained from three LSM-I-10-Plus-year datasets. These figures illustrate the relationship between model performance and the target hyperparameter values. For each hyperparameter, we analyzed whether changes in this hyperparameter would affect model performance, examined if there were specific patterns, and explored how to choose values for the particular hyperparameter. Our experimental findings reveal that the optimal value of a hyperparameter is not only dependent on the dataset but is also significantly influenced by the settings of other hyperparameters. Additionally, our experiments suggested some reduced range of values for a target hyperparameter, which may be helpful for low-budget grid search. This approach serves as a prior experience and foundation for subsequent use of grid search to enhance model performance.
UNCO: Towards Unifying Neural Combinatorial Optimization through Large Language Model
Aug 22, 2024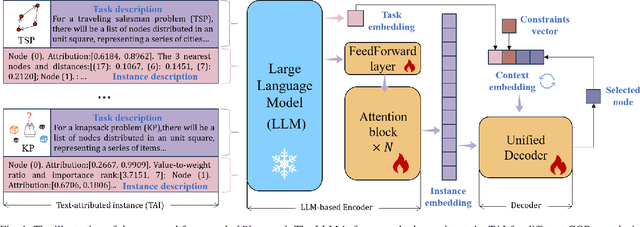
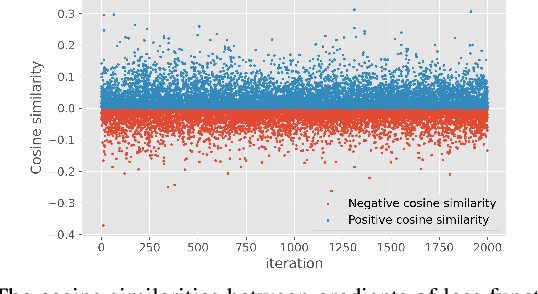
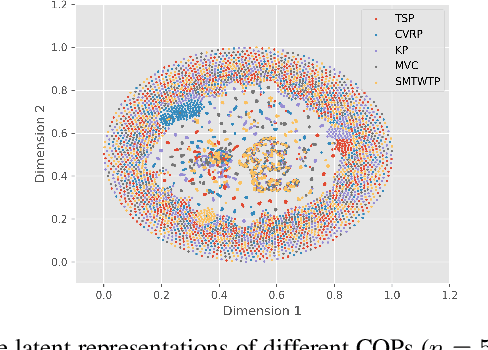
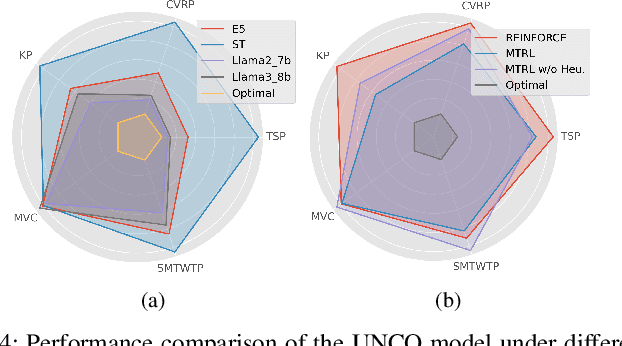
Recently, applying neural networks to address combinatorial optimization problems (COPs) has attracted considerable research attention. The prevailing methods always train deep models independently on specific problems, lacking a unified framework for concurrently tackling various COPs. To this end, we propose a unified neural combinatorial optimization (UNCO) framework to solve different types of COPs by a single model. Specifically, we use natural language to formulate text-attributed instances for different COPs and encode them in the same embedding space by the large language model (LLM). The obtained embeddings are further advanced by an encoder-decoder model without any problem-specific modules, thereby facilitating a unified process of solution construction. We further adopt the conflict gradients erasing reinforcement learning (CGERL) algorithm to train the UNCO model, delivering better performance across different COPs than vanilla multi-objective learning. Experiments show that the UNCO model can solve multiple COPs after a single-session training, and achieves satisfactory performance that is comparable to several traditional or learning-based baselines. Instead of pursuing the best performance for each COP, we explore the synergy between tasks and few-shot generalization based on LLM to inspire future work.
Deep Learning: a Heuristic Three-stage Mechanism for Grid Searches to Optimize the Future Risk Prediction of Breast Cancer Metastasis Using EHR-based Clinical Data
Aug 15, 2024A grid search, at the cost of training and testing a large number of models, is an effective way to optimize the prediction performance of deep learning models. A challenging task concerning grid search is the time management. Without a good time management scheme, a grid search can easily be set off as a mission that will not finish in our lifetime. In this study, we introduce a heuristic three-stage mechanism for managing the running time of low-budget grid searches, and the sweet-spot grid search (SSGS) and randomized grid search (RGS) strategies for improving model prediction performance, in predicting the 5-year, 10-year, and 15-year risk of breast cancer metastasis. We develop deep feedforward neural network (DFNN) models and optimize them through grid searches. We conduct eight cycles of grid searches by applying our three-stage mechanism and SSGS and RGS strategies. We conduct various SHAP analyses including unique ones that interpret the importance of the DFNN-model hyperparameters. Our results show that grid search can greatly improve model prediction. The grid searches we conducted improved the risk prediction of 5-year, 10-year, and 15-year breast cancer metastasis by 18.6%, 16.3%, and 17.3% respectively, over the average performance of all corresponding models we trained using the RGS strategy. We not only demonstrate best model performance but also characterize grid searches from various aspects such as their capabilities of discovering decent models and the unit grid search time. The three-stage mechanism worked effectively. It made our low-budget grid searches feasible and manageable, and in the meantime helped improve model prediction performance. Our SHAP analyses identified both clinical risk factors important for the prediction of future risk of breast cancer metastasis, and DFNN-model hyperparameters important to the prediction of performance scores.
Experimenting with an Evaluation Framework for Imbalanced Data Learning (EFIDL)
Jan 26, 2023

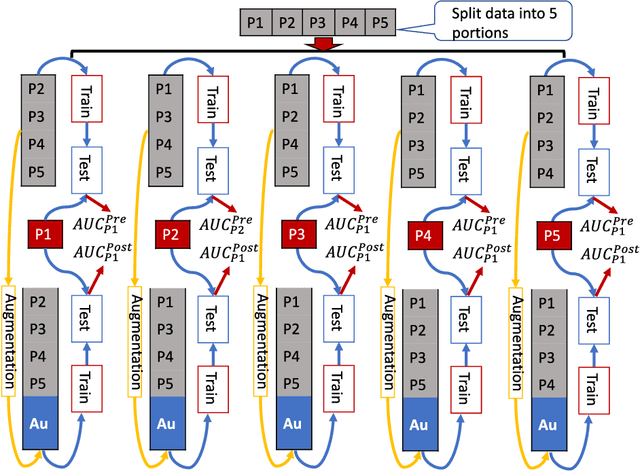

Introduction Data imbalance is one of the crucial issues in big data analysis with fewer labels. For example, in real-world healthcare data, spam detection labels, and financial fraud detection datasets. Many data balance methods were introduced to improve machine learning algorithms' performance. Research claims SMOTE and SMOTE-based data-augmentation (generate new data points) methods could improve algorithm performance. However, we found in many online tutorials, the valuation methods were applied based on synthesized datasets that introduced bias into the evaluation, and the performance got a false improvement. In this study, we proposed, a new evaluation framework for imbalanced data learning methods. We have experimented on five data balance methods and whether the performance of algorithms will improve or not. Methods We collected 8 imbalanced healthcare datasets with different imbalanced rates from different domains. Applied 6 data augmentation methods with 11 machine learning methods testing if the data augmentation will help with improving machine learning performance. We compared the traditional data augmentation evaluation methods with our proposed cross-validation evaluation framework Results Using traditional data augmentation evaluation meta hods will give a false impression of improving the performance. However, our proposed evaluation method shows data augmentation has limited ability to improve the results. Conclusion EFIDL is more suitable for evaluating the prediction performance of an ML method when data are augmented. Using an unsuitable evaluation framework will give false results. Future researchers should consider the evaluation framework we proposed when dealing with augmented datasets. Our experiments showed data augmentation does not help improve ML prediction performance.
iMedBot: A Web-based Intelligent Agent for Healthcare Related Prediction and Deep Learning
Oct 07, 2022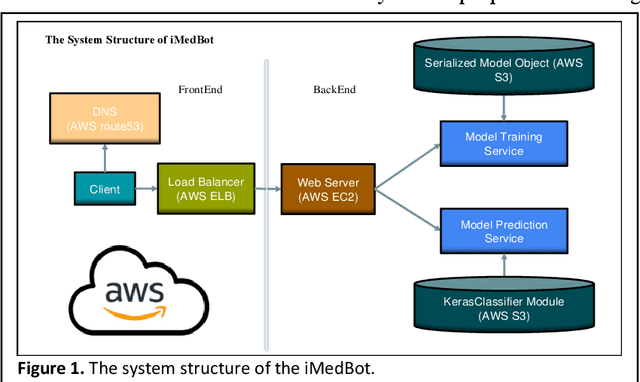
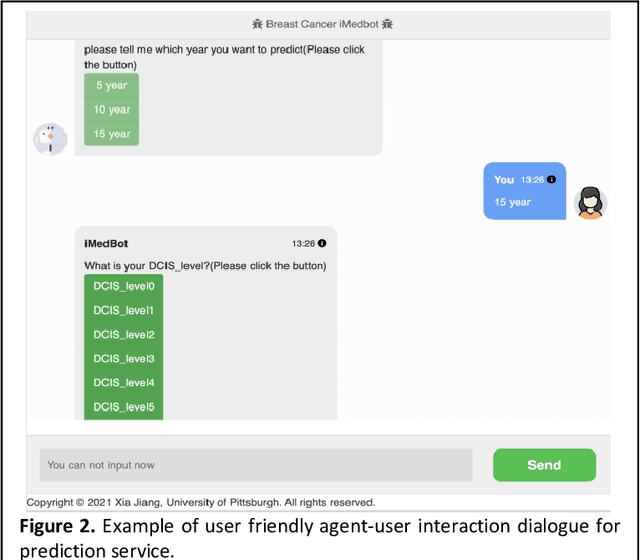
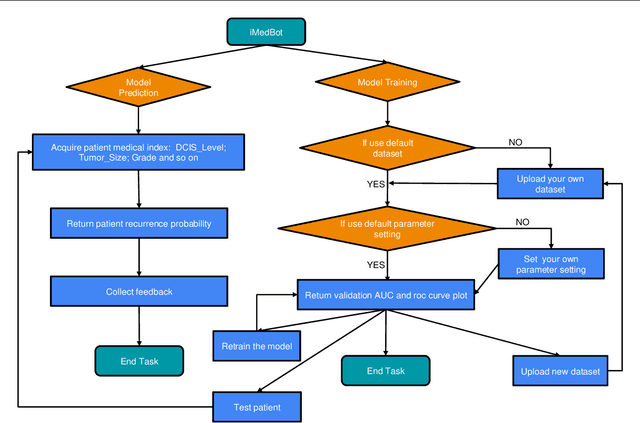
Background: Breast cancer is a multifactorial disease, genetic and environmental factors will affect its incidence probability. Breast cancer metastasis is one of the main cause of breast cancer related deaths reported by the American Cancer Society (ACS). Method: the iMedBot is a web application that we developed using the python Flask web framework and deployed on Amazon Web Services. It contains a frontend and a backend. The backend is supported by a python program we developed using the python Keras and scikit-learn packages, which can be used to learn deep feedforward neural network (DFNN) models. Result: the iMedBot can provide two main services: 1. it can predict 5-, 10-, or 15-year breast cancer metastasis based on a set of clinical information provided by a user. The prediction is done by using a set of DFNN models that were pretrained, and 2. It can train DFNN models for a user using user-provided dataset. The model trained will be evaluated using AUC and both the AUC value and the AUC ROC curve will be provided. Conclusion: The iMedBot web application provides a user-friendly interface for user-agent interaction in conducting personalized prediction and model training. It is an initial attempt to convert results of deep learning research into an online tool that may stir further research interests in this direction. Keywords: Deep learning, Breast Cancer, Web application, Model training.
Empirical Study of Overfitting in Deep FNN Prediction Models for Breast Cancer Metastasis
Aug 03, 2022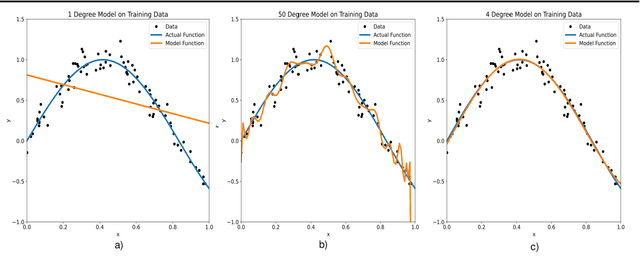
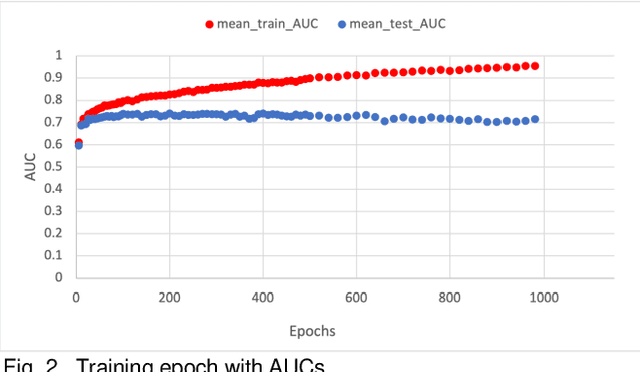
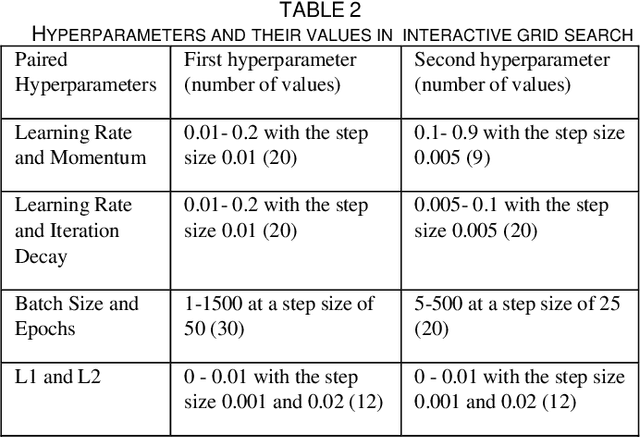
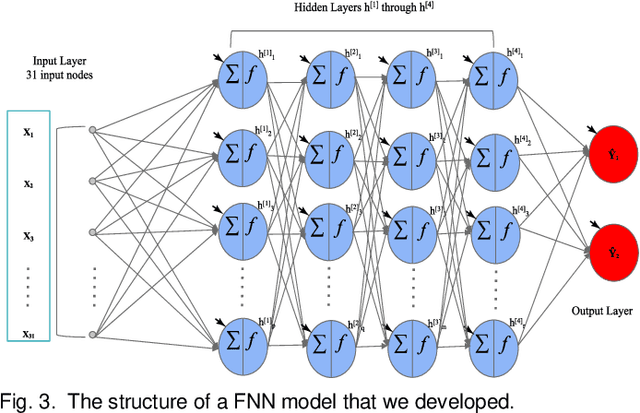
Overfitting is defined as the fact that the current model fits a specific data set perfectly, resulting in weakened generalization, and ultimately may affect the accuracy in predicting future data. In this research we used an EHR dataset concerning breast cancer metastasis to study overfitting of deep feedforward Neural Networks (FNNs) prediction models. We included 11 hyperparameters of the deep FNNs models and took an empirical approach to study how each of these hyperparameters was affecting both the prediction performance and overfitting when given a large range of values. We also studied how some of the interesting pairs of hyperparameters were interacting to influence the model performance and overfitting. The 11 hyperparameters we studied include activate function; weight initializer, number of hidden layers, learning rate, momentum, decay, dropout rate, batch size, epochs, L1, and L2. Our results show that most of the single hyperparameters are either negatively or positively corrected with model prediction performance and overfitting. In particular, we found that overfitting overall tends to negatively correlate with learning rate, decay, batch sides, and L2, but tends to positively correlate with momentum, epochs, and L1. According to our results, learning rate, decay, and batch size may have a more significant impact on both overfitting and prediction performance than most of the other hyperparameters, including L1, L2, and dropout rate, which were designed for minimizing overfitting. We also find some interesting interacting pairs of hyperparameters such as learning rate and momentum, learning rate and decay, and batch size and epochs. Keywords: Deep learning, overfitting, prediction, grid search, feedforward neural networks, breast cancer metastasis.