 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimenting with an Evaluation Framework for Imbalanced Data Learning (EFIDL)
Paper and Code
Jan 26, 2023

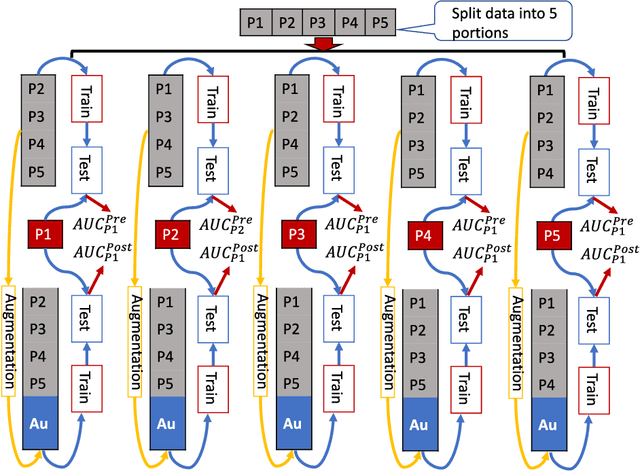

Introduction Data imbalance is one of the crucial issues in big data analysis with fewer labels. For example, in real-world healthcare data, spam detection labels, and financial fraud detection datasets. Many data balance methods were introduced to improve machine learning algorithms' performance. Research claims SMOTE and SMOTE-based data-augmentation (generate new data points) methods could improve algorithm performance. However, we found in many online tutorials, the valuation methods were applied based on synthesized datasets that introduced bias into the evaluation, and the performance got a false improvement. In this study, we proposed, a new evaluation framework for imbalanced data learning methods. We have experimented on five data balance methods and whether the performance of algorithms will improve or not. Methods We collected 8 imbalanced healthcare datasets with different imbalanced rates from different domains. Applied 6 data augmentation methods with 11 machine learning methods testing if the data augmentation will help with improving machine learning performance. We compared the traditional data augmentation evaluation methods with our proposed cross-validation evaluation framework Results Using traditional data augmentation evaluation meta hods will give a false impression of improving the performance. However, our proposed evaluation method shows data augmentation has limited ability to improve the results. Conclusion EFIDL is more suitable for evaluating the prediction performance of an ML method when data are augmented. Using an unsuitable evaluation framework will give false results. Future researchers should consider the evaluation framework we proposed when dealing with augmented datasets. Our experiments showed data augmentation does not help improve ML prediction performance.