 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-latency Space-time Supersampling for Real-time Rendering
Dec 18, 2023With the rise of real-time rendering and the evolution of display devices, there is a growing demand for post-processing methods that offer high-resolution content in a high frame rate. Existing techniques often suffer from quality and latency issues due to the disjointed treatment of frame supersampling and extrapolation. In this paper, we recognize the shared context and mechanisms between frame supersampling and extrapolation, and present a novel framework, Space-time Supersampling (STSS). By integrating them into a unified framework, STSS can improve the overall quality with lower latency. To implement an efficient architecture, we treat the aliasing and warping holes unified as reshading regions and put forth two key components to compensate the regions, namely Random Reshading Masking (RRM) and Efficient Reshading Module (ERM). Extensive experiments demonstrate that our approach achieves superior visual fidelity compared to state-of-the-art (SOTA) methods. Notably, the performance is achieved within only 4ms, saving up to 75\% of time against the conventional two-stage pipeline that necessitates 17ms.
Context-Aware Iteration Policy Network for Efficient Optical Flow Estimation
Dec 14, 2023



Existing recurrent optical flow estimation networks are computationally expensive since they use a fixed large number of iterations to update the flow field for each sample. An efficient network should skip iterations when the flow improvement is limited. In this paper, we develop a Context-Aware Iteration Policy Network for efficient optical flow estimation, which determines the optimal number of iterations per sample. The policy network achieves this by learning contextual information to realize whether flow improvement is bottlenecked or minimal. On the one hand, we use iteration embedding and historical hidden cell, which include previous iterations information, to convey how flow has changed from previous iterations. On the other hand, we use the incremental loss to make the policy network implicitly perceive the magnitude of optical flow improvement in the subsequent iteration. Furthermore, the computational complexity in our dynamic network is controllable, allowing us to satisfy various resource preferences with a single trained model. Our policy network can be easily integrated into state-of-the-art optical flow networks. Extensive experiments show that our method maintains performance while reducing FLOPs by about 40%/20% for the Sintel/KITTI datasets.
Uncertainty-Guided Spatial Pruning Architecture for Efficient Frame Interpolation
Aug 12, 2023



The video frame interpolation (VFI) model applies the convolution operation to all locations, leading to redundant computations in regions with easy motion. We can use dynamic spatial pruning method to skip redundant computation, but this method cannot properly identify easy regions in VFI tasks without supervision. In this paper, we develop an Uncertainty-Guided Spatial Pruning (UGSP) architecture to skip redundant computation for efficient frame interpolation dynamically. Specifically, pixels with low uncertainty indicate easy regions, where the calculation can be reduced without bringing undesirable visual results. Therefore, we utilize uncertainty-generated mask labels to guide our UGSP in properly locating the easy region. Furthermore, we propose a self-contrast training strategy that leverages an auxiliary non-pruning branch to improve the performance of our UGSP. Extensive experiments show that UGSP maintains performance but reduces FLOPs by 34%/52%/30% compared to baseline without pruning on Vimeo90K/UCF101/MiddleBury datasets. In addition, our method achieves state-of-the-art performance with lower FLOPs on multiple benchmarks.
Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution
Jul 21, 2022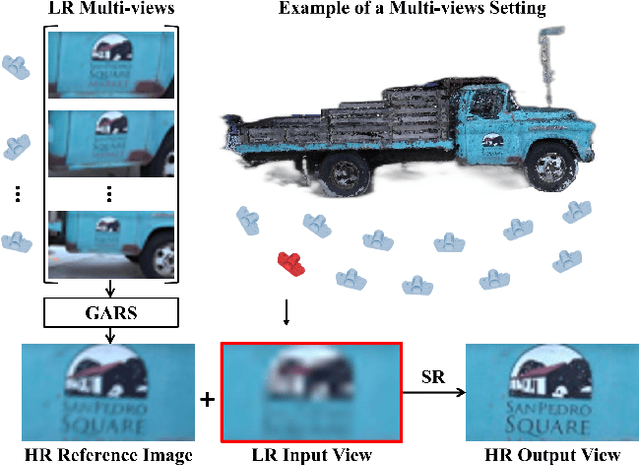
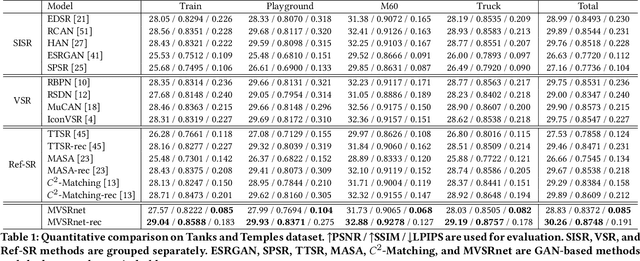

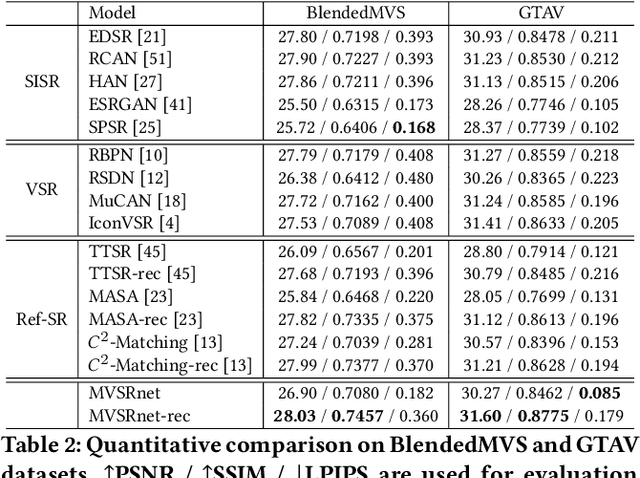
Recent multi-view multimedia applications struggle between high-resolution (HR) visual experience and storage or bandwidth constraints. Therefore, this paper proposes a Multi-View Image Super-Resolution (MVISR) task. It aims to increase the resolution of multi-view images captured from the same scene. One solution is to apply image or video super-resolution (SR) methods to reconstruct HR results from the low-resolution (LR) input view. However, these methods cannot handle large-angle transformations between views and leverage information in all multi-view images. To address these problems, we propose the MVSRnet, which uses geometry information to extract sharp details from all LR multi-view to support the SR of the LR input view. Specifically, the proposed Geometry-Aware Reference Synthesis module in MVSRnet uses geometry information and all multi-view LR images to synthesize pixel-aligned HR reference images. Then, the proposed Dynamic High-Frequency Search network fully exploits the high-frequency textural details in reference images for SR. Extensive experiments on several benchmarks show that our method significantly improves over the state-of-the-art approaches.
Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal
Jul 15, 2022
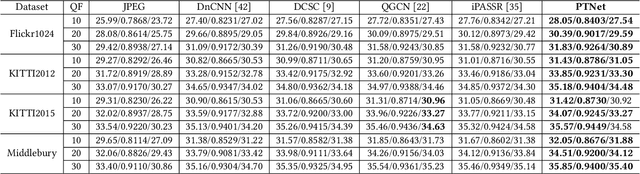
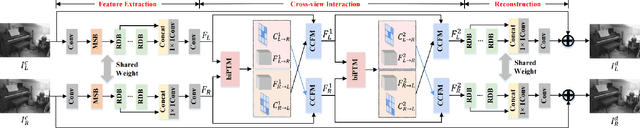
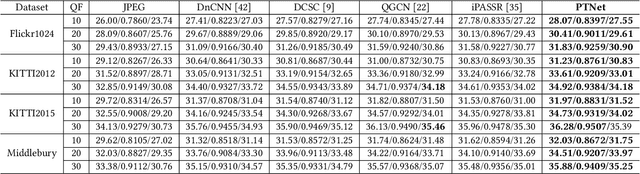
Under stereo settings, the performance of image JPEG artifacts removal can be further improved by exploiting the additional information provided by a second view. However, incorporating this information for stereo image JPEG artifacts removal is a huge challenge, since the existing compression artifacts make pixel-level view alignment difficult. In this paper, we propose a novel parallax transformer network (PTNet) to integrate the information from stereo image pairs for stereo image JPEG artifacts removal. Specifically, a well-designed symmetric bi-directional parallax transformer module is proposed to match features with similar textures between different views instead of pixel-level view alignment. Due to the issues of occlusions and boundaries, a confidence-based cross-view fusion module is proposed to achieve better feature fusion for both views, where the cross-view features are weighted with confidence maps. Especially, we adopt a coarse-to-fine design for the cross-view interaction, leading to better performance. Comprehensive experimental results demonstrate that our PTNet can effectively remove compression artifacts and achieves superior performance than other testing state-of-the-art methods.