 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Linguistic Steganography Based on BERT and Consistency Coding
Paper and Code
Mar 26, 2022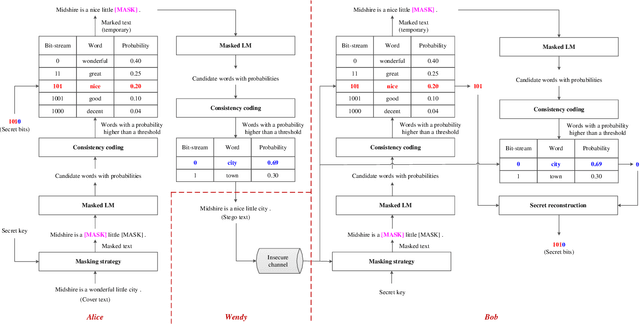



Linguistic steganography (LS) conceals the presence of communication by embedding secret information into a text. How to generate a high-quality text carrying secret information is a key problem. With the widespread application of deep learning in natural language processing, recent algorithms use a language model (LM) to generate the steganographic text, which provides a higher payload compared with many previous arts. However, the security still needs to be enhanced. To tackle with this problem, we propose a novel autoregressive LS algorithm based on BERT and consistency coding, which achieves a better trade-off between embedding payload and system security. In the proposed work, based on the introduction of the masked LM, given a text, we use consistency coding to make up for the shortcomings of block coding used in the previous work so that we can encode arbitrary-size candidate token set and take advantages of the probability distribution for information hiding. The masked positions to be embedded are filled with tokens determined by an autoregressive manner to enhance the connection between contexts and therefore maintain the quality of the text. Experimental results have shown that, compared with related works, the proposed work improves the fluency of the steganographic text while guaranteeing security, and also increases the embedding payload to a certain extent.