 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYet Another Watermark for Large Language Models
Sep 16, 2025Existing watermarking methods for large language models (LLMs) mainly embed watermark by adjusting the token sampling prediction or post-processing, lacking intrinsic coupling with LLMs, which may significantly reduce the semantic quality of the generated marked texts. Traditional watermarking methods based on training or fine-tuning may be extendable to LLMs. However, most of them are limited to the white-box scenario, or very time-consuming due to the massive parameters of LLMs. In this paper, we present a new watermarking framework for LLMs, where the watermark is embedded into the LLM by manipulating the internal parameters of the LLM, and can be extracted from the generated text without accessing the LLM. Comparing with related methods, the proposed method entangles the watermark with the intrinsic parameters of the LLM, which better balances the robustness and imperceptibility of the watermark. Moreover, the proposed method enables us to extract the watermark under the black-box scenario, which is computationally efficient for use. Experimental results have also verified the feasibility, superiority and practicality. This work provides a new perspective different from mainstream works, which may shed light on future research.
ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs
Apr 08, 2025



Chain-of-Thought (CoT) enhances an LLM's ability to perform complex reasoning tasks, but it also introduces new security issues. In this work, we present ShadowCoT, a novel backdoor attack framework that targets the internal reasoning mechanism of LLMs. Unlike prior token-level or prompt-based attacks, ShadowCoT directly manipulates the model's cognitive reasoning path, enabling it to hijack multi-step reasoning chains and produce logically coherent but adversarial outcomes. By conditioning on internal reasoning states, ShadowCoT learns to recognize and selectively disrupt key reasoning steps, effectively mounting a self-reflective cognitive attack within the target model. Our approach introduces a lightweight yet effective multi-stage injection pipeline, which selectively rewires attention pathways and perturbs intermediate representations with minimal parameter overhead (only 0.15% updated). ShadowCoT further leverages reinforcement learning and reasoning chain pollution (RCP) to autonomously synthesize stealthy adversarial CoTs that remain undetectable to advanced defenses. Extensive experiments across diverse reasoning benchmarks and LLMs show that ShadowCoT consistently achieves high Attack Success Rate (94.4%) and Hijacking Success Rate (88.4%) while preserving benign performance. These results reveal an emergent class of cognition-level threats and highlight the urgent need for defenses beyond shallow surface-level consistency.
Discriminative Anchor Learning for Efficient Multi-view Clustering
Sep 25, 2024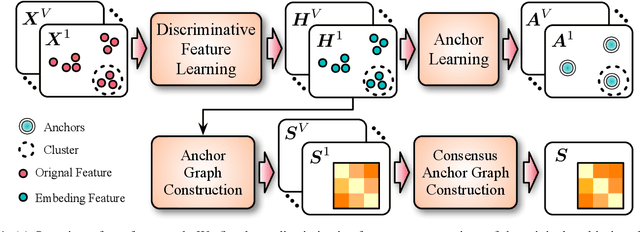
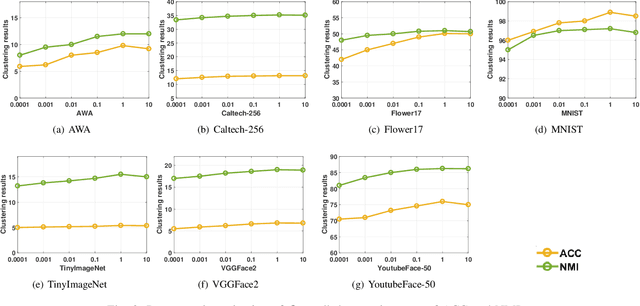
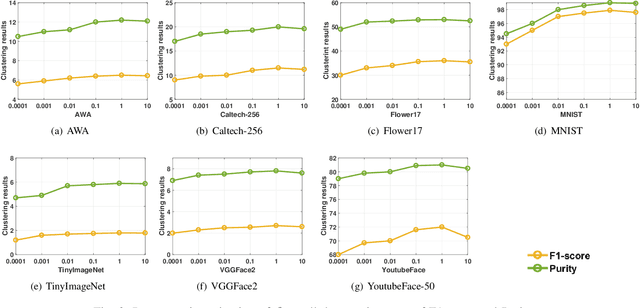
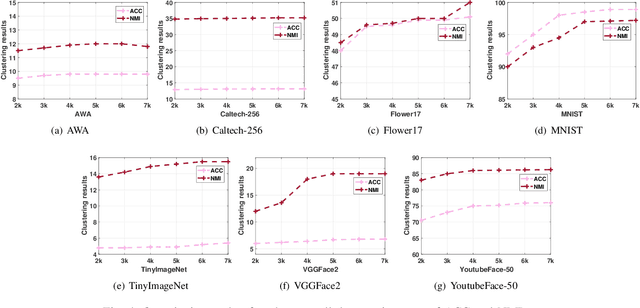
Multi-view clustering aims to study the complementary information across views and discover the underlying structure. For solving the relatively high computational cost for the existing approaches, works based on anchor have been presented recently. Even with acceptable clustering performance, these methods tend to map the original representation from multiple views into a fixed shared graph based on the original dataset. However, most studies ignore the discriminative property of the learned anchors, which ruin the representation capability of the built model. Moreover, the complementary information among anchors across views is neglected to be ensured by simply learning the shared anchor graph without considering the quality of view-specific anchors. In this paper, we propose discriminative anchor learning for multi-view clustering (DALMC) for handling the above issues. We learn discriminative view-specific feature representations according to the original dataset and build anchors from different views based on these representations, which increase the quality of the shared anchor graph. The discriminative feature learning and consensus anchor graph construction are integrated into a unified framework to improve each other for realizing the refinement. The optimal anchors from multiple views and the consensus anchor graph are learned with the orthogonal constraints. We give an iterative algorithm to deal with the formulated problem. Extensive experiments on different datasets show the effectiveness and efficiency of our method compared with other methods.
TCNFormer: Temporal Convolutional Network Former for Short-Term Wind Speed Forecasting
Aug 27, 2024



Global environmental challenges and rising energy demands have led to extensive exploration of wind energy technologies. Accurate wind speed forecasting (WSF) is crucial for optimizing wind energy capture and ensuring system stability. However, predicting wind speed remains challenging due to its inherent randomness, fluctuation, and unpredictability. This study proposes the Temporal Convolutional Network Former (TCNFormer) for short-term (12-hour) wind speed forecasting. The TCNFormer integrates the Temporal Convolutional Network (TCN) and transformer encoder to capture the spatio-temporal features of wind speed. The transformer encoder consists of two distinct attention mechanisms: causal temporal multi-head self-attention (CT-MSA) and temporal external attention (TEA). CT-MSA ensures that the output of a step derives only from previous steps, i.e., causality. Locality is also introduced to improve efficiency. TEA explores potential relationships between different sample sequences in wind speed data. This study utilizes wind speed data from the NASA Prediction of Worldwide Energy Resources (NASA POWER) of Patenga Sea Beach, Chittagong, Bangladesh (latitude 22.2352{\deg} N, longitude 91.7914{\deg} E) over a year (six seasons). The findings indicate that the TCNFormer outperforms state-of-the-art models in prediction accuracy. The proposed TCNFormer presents a promising method for spatio-temporal WSF and may achieve desirable performance in real-world applications of wind power systems.
JPEG Steganalysis Based on Steganographic Feature Enhancement and Graph Attention Learning
Feb 05, 2023The purpose of image steganalysis is to determine whether the carrier image contains hidden information or not. Since JEPG is the most commonly used image format over social networks, steganalysis in JPEG images is also the most urgently needed to be explored. However, in order to detect whether secret information is hidden within JEPG images, the majority of existing algorithms are designed in conjunction with the popular computer vision related networks, without considering the key characteristics appeared in image steganalysis. It is crucial that the steganographic signal, as an extremely weak signal, can be enhanced during its representation learning process. Motivated by this insight, in this paper, we introduce a novel representation learning algorithm for JPEG steganalysis that is mainly consisting of a graph attention learning module and a feature enhancement module. The graph attention learning module is designed to avoid global feature loss caused by the local feature learning of convolutional neural network and reliance on depth stacking to extend the perceptual domain. The feature enhancement module is applied to prevent the stacking of convolutional layers from weakening the steganographic information. In addition, pretraining as a way to initialize the network weights with a large-scale dataset is utilized to enhance the ability of the network to extract discriminative features. We advocate pretraining with ALASKA2 for the model trained with BOSSBase+BOWS2. The experimental results indicate that the proposed algorithm outperforms previous arts in terms of detection accuracy, which has verified the superiority and applicability of the proposed work.
Generative Model Watermarking Based on Human Visual System
Sep 30, 2022
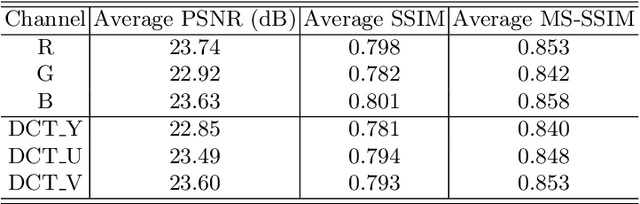


Intellectual property protection of deep neural networks is receiving attention from more and more researchers, and the latest research applies model watermarking to generative models for image processing. However, the existing watermarking methods designed for generative models do not take into account the effects of different channels of sample images on watermarking. As a result, the watermarking performance is still limited. To tackle this problem, in this paper, we first analyze the effects of embedding watermark information on different channels. Then, based on the characteristics of human visual system (HVS), we introduce two HVS-based generative model watermarking methods, which are realized in RGB color space and YUV color space respectively. In RGB color space, the watermark is embedded into the R and B channels based on the fact that HVS is more sensitive to G channel. In YUV color space, the watermark is embedded into the DCT domain of U and V channels based on the fact that HVS is more sensitive to brightness changes. Experimental results demonstrate the effectiveness of the proposed work, which improves the fidelity of the model to be protected and has good universality compared with previous methods.
Robust and Lossless Fingerprinting of Deep Neural Networks via Pooled Membership Inference
Sep 09, 2022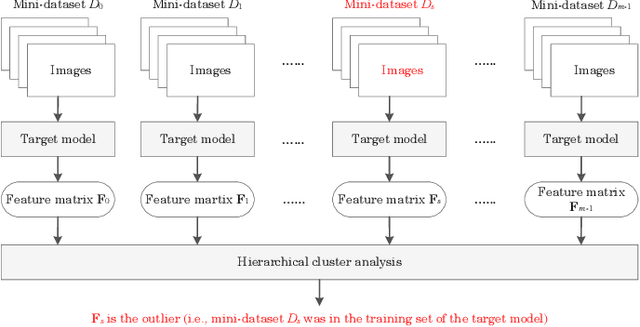
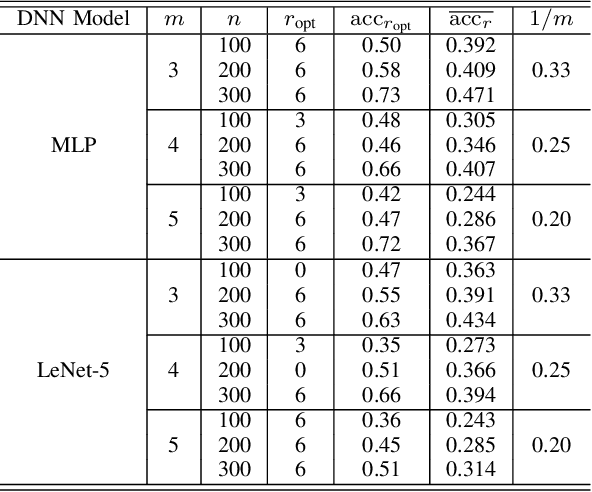
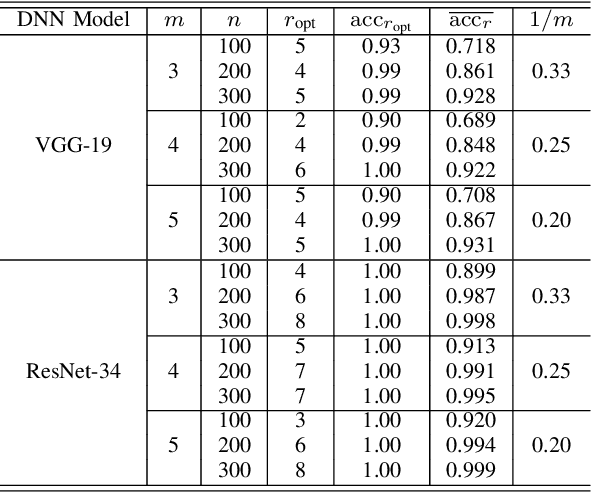
Deep neural networks (DNNs) have already achieved great success in a lot of application areas and brought profound changes to our society. However, it also raises new security problems, among which how to protect the intellectual property (IP) of DNNs against infringement is one of the most important yet very challenging topics. To deal with this problem, recent studies focus on the IP protection of DNNs by applying digital watermarking, which embeds source information and/or authentication data into DNN models by tuning network parameters directly or indirectly. However, tuning network parameters inevitably distorts the DNN and therefore surely impairs the performance of the DNN model on its original task regardless of the degree of the performance degradation. It has motivated the authors in this paper to propose a novel technique called \emph{pooled membership inference (PMI)} so as to protect the IP of the DNN models. The proposed PMI neither alters the network parameters of the given DNN model nor fine-tunes the DNN model with a sequence of carefully crafted trigger samples. Instead, it leaves the original DNN model unchanged, but can determine the ownership of the DNN model by inferring which mini-dataset among multiple mini-datasets was once used to train the target DNN model, which differs from previous arts and has remarkable potential in practice. Experiments also have demonstrated the superiority and applicability of this work.
AWEncoder: Adversarial Watermarking Pre-trained Encoders in Contrastive Learning
Aug 08, 2022

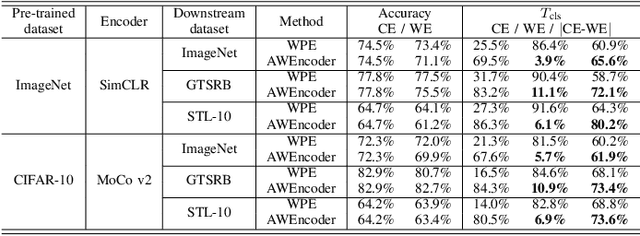
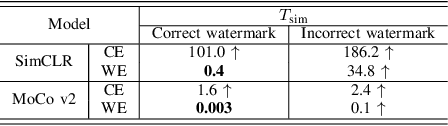
As a self-supervised learning paradigm, contrastive learning has been widely used to pre-train a powerful encoder as an effective feature extractor for various downstream tasks. This process requires numerous unlabeled training data and computational resources, which makes the pre-trained encoder become valuable intellectual property of the owner. However, the lack of a priori knowledge of downstream tasks makes it non-trivial to protect the intellectual property of the pre-trained encoder by applying conventional watermarking methods. To deal with this problem, in this paper, we introduce AWEncoder, an adversarial method for watermarking the pre-trained encoder in contrastive learning. First, as an adversarial perturbation, the watermark is generated by enforcing the training samples to be marked to deviate respective location and surround a randomly selected key image in the embedding space. Then, the watermark is embedded into the pre-trained encoder by further optimizing a joint loss function. As a result, the watermarked encoder not only performs very well for downstream tasks, but also enables us to verify its ownership by analyzing the discrepancy of output provided using the encoder as the backbone under both white-box and black-box conditions. Extensive experiments demonstrate that the proposed work enjoys pretty good effectiveness and robustness on different contrastive learning algorithms and downstream tasks, which has verified the superiority and applicability of the proposed work.
General Framework for Reversible Data Hiding in Texts Based on Masked Language Modeling
Jun 21, 2022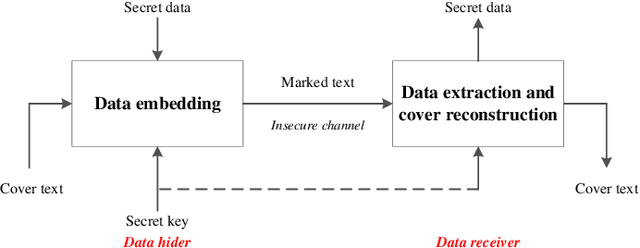
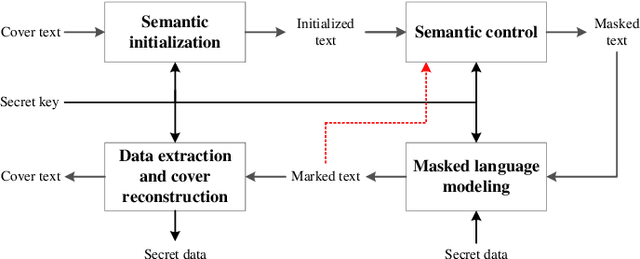
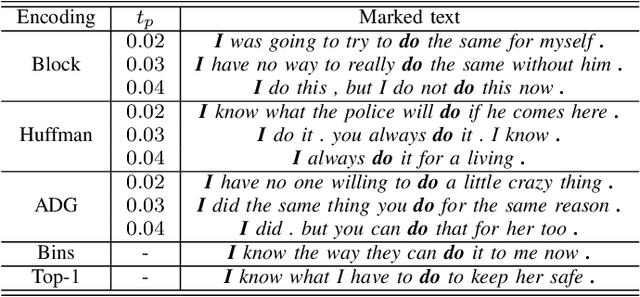

With the fast development of natural language processing, recent advances in information hiding focus on covertly embedding secret information into texts. These algorithms either modify a given cover text or directly generate a text containing secret information, which, however, are not reversible, meaning that the original text not carrying secret information cannot be perfectly recovered unless much side information are shared in advance. To tackle with this problem, in this paper, we propose a general framework to embed secret information into a given cover text, for which the embedded information and the original cover text can be perfectly retrieved from the marked text. The main idea of the proposed method is to use a masked language model to generate such a marked text that the cover text can be reconstructed by collecting the words of some positions and the words of the other positions can be processed to extract the secret information. Our results show that the original cover text and the secret information can be successfully embedded and extracted. Meanwhile, the marked text carrying secret information has good fluency and semantic quality, indicating that the proposed method has satisfactory security, which has been verified by experimental results. Furthermore, there is no need for the data hider and data receiver to share the language model, which significantly reduces the side information and thus has good potential in applications.
Verifying Integrity of Deep Ensemble Models by Lossless Black-box Watermarking with Sensitive Samples
May 10, 2022
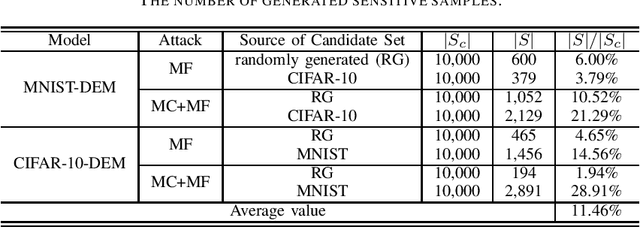
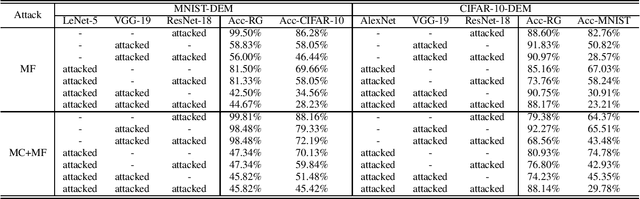
With the widespread use of deep neural networks (DNNs) in many areas, more and more studies focus on protecting DNN models from intellectual property (IP) infringement. Many existing methods apply digital watermarking to protect the DNN models. The majority of them either embed a watermark directly into the internal network structure/parameters or insert a zero-bit watermark by fine-tuning a model to be protected with a set of so-called trigger samples. Though these methods work very well, they were designed for individual DNN models, which cannot be directly applied to deep ensemble models (DEMs) that combine multiple DNN models to make the final decision. It motivates us to propose a novel black-box watermarking method in this paper for DEMs, which can be used for verifying the integrity of DEMs. In the proposed method, a certain number of sensitive samples are carefully selected through mimicking real-world DEM attacks and analyzing the prediction results of the sub-models of the non-attacked DEM and the attacked DEM on the carefully crafted dataset. By analyzing the prediction results of the target DEM on these carefully crafted sensitive samples, we are able to verify the integrity of the target DEM. Different from many previous methods, the proposed method does not modify the original DEM to be protected, which indicates that the proposed method is lossless. Experimental results have shown that the DEM integrity can be reliably verified even if only one sub-model was attacked, which has good potential in practice.