 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Language Model for Efficient Linguistic Steganalysis: An Empirical Study
Paper and Code
Jul 26, 2021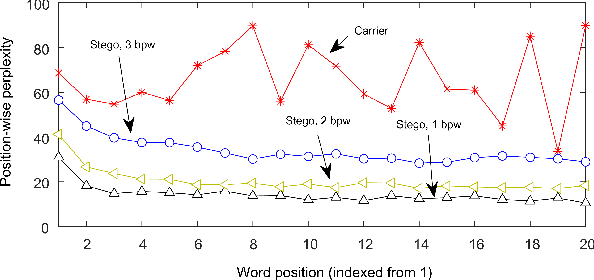
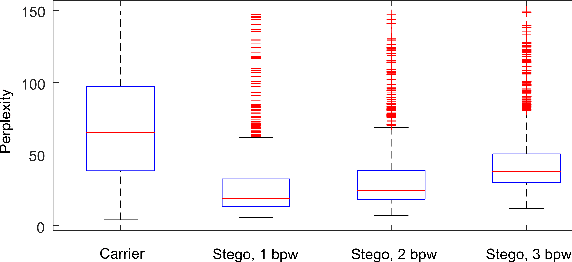
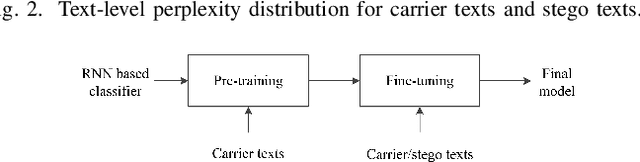
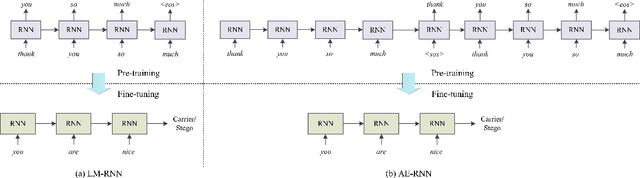
Recent advances in linguistic steganalysis have successively applied CNNs, RNNs, GNNs and other deep learning models for detecting secret information in generative texts. These methods tend to seek stronger feature extractors to achieve higher steganalysis effects. However, we have found through experiments that there actually exists significant difference between automatically generated steganographic texts and carrier texts in terms of the conditional probability distribution of individual words. Such kind of statistical difference can be naturally captured by the language model used for generating steganographic texts, which drives us to give the classifier a priori knowledge of the language model to enhance the steganalysis ability. To this end, we present two methods to efficient linguistic steganalysis in this paper. One is to pre-train a language model based on RNN, and the other is to pre-train a sequence autoencoder. Experimental results show that the two methods have different degrees of performance improvement when compared to the randomly initialized RNN classifier, and the convergence speed is significantly accelerated. Moreover, our methods have achieved the best detection results.