 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveUMI: Robotic Manipulation with Active Perception from Robot-Free Human Demonstrations
Oct 02, 2025


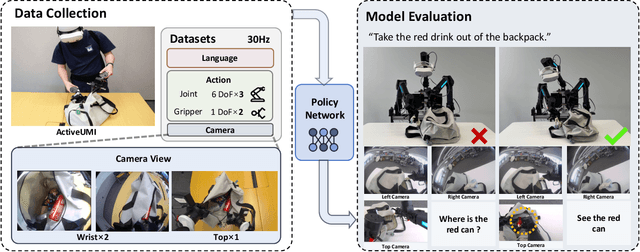
We present ActiveUMI, a framework for a data collection system that transfers in-the-wild human demonstrations to robots capable of complex bimanual manipulation. ActiveUMI couples a portable VR teleoperation kit with sensorized controllers that mirror the robot's end-effectors, bridging human-robot kinematics via precise pose alignment. To ensure mobility and data quality, we introduce several key techniques, including immersive 3D model rendering, a self-contained wearable computer, and efficient calibration methods. ActiveUMI's defining feature is its capture of active, egocentric perception. By recording an operator's deliberate head movements via a head-mounted display, our system learns the crucial link between visual attention and manipulation. We evaluate ActiveUMI on six challenging bimanual tasks. Policies trained exclusively on ActiveUMI data achieve an average success rate of 70\% on in-distribution tasks and demonstrate strong generalization, retaining a 56\% success rate when tested on novel objects and in new environments. Our results demonstrate that portable data collection systems, when coupled with learned active perception, provide an effective and scalable pathway toward creating generalizable and highly capable real-world robot policies.
REDEditing: Relationship-Driven Precise Backdoor Poisoning on Text-to-Image Diffusion Models
Apr 20, 2025The rapid advancement of generative AI highlights the importance of text-to-image (T2I) security, particularly with the threat of backdoor poisoning. Timely disclosure and mitigation of security vulnerabilities in T2I models are crucial for ensuring the safe deployment of generative models. We explore a novel training-free backdoor poisoning paradigm through model editing, which is recently employed for knowledge updating in large language models. Nevertheless, we reveal the potential security risks posed by model editing techniques to image generation models. In this work, we establish the principles for backdoor attacks based on model editing, and propose a relationship-driven precise backdoor poisoning method, REDEditing. Drawing on the principles of equivalent-attribute alignment and stealthy poisoning, we develop an equivalent relationship retrieval and joint-attribute transfer approach that ensures consistent backdoor image generation through concept rebinding. A knowledge isolation constraint is proposed to preserve benign generation integrity. Our method achieves an 11\% higher attack success rate compared to state-of-the-art approaches. Remarkably, adding just one line of code enhances output naturalness while improving backdoor stealthiness by 24\%. This work aims to heighten awareness regarding this security vulnerability in editable image generation models.
A Key-Driven Framework for Identity-Preserving Face Anonymization
Sep 05, 2024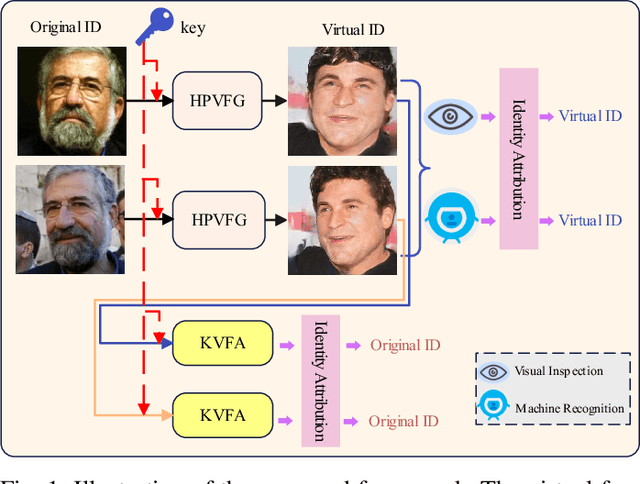
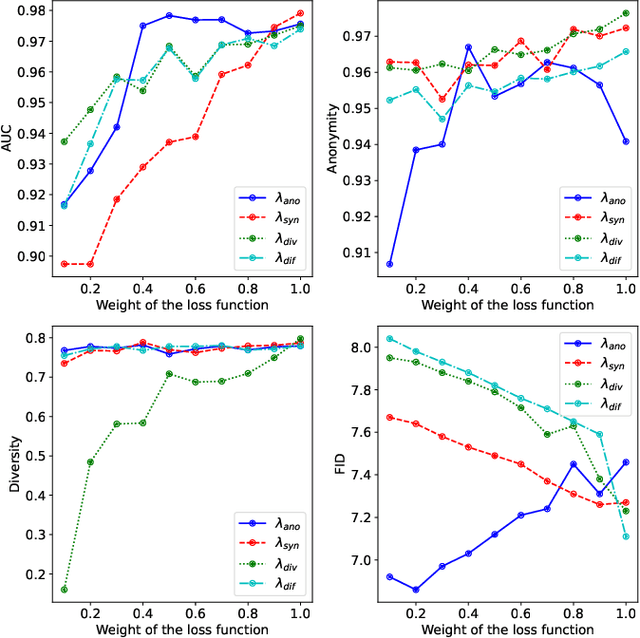
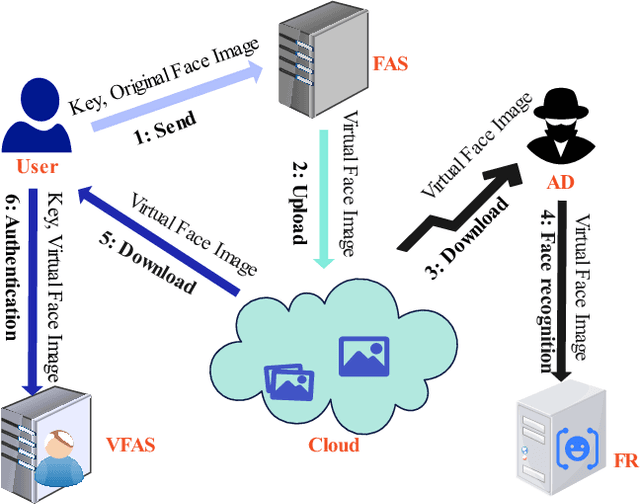
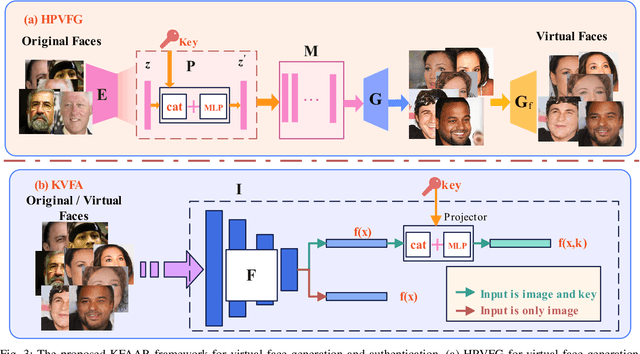
Virtual faces are crucial content in the metaverse. Recently, attempts have been made to generate virtual faces for privacy protection. Nevertheless, these virtual faces either permanently remove the identifiable information or map the original identity into a virtual one, which loses the original identity forever. In this study, we first attempt to address the conflict between privacy and identifiability in virtual faces, where a key-driven face anonymization and authentication recognition (KFAAR) framework is proposed. Concretely, the KFAAR framework consists of a head posture-preserving virtual face generation (HPVFG) module and a key-controllable virtual face authentication (KVFA) module. The HPVFG module uses a user key to project the latent vector of the original face into a virtual one. Then it maps the virtual vectors to obtain an extended encoding, based on which the virtual face is generated. By simultaneously adding a head posture and facial expression correction module, the virtual face has the same head posture and facial expression as the original face. During the authentication, we propose a KVFA module to directly recognize the virtual faces using the correct user key, which can obtain the original identity without exposing the original face image. We also propose a multi-task learning objective to train HPVFG and KVFA. Extensive experiments demonstrate the advantages of the proposed HPVFG and KVFA modules, which effectively achieve both facial anonymity and identifiability.
RFD-ECNet: Extreme Underwater Image Compression with Reference to Feature Dictionar
Aug 17, 2023Thriving underwater applications demand efficient extreme compression technology to realize the transmission of underwater images (UWIs) in very narrow underwater bandwidth. However, existing image compression methods achieve inferior performance on UWIs because they do not consider the characteristics of UWIs: (1) Multifarious underwater styles of color shift and distance-dependent clarity, caused by the unique underwater physical imaging; (2) Massive redundancy between different UWIs, caused by the fact that different UWIs contain several common ocean objects, which have plenty of similarities in structures and semantics. To remove redundancy among UWIs, we first construct an exhaustive underwater multi-scale feature dictionary to provide coarse-to-fine reference features for UWI compression. Subsequently, an extreme UWI compression network with reference to the feature dictionary (RFD-ECNet) is creatively proposed, which utilizes feature match and reference feature variant to significantly remove redundancy among UWIs. To align the multifarious underwater styles and improve the accuracy of feature match, an underwater style normalized block (USNB) is proposed, which utilizes underwater physical priors extracted from the underwater physical imaging model to normalize the underwater styles of dictionary features toward the input. Moreover, a reference feature variant module (RFVM) is designed to adaptively morph the reference features, improving the similarity between the reference and input features. Experimental results on four UWI datasets show that our RFD-ECNet is the first work that achieves a significant BD-rate saving of 31% over the most advanced VVC.
Semantic-Preserving Linguistic Steganography by Pivot Translation and Semantic-Aware Bins Coding
Mar 08, 2022
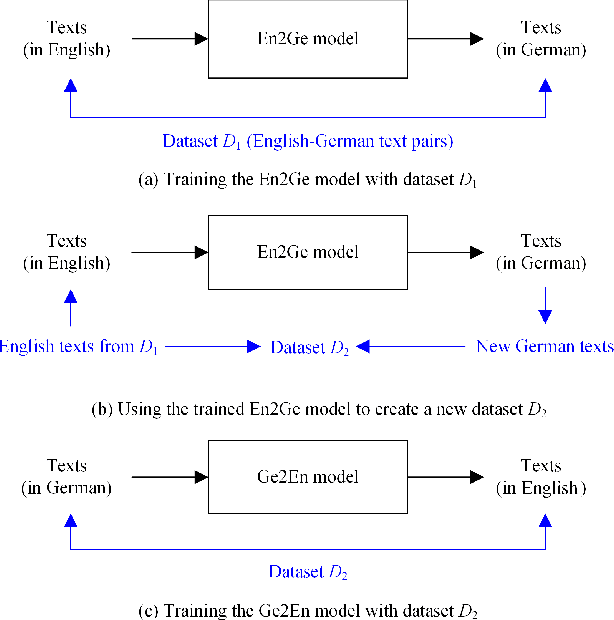
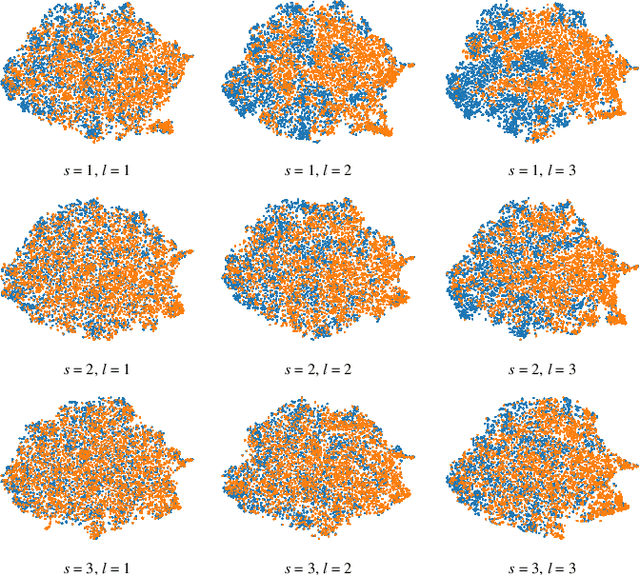
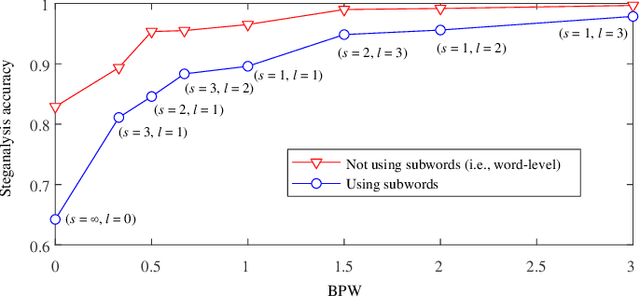
Linguistic steganography (LS) aims to embed secret information into a highly encoded text for covert communication. It can be roughly divided to two main categories, i.e., modification based LS (MLS) and generation based LS (GLS). Unlike MLS that hides secret data by slightly modifying a given text without impairing the meaning of the text, GLS uses a trained language model to directly generate a text carrying secret data. A common disadvantage for MLS methods is that the embedding payload is very low, whose return is well preserving the semantic quality of the text. In contrast, GLS allows the data hider to embed a high payload, which has to pay the high price of uncontrollable semantics. In this paper, we propose a novel LS method to modify a given text by pivoting it between two different languages and embed secret data by applying a GLS-like information encoding strategy. Our purpose is to alter the expression of the given text, enabling a high payload to be embedded while keeping the semantic information unchanged. Experimental results have shown that the proposed work not only achieves a high embedding payload, but also shows superior performance in maintaining the semantic consistency and resisting linguistic steganalysis.
Exploiting Language Model for Efficient Linguistic Steganalysis: An Empirical Study
Jul 26, 2021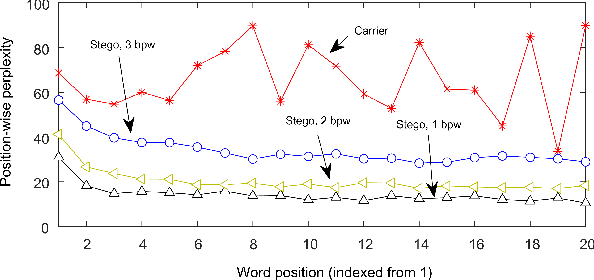
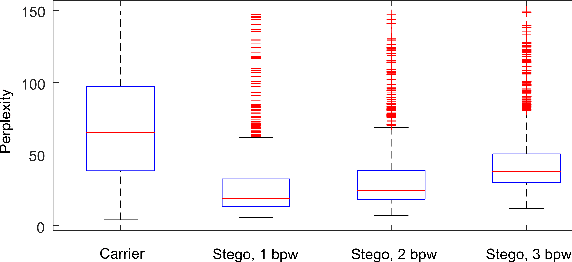
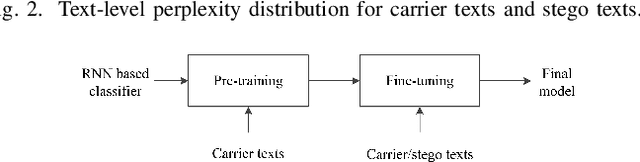
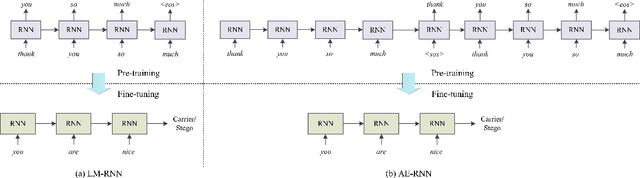
Recent advances in linguistic steganalysis have successively applied CNNs, RNNs, GNNs and other deep learning models for detecting secret information in generative texts. These methods tend to seek stronger feature extractors to achieve higher steganalysis effects. However, we have found through experiments that there actually exists significant difference between automatically generated steganographic texts and carrier texts in terms of the conditional probability distribution of individual words. Such kind of statistical difference can be naturally captured by the language model used for generating steganographic texts, which drives us to give the classifier a priori knowledge of the language model to enhance the steganalysis ability. To this end, we present two methods to efficient linguistic steganalysis in this paper. One is to pre-train a language model based on RNN, and the other is to pre-train a sequence autoencoder. Experimental results show that the two methods have different degrees of performance improvement when compared to the randomly initialized RNN classifier, and the convergence speed is significantly accelerated. Moreover, our methods have achieved the best detection results.
Orientation Convolutional Networks for Image Recognition
Feb 02, 2021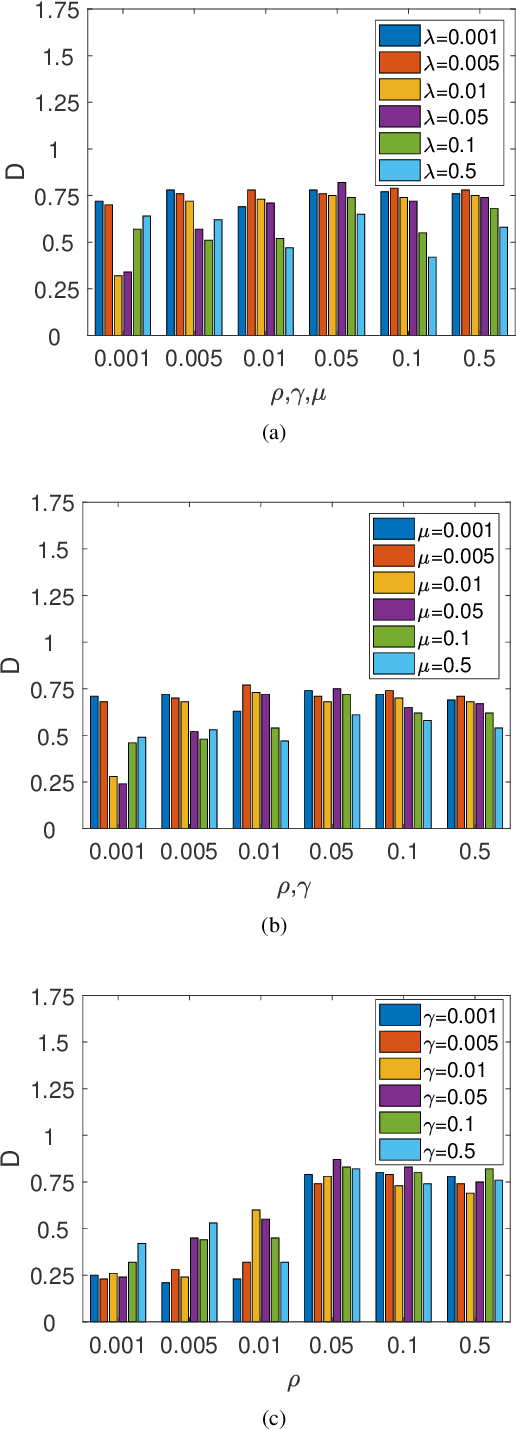
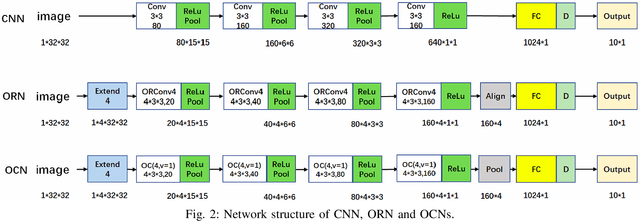
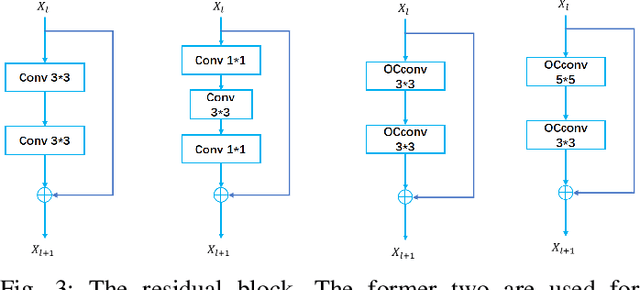

Deep Convolutional Neural Networks (DCNNs) are capable of obtaining powerful image representations, which have attracted great attentions in image recognition. However, they are limited in modeling orientation transformation by the internal mechanism. In this paper, we develop Orientation Convolution Networks (OCNs) for image recognition based on the proposed Landmark Gabor Filters (LGFs) that the robustness of the learned representation against changed of orientation can be enhanced. By modulating the convolutional filter with LGFs, OCNs can be compatible with any existing deep learning networks. LGFs act as a Gabor filter bank achieved by selecting $ p $ $ \left( \ll n\right) $ representative Gabor filters as andmarks and express the original Gabor filters as sparse linear combinations of these landmarks. Specifically, based on a matrix factorization framework, a flexible integration for the local and the global structure of original Gabor filters by sparsity and low-rank constraints is utilized. With the propogation of the low-rank structure, the corresponding sparsity for representation of original Gabor filter bank can be significantly promoted. Experimental results over several benchmarks demonstrate that our method is less sensitive to the orientation and produce higher performance both in accuracy and cost, compared with the existing state-of-art methods. Besides, our OCNs have few parameters to learn and can significantly reduce the complexity of training network.
Deep Optimization model for Screen Content Image Quality Assessment using Neural Networks
Mar 02, 2019
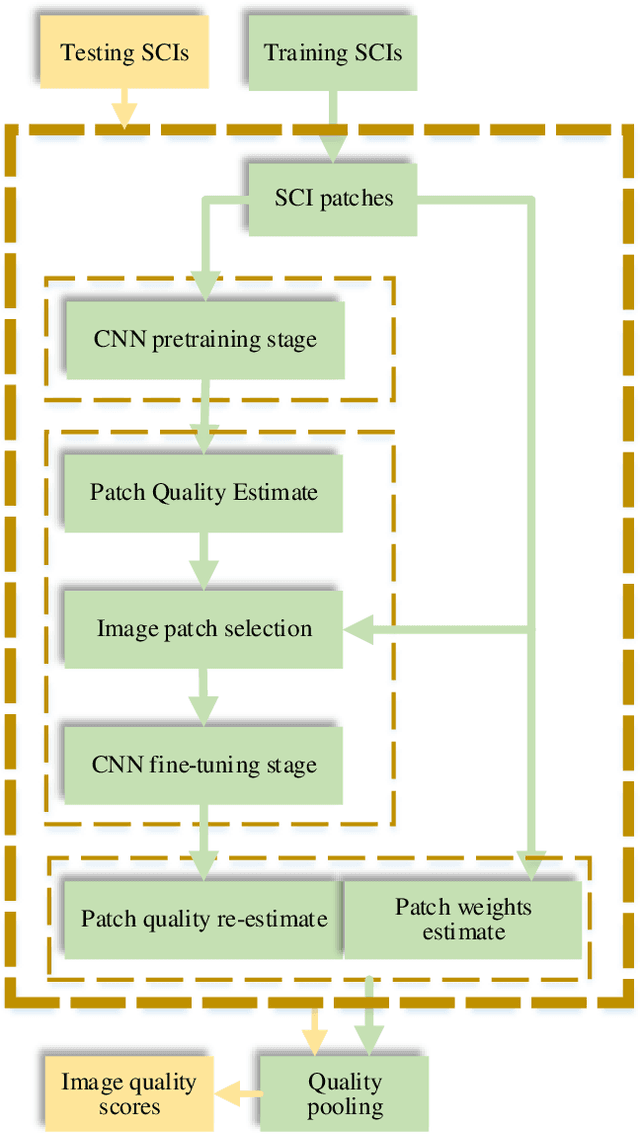
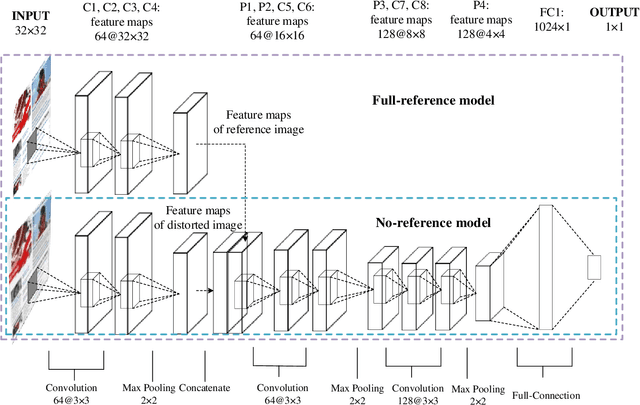
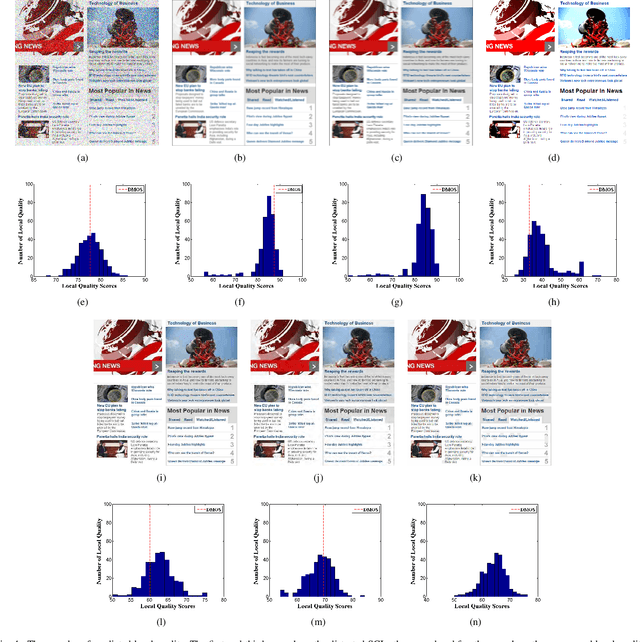
In this paper, we propose a novel quadratic optimized model based on the deep convolutional neural network (QODCNN) for full-reference and no-reference screen content image (SCI) quality assessment. Unlike traditional CNN methods taking all image patches as training data and using average quality pooling, our model is optimized to obtain a more effective model including three steps. In the first step, an end-to-end deep CNN is trained to preliminarily predict the image visual quality, and batch normalized (BN) layers and l2 regularization are employed to improve the speed and performance of network fitting. For second step, the pretrained model is fine-tuned to achieve better performance under analysis of the raw training data. An adaptive weighting method is proposed in the third step to fuse local quality inspired by the perceptual property of the human visual system (HVS) that the HVS is sensitive to image patches containing texture and edge information. The novelty of our algorithm can be concluded as follows: 1) with the consideration of correlation between local quality and subjective differential mean opinion score (DMOS), the Euclidean distance is utilized to measure effectiveness of image patches, and the pretrained model is fine-tuned with more effective training data; 2) an adaptive pooling approach is employed to fuse patch quality of textual and pictorial regions, whose feature only extracted from distorted images owns strong noise robust and effects on both FR and NR IQA; 3) Considering the characteristics of SCIs, a deep and valid network architecture is designed for both NR and FR visual quality evaluation of SCIs. Experimental results verify that our model outperforms both current no-reference and full-reference image quality assessment methods on the benchmark screen content image quality assessment database (SIQAD).