 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023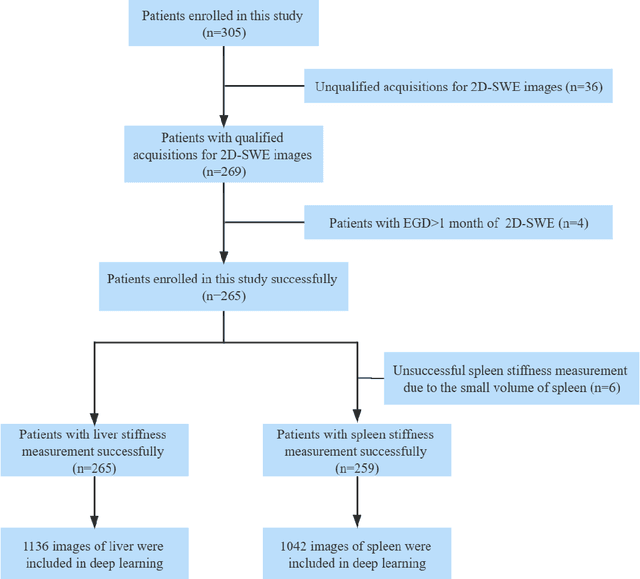
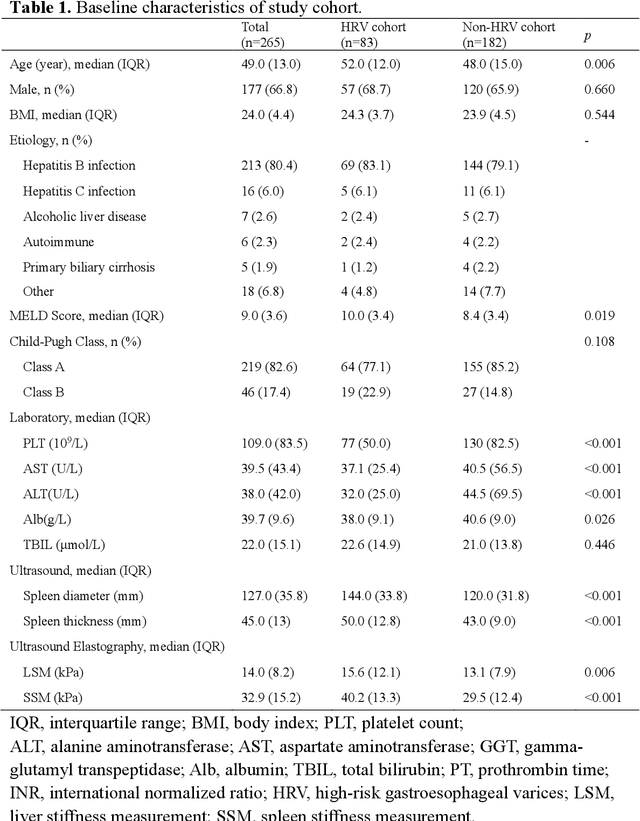
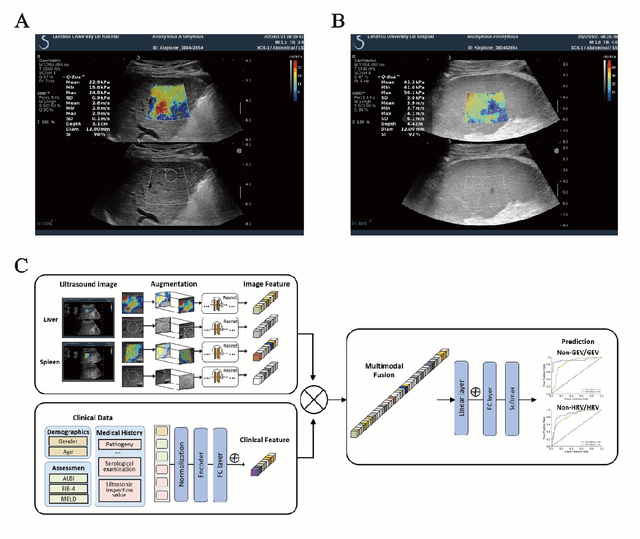
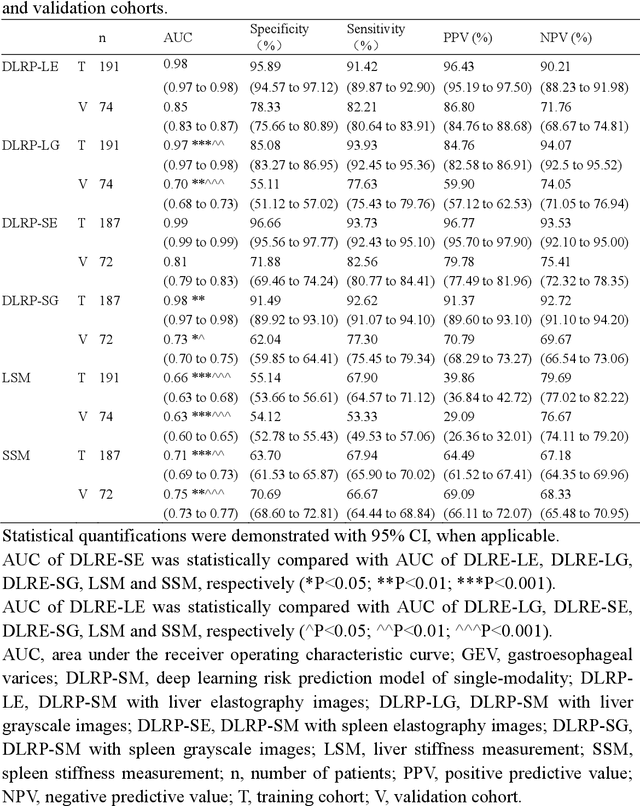
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Deep Optimization model for Screen Content Image Quality Assessment using Neural Networks
Mar 02, 2019
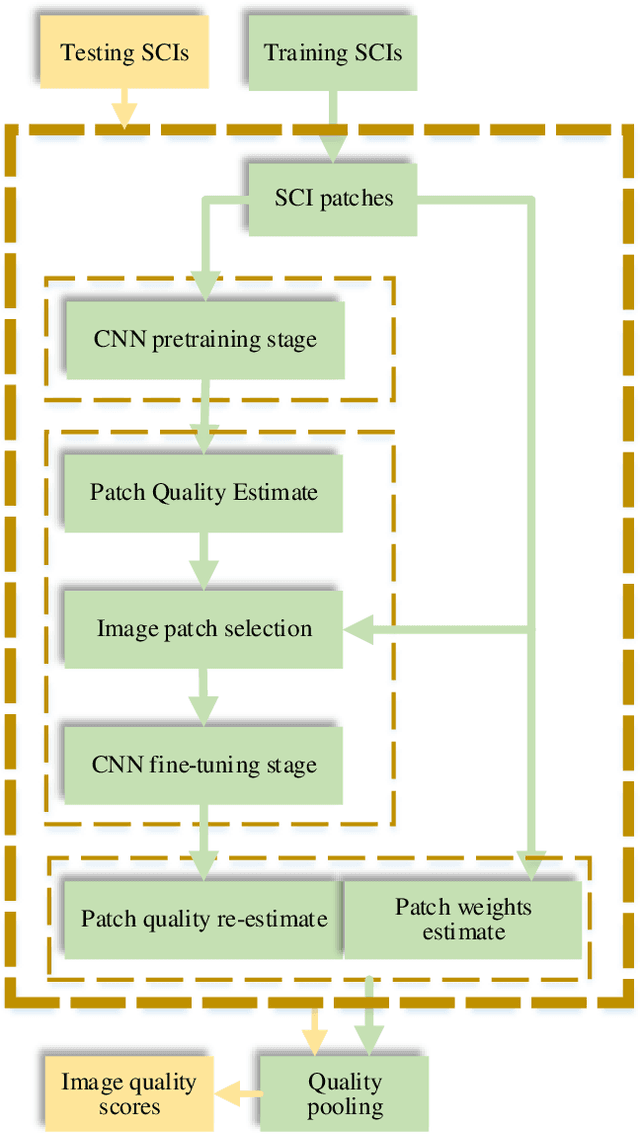
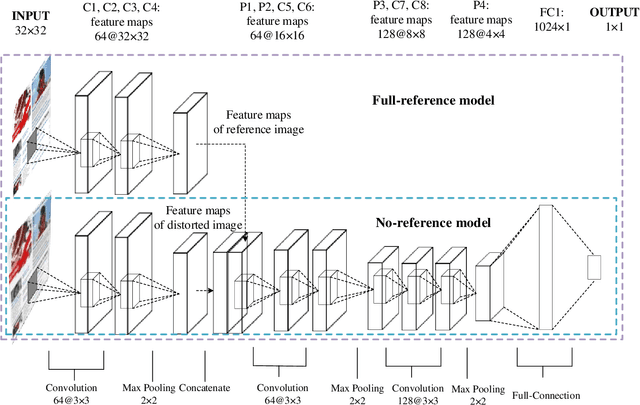
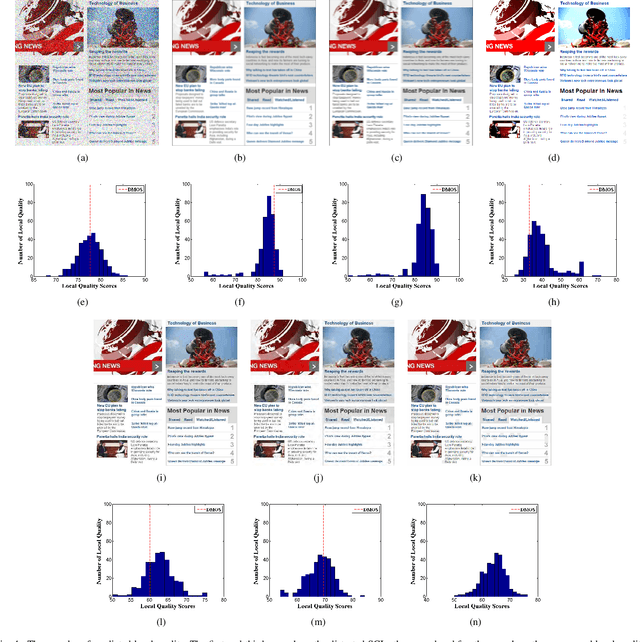
In this paper, we propose a novel quadratic optimized model based on the deep convolutional neural network (QODCNN) for full-reference and no-reference screen content image (SCI) quality assessment. Unlike traditional CNN methods taking all image patches as training data and using average quality pooling, our model is optimized to obtain a more effective model including three steps. In the first step, an end-to-end deep CNN is trained to preliminarily predict the image visual quality, and batch normalized (BN) layers and l2 regularization are employed to improve the speed and performance of network fitting. For second step, the pretrained model is fine-tuned to achieve better performance under analysis of the raw training data. An adaptive weighting method is proposed in the third step to fuse local quality inspired by the perceptual property of the human visual system (HVS) that the HVS is sensitive to image patches containing texture and edge information. The novelty of our algorithm can be concluded as follows: 1) with the consideration of correlation between local quality and subjective differential mean opinion score (DMOS), the Euclidean distance is utilized to measure effectiveness of image patches, and the pretrained model is fine-tuned with more effective training data; 2) an adaptive pooling approach is employed to fuse patch quality of textual and pictorial regions, whose feature only extracted from distorted images owns strong noise robust and effects on both FR and NR IQA; 3) Considering the characteristics of SCIs, a deep and valid network architecture is designed for both NR and FR visual quality evaluation of SCIs. Experimental results verify that our model outperforms both current no-reference and full-reference image quality assessment methods on the benchmark screen content image quality assessment database (SIQAD).