 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientCrackNet: A Lightweight Model for Crack Segmentation
Sep 26, 2024



Crack detection, particularly from pavement images, presents a formidable challenge in the domain of computer vision due to several inherent complexities such as intensity inhomogeneity, intricate topologies, low contrast, and noisy backgrounds. Automated crack detection is crucial for maintaining the structural integrity of essential infrastructures, including buildings, pavements, and bridges. Existing lightweight methods often face challenges including computational inefficiency, complex crack patterns, and difficult backgrounds, leading to inaccurate detection and impracticality for real-world applications. To address these limitations, we propose EfficientCrackNet, a lightweight hybrid model combining Convolutional Neural Networks (CNNs) and transformers for precise crack segmentation. EfficientCrackNet integrates depthwise separable convolutions (DSC) layers and MobileViT block to capture both global and local features. The model employs an Edge Extraction Method (EEM) and for efficient crack edge detection without pretraining, and Ultra-Lightweight Subspace Attention Module (ULSAM) to enhance feature extraction. Extensive experiments on three benchmark datasets Crack500, DeepCrack, and GAPs384 demonstrate that EfficientCrackNet achieves superior performance compared to existing lightweight models, while requiring only 0.26M parameters, and 0.483 FLOPs (G). The proposed model offers an optimal balance between accuracy and computational efficiency, outperforming state-of-the-art lightweight models, and providing a robust and adaptable solution for real-world crack segmentation.
TCNFormer: Temporal Convolutional Network Former for Short-Term Wind Speed Forecasting
Aug 27, 2024



Global environmental challenges and rising energy demands have led to extensive exploration of wind energy technologies. Accurate wind speed forecasting (WSF) is crucial for optimizing wind energy capture and ensuring system stability. However, predicting wind speed remains challenging due to its inherent randomness, fluctuation, and unpredictability. This study proposes the Temporal Convolutional Network Former (TCNFormer) for short-term (12-hour) wind speed forecasting. The TCNFormer integrates the Temporal Convolutional Network (TCN) and transformer encoder to capture the spatio-temporal features of wind speed. The transformer encoder consists of two distinct attention mechanisms: causal temporal multi-head self-attention (CT-MSA) and temporal external attention (TEA). CT-MSA ensures that the output of a step derives only from previous steps, i.e., causality. Locality is also introduced to improve efficiency. TEA explores potential relationships between different sample sequences in wind speed data. This study utilizes wind speed data from the NASA Prediction of Worldwide Energy Resources (NASA POWER) of Patenga Sea Beach, Chittagong, Bangladesh (latitude 22.2352{\deg} N, longitude 91.7914{\deg} E) over a year (six seasons). The findings indicate that the TCNFormer outperforms state-of-the-art models in prediction accuracy. The proposed TCNFormer presents a promising method for spatio-temporal WSF and may achieve desirable performance in real-world applications of wind power systems.
EAViT: External Attention Vision Transformer for Audio Classification
Aug 23, 2024This paper presents the External Attention Vision Transformer (EAViT) model, a novel approach designed to enhance audio classification accuracy. As digital audio resources proliferate, the demand for precise and efficient audio classification systems has intensified, driven by the need for improved recommendation systems and user personalization in various applications, including music streaming platforms and environmental sound recognition. Accurate audio classification is crucial for organizing vast audio libraries into coherent categories, enabling users to find and interact with their preferred audio content more effectively. In this study, we utilize the GTZAN dataset, which comprises 1,000 music excerpts spanning ten diverse genres. Each 30-second audio clip is segmented into 3-second excerpts to enhance dataset robustness and mitigate overfitting risks, allowing for more granular feature analysis. The EAViT model integrates multi-head external attention (MEA) mechanisms into the Vision Transformer (ViT) framework, effectively capturing long-range dependencies and potential correlations between samples. This external attention (EA) mechanism employs learnable memory units that enhance the network's capacity to process complex audio features efficiently. The study demonstrates that EAViT achieves a remarkable overall accuracy of 93.99%, surpassing state-of-the-art models.
A Vision Transformer-Based Approach to Bearing Fault Classification via Vibration Signals
Aug 15, 2022

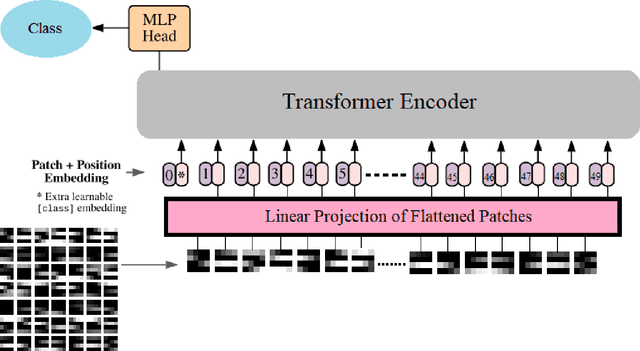
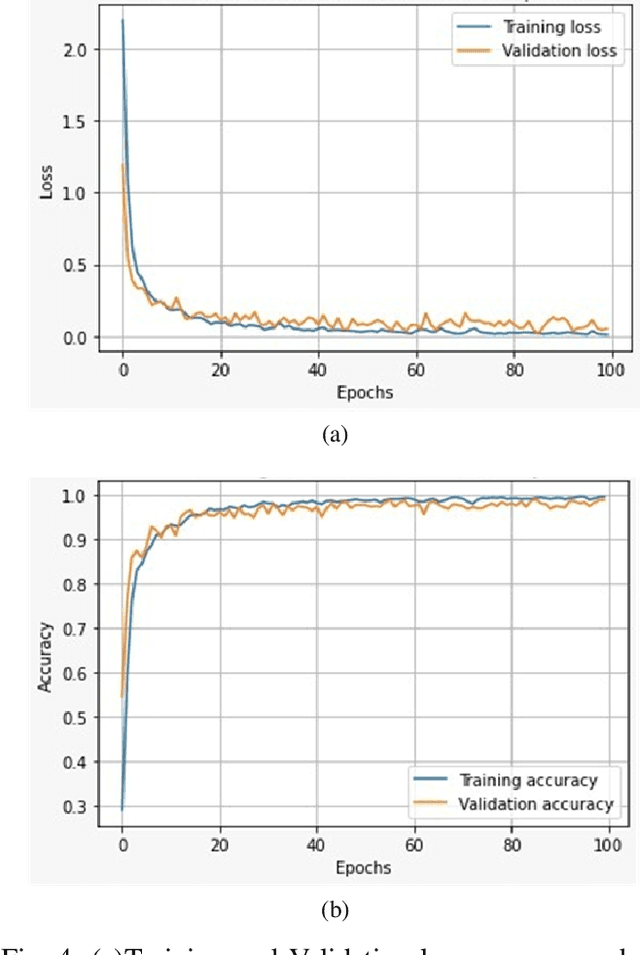
Rolling bearings are the most crucial components of rotating machinery. Identifying defective bearings in a timely manner may prevent the malfunction of an entire machinery system. The mechanical condition monitoring field has entered the big data phase as a result of the fast advancement of machine parts. When working with large amounts of data, the manual feature extraction approach has the drawback of being inefficient and inaccurate. Data-driven methods like the Deep Learning method have been successfully used in recent years for mechanical intelligent fault detection. Convolutional neural networks (CNNs) were mostly used in earlier research to detect and identify bearing faults. The CNN model, however, suffers from the drawback of having trouble managing fault-time information, which results in a lack of classification results. In this study, bearing defects have been classified using a state-of-the-art Vision Transformer (ViT). Bearing defects were classified using Case Western Reserve University (CWRU) bearing failure laboratory experimental data. The research took into account 13 distinct kinds of defects under 0-load situations in addition to normal bearing conditions. Using the short-time Fourier transform (STFT), the vibration signals were converted into 2D time-frequency images. The 2D time-frequency images are used as input parameters for the ViT. The model achieved an overall accuracy of 98.8%.