 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Imbalance for Class Incremental Learning in Medical Image Classification
Jul 18, 2024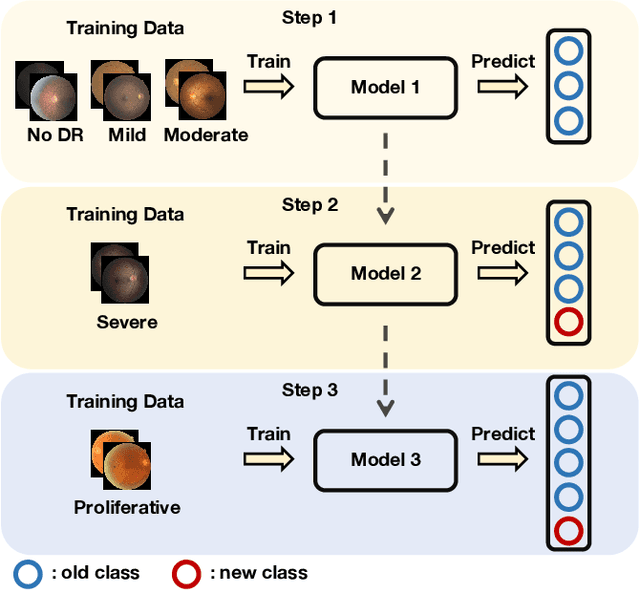
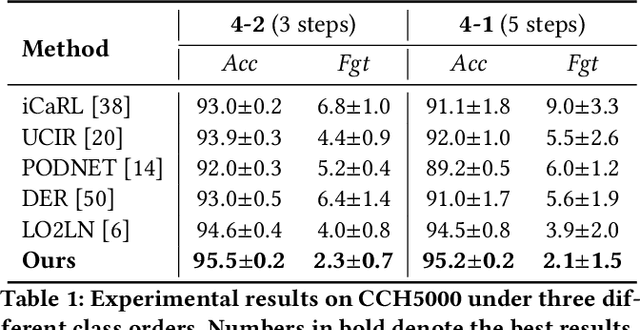
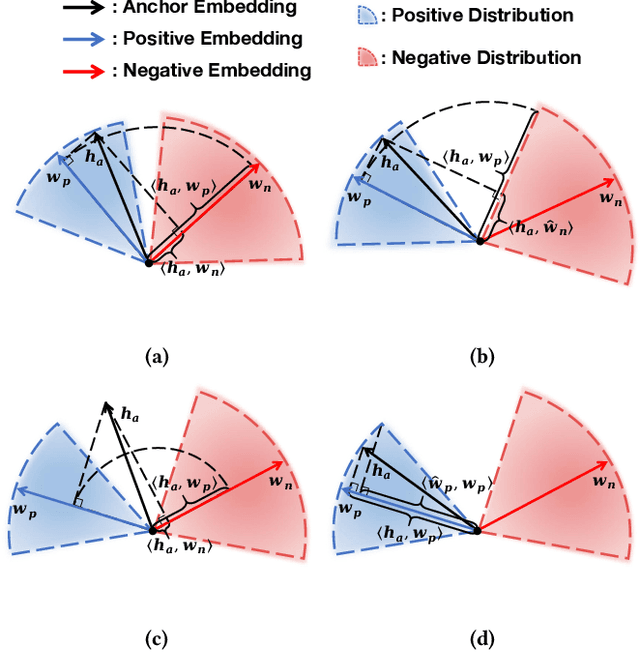
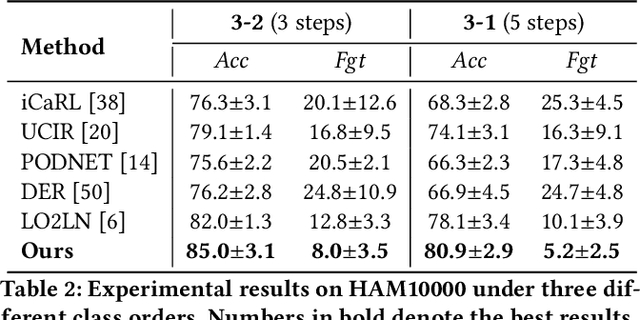
Deep convolutional neural networks have made significant breakthroughs in medical image classification, under the assumption that training samples from all classes are simultaneously available. However, in real-world medical scenarios, there's a common need to continuously learn about new diseases, leading to the emerging field of class incremental learning (CIL) in the medical domain. Typically, CIL suffers from catastrophic forgetting when trained on new classes. This phenomenon is mainly caused by the imbalance between old and new classes, and it becomes even more challenging with imbalanced medical datasets. In this work, we introduce two simple yet effective plug-in methods to mitigate the adverse effects of the imbalance. First, we propose a CIL-balanced classification loss to mitigate the classifier bias toward majority classes via logit adjustment. Second, we propose a distribution margin loss that not only alleviates the inter-class overlap in embedding space but also enforces the intra-class compactness. We evaluate the effectiveness of our method with extensive experiments on three benchmark datasets (CCH5000, HAM10000, and EyePACS). The results demonstrate that our approach outperforms state-of-the-art methods.
Context-Aware Iteration Policy Network for Efficient Optical Flow Estimation
Dec 14, 2023



Existing recurrent optical flow estimation networks are computationally expensive since they use a fixed large number of iterations to update the flow field for each sample. An efficient network should skip iterations when the flow improvement is limited. In this paper, we develop a Context-Aware Iteration Policy Network for efficient optical flow estimation, which determines the optimal number of iterations per sample. The policy network achieves this by learning contextual information to realize whether flow improvement is bottlenecked or minimal. On the one hand, we use iteration embedding and historical hidden cell, which include previous iterations information, to convey how flow has changed from previous iterations. On the other hand, we use the incremental loss to make the policy network implicitly perceive the magnitude of optical flow improvement in the subsequent iteration. Furthermore, the computational complexity in our dynamic network is controllable, allowing us to satisfy various resource preferences with a single trained model. Our policy network can be easily integrated into state-of-the-art optical flow networks. Extensive experiments show that our method maintains performance while reducing FLOPs by about 40%/20% for the Sintel/KITTI datasets.
Uncertainty-Guided Spatial Pruning Architecture for Efficient Frame Interpolation
Aug 12, 2023The video frame interpolation (VFI) model applies the convolution operation to all locations, leading to redundant computations in regions with easy motion. We can use dynamic spatial pruning method to skip redundant computation, but this method cannot properly identify easy regions in VFI tasks without supervision. In this paper, we develop an Uncertainty-Guided Spatial Pruning (UGSP) architecture to skip redundant computation for efficient frame interpolation dynamically. Specifically, pixels with low uncertainty indicate easy regions, where the calculation can be reduced without bringing undesirable visual results. Therefore, we utilize uncertainty-generated mask labels to guide our UGSP in properly locating the easy region. Furthermore, we propose a self-contrast training strategy that leverages an auxiliary non-pruning branch to improve the performance of our UGSP. Extensive experiments show that UGSP maintains performance but reduces FLOPs by 34%/52%/30% compared to baseline without pruning on Vimeo90K/UCF101/MiddleBury datasets. In addition, our method achieves state-of-the-art performance with lower FLOPs on multiple benchmarks.
MVFlow: Deep Optical Flow Estimation of Compressed Videos with Motion Vector Prior
Aug 04, 2023In recent years, many deep learning-based methods have been proposed to tackle the problem of optical flow estimation and achieved promising results. However, they hardly consider that most videos are compressed and thus ignore the pre-computed information in compressed video streams. Motion vectors, one of the compression information, record the motion of the video frames. They can be directly extracted from the compression code stream without computational cost and serve as a solid prior for optical flow estimation. Therefore, we propose an optical flow model, MVFlow, which uses motion vectors to improve the speed and accuracy of optical flow estimation for compressed videos. In detail, MVFlow includes a key Motion-Vector Converting Module, which ensures that the motion vectors can be transformed into the same domain of optical flow and then be utilized fully by the flow estimation module. Meanwhile, we construct four optical flow datasets for compressed videos containing frames and motion vectors in pairs. The experimental results demonstrate the superiority of our proposed MVFlow, which can reduce the AEPE by 1.09 compared to existing models or save 52% time to achieve similar accuracy to existing models.
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Multi-Modality Deep Network for Extreme Learned Image Compression
Apr 26, 2023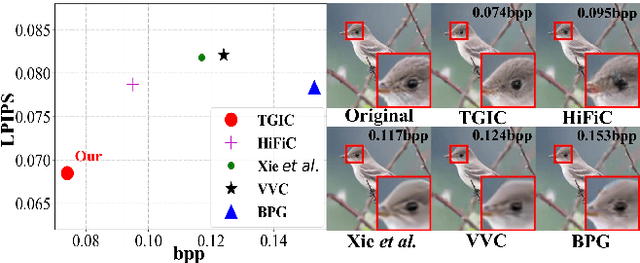

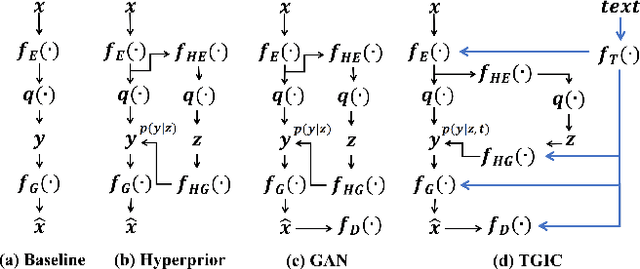

Image-based single-modality compression learning approaches have demonstrated exceptionally powerful encoding and decoding capabilities in the past few years , but suffer from blur and severe semantics loss at extremely low bitrates. To address this issue, we propose a multimodal machine learning method for text-guided image compression, in which the semantic information of text is used as prior information to guide image compression for better compression performance. We fully study the role of text description in different components of the codec, and demonstrate its effectiveness. In addition, we adopt the image-text attention module and image-request complement module to better fuse image and text features, and propose an improved multimodal semantic-consistent loss to produce semantically complete reconstructions. Extensive experiments, including a user study, prove that our method can obtain visually pleasing results at extremely low bitrates, and achieves a comparable or even better performance than state-of-the-art methods, even though these methods are at 2x to 4x bitrates of ours.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
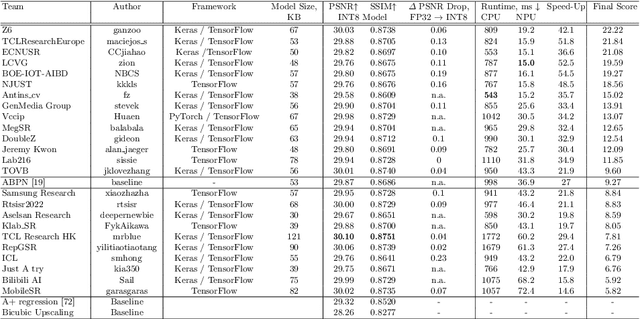
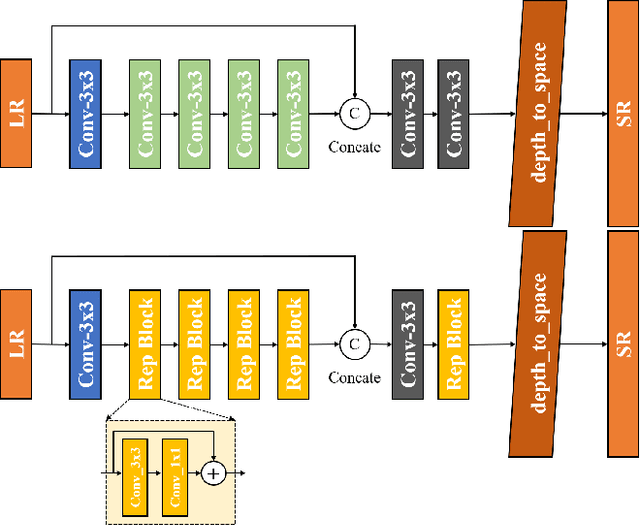
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal
Jul 15, 2022
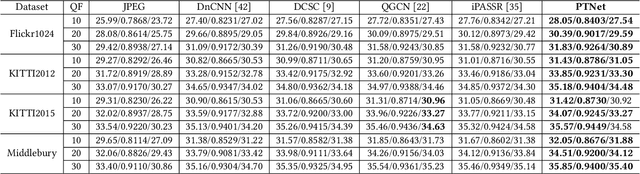
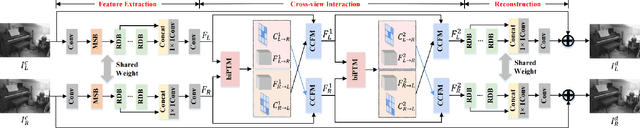
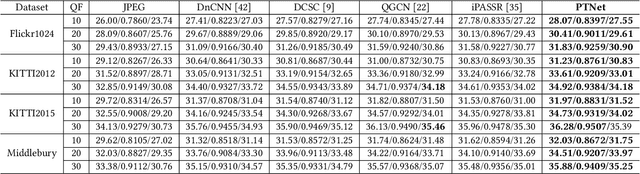
Under stereo settings, the performance of image JPEG artifacts removal can be further improved by exploiting the additional information provided by a second view. However, incorporating this information for stereo image JPEG artifacts removal is a huge challenge, since the existing compression artifacts make pixel-level view alignment difficult. In this paper, we propose a novel parallax transformer network (PTNet) to integrate the information from stereo image pairs for stereo image JPEG artifacts removal. Specifically, a well-designed symmetric bi-directional parallax transformer module is proposed to match features with similar textures between different views instead of pixel-level view alignment. Due to the issues of occlusions and boundaries, a confidence-based cross-view fusion module is proposed to achieve better feature fusion for both views, where the cross-view features are weighted with confidence maps. Especially, we adopt a coarse-to-fine design for the cross-view interaction, leading to better performance. Comprehensive experimental results demonstrate that our PTNet can effectively remove compression artifacts and achieves superior performance than other testing state-of-the-art methods.
Perception-Oriented Stereo Image Super-Resolution
Jul 14, 2022Recent studies of deep learning based stereo image super-resolution (StereoSR) have promoted the development of StereoSR. However, existing StereoSR models mainly concentrate on improving quantitative evaluation metrics and neglect the visual quality of super-resolved stereo images. To improve the perceptual performance, this paper proposes the first perception-oriented stereo image super-resolution approach by exploiting the feedback, provided by the evaluation on the perceptual quality of StereoSR results. To provide accurate guidance for the StereoSR model, we develop the first special stereo image super-resolution quality assessment (StereoSRQA) model, and further construct a StereoSRQA database. Extensive experiments demonstrate that our StereoSR approach significantly improves the perceptual quality and enhances the reliability of stereo images for disparity estimation.
Deep Optimization model for Screen Content Image Quality Assessment using Neural Networks
Mar 02, 2019
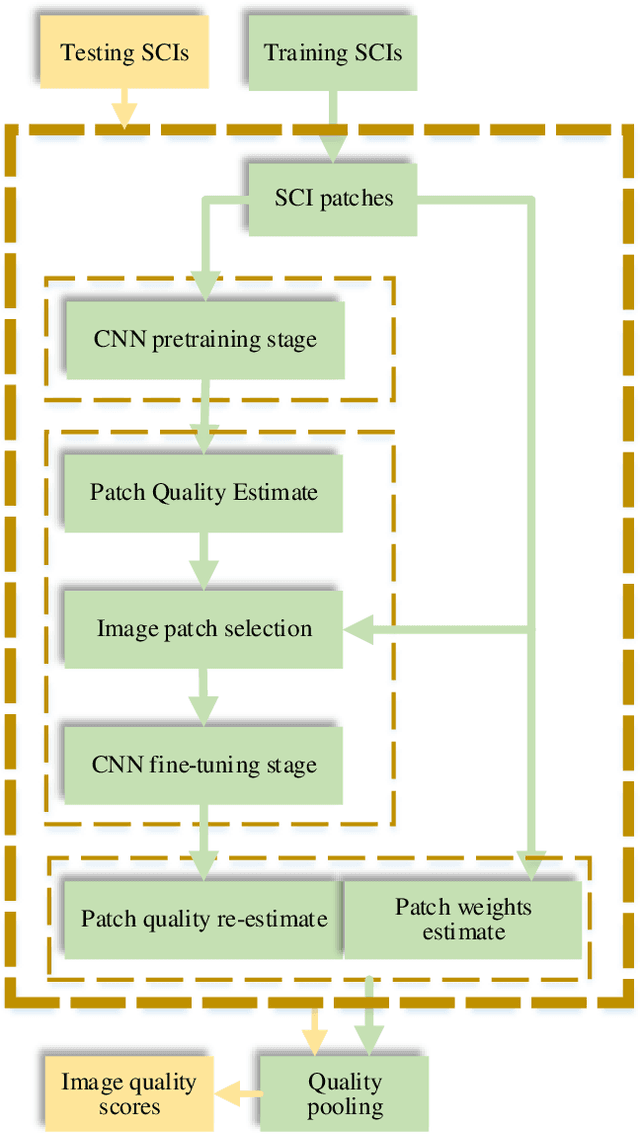
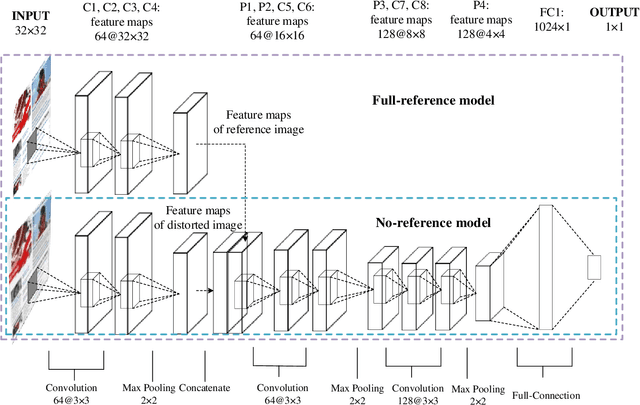
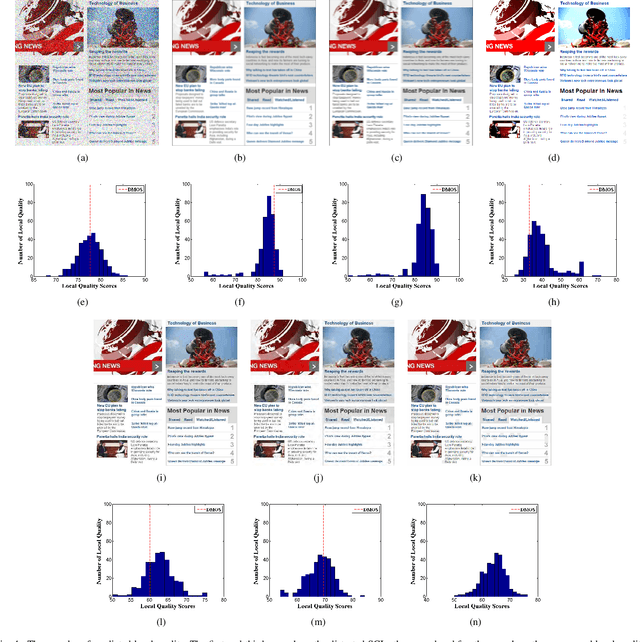
In this paper, we propose a novel quadratic optimized model based on the deep convolutional neural network (QODCNN) for full-reference and no-reference screen content image (SCI) quality assessment. Unlike traditional CNN methods taking all image patches as training data and using average quality pooling, our model is optimized to obtain a more effective model including three steps. In the first step, an end-to-end deep CNN is trained to preliminarily predict the image visual quality, and batch normalized (BN) layers and l2 regularization are employed to improve the speed and performance of network fitting. For second step, the pretrained model is fine-tuned to achieve better performance under analysis of the raw training data. An adaptive weighting method is proposed in the third step to fuse local quality inspired by the perceptual property of the human visual system (HVS) that the HVS is sensitive to image patches containing texture and edge information. The novelty of our algorithm can be concluded as follows: 1) with the consideration of correlation between local quality and subjective differential mean opinion score (DMOS), the Euclidean distance is utilized to measure effectiveness of image patches, and the pretrained model is fine-tuned with more effective training data; 2) an adaptive pooling approach is employed to fuse patch quality of textual and pictorial regions, whose feature only extracted from distorted images owns strong noise robust and effects on both FR and NR IQA; 3) Considering the characteristics of SCIs, a deep and valid network architecture is designed for both NR and FR visual quality evaluation of SCIs. Experimental results verify that our model outperforms both current no-reference and full-reference image quality assessment methods on the benchmark screen content image quality assessment database (SIQAD).