 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOwnership Verification of DNN Models Using White-Box Adversarial Attacks with Specified Probability Manipulation
May 23, 2025In this paper, we propose a novel framework for ownership verification of deep neural network (DNN) models for image classification tasks. It allows verification of model identity by both the rightful owner and third party without presenting the original model. We assume a gray-box scenario where an unauthorized user owns a model that is illegally copied from the original model, provides services in a cloud environment, and the user throws images and receives the classification results as a probability distribution of output classes. The framework applies a white-box adversarial attack to align the output probability of a specific class to a designated value. Due to the knowledge of original model, it enables the owner to generate such adversarial examples. We propose a simple but effective adversarial attack method based on the iterative Fast Gradient Sign Method (FGSM) by introducing control parameters. Experimental results confirm the effectiveness of the identification of DNN models using adversarial attack.
FreeMark: A Non-Invasive White-Box Watermarking for Deep Neural Networks
Sep 16, 2024Deep neural networks (DNNs) have achieved significant success in real-world applications. However, safeguarding their intellectual property (IP) remains extremely challenging. Existing DNN watermarking for IP protection often require modifying DNN models, which reduces model performance and limits their practicality. This paper introduces FreeMark, a novel DNN watermarking framework that leverages cryptographic principles without altering the original host DNN model, thereby avoiding any reduction in model performance. Unlike traditional DNN watermarking methods, FreeMark innovatively generates secret keys from a pre-generated watermark vector and the host model using gradient descent. These secret keys, used to extract watermark from the model's activation values, are securely stored with a trusted third party, enabling reliable watermark extraction from suspect models. Extensive experiments demonstrate that FreeMark effectively resists various watermark removal attacks while maintaining high watermark capacity.
EAViT: External Attention Vision Transformer for Audio Classification
Aug 23, 2024This paper presents the External Attention Vision Transformer (EAViT) model, a novel approach designed to enhance audio classification accuracy. As digital audio resources proliferate, the demand for precise and efficient audio classification systems has intensified, driven by the need for improved recommendation systems and user personalization in various applications, including music streaming platforms and environmental sound recognition. Accurate audio classification is crucial for organizing vast audio libraries into coherent categories, enabling users to find and interact with their preferred audio content more effectively. In this study, we utilize the GTZAN dataset, which comprises 1,000 music excerpts spanning ten diverse genres. Each 30-second audio clip is segmented into 3-second excerpts to enhance dataset robustness and mitigate overfitting risks, allowing for more granular feature analysis. The EAViT model integrates multi-head external attention (MEA) mechanisms into the Vision Transformer (ViT) framework, effectively capturing long-range dependencies and potential correlations between samples. This external attention (EA) mechanism employs learnable memory units that enhance the network's capacity to process complex audio features efficiently. The study demonstrates that EAViT achieves a remarkable overall accuracy of 93.99%, surpassing state-of-the-art models.
Image-Based Virtual Try-on System With Clothing-Size Adjustment
Feb 27, 2023



The conventional image-based virtual try-on method cannot generate fitting images that correspond to the clothing size because the system cannot accurately reflect the body information of a person. In this study, an image-based virtual try-on system that could adjust the clothing size was proposed. The size information of the person and clothing were used as the input for the proposed method to visualize the fitting of various clothing sizes in a virtual space. First, the distance between the shoulder width and height of the clothing in the person image is calculated based on the coordinate information of the key points detected by OpenPose. Then, the system changes the size of only the clothing area of the segmentation map, whose layout is estimated using the size of the person measured in the person image based on the ratio of the person and clothing sizes. If the size of the clothing area increases during the drawing, the details in the collar and overlapping areas are corrected to improve visual appearance.
HDR image watermarking using saliency detection and quantization index modulation
Feb 23, 2023High-dynamic range (HDR) images are circulated rapidly over the internet with risks of being exploited for unauthorized usage. To protect these images, some HDR image based watermarking (HDR-IW) methods were put forward. However, they inherited the same problem faced by conventional IW methods for standard dynamic range (SDR) images, where only trade-offs among conflicting requirements are managed instead of simultaneous improvement. In this paper, a novel saliency (eye-catching object) detection based trade-off independent HDR-IW is proposed, to simultaneously improve robustness, imperceptibility and payload. First, the host image goes through our proposed salient object detection model to produce a saliency map, which is, in turn, exploited to segment the foreground and background of the host image. Next, the binary watermark is partitioned into the foregrounds and backgrounds using the same mask and scrambled using a random permutation algorithm. Finally, the watermark segments are embedded into selected bit-plane of the corresponding host segments using quantized indexed modulation. Experimental results suggest that the proposed work outperforms state-of-the-art methods in terms of improving the conflicting requirements.
A Vision Transformer-Based Approach to Bearing Fault Classification via Vibration Signals
Aug 15, 2022

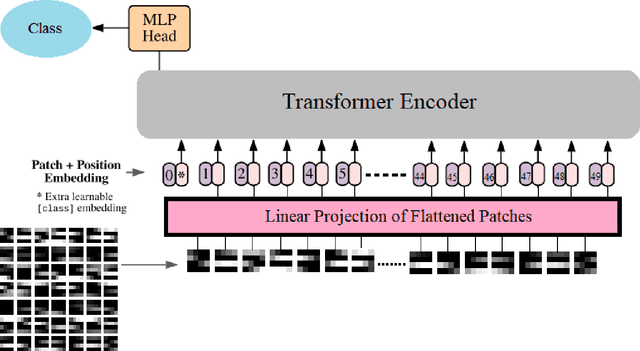
Rolling bearings are the most crucial components of rotating machinery. Identifying defective bearings in a timely manner may prevent the malfunction of an entire machinery system. The mechanical condition monitoring field has entered the big data phase as a result of the fast advancement of machine parts. When working with large amounts of data, the manual feature extraction approach has the drawback of being inefficient and inaccurate. Data-driven methods like the Deep Learning method have been successfully used in recent years for mechanical intelligent fault detection. Convolutional neural networks (CNNs) were mostly used in earlier research to detect and identify bearing faults. The CNN model, however, suffers from the drawback of having trouble managing fault-time information, which results in a lack of classification results. In this study, bearing defects have been classified using a state-of-the-art Vision Transformer (ViT). Bearing defects were classified using Case Western Reserve University (CWRU) bearing failure laboratory experimental data. The research took into account 13 distinct kinds of defects under 0-load situations in addition to normal bearing conditions. Using the short-time Fourier transform (STFT), the vibration signals were converted into 2D time-frequency images. The 2D time-frequency images are used as input parameters for the ViT. The model achieved an overall accuracy of 98.8%.
Immunization of Pruning Attack in DNN Watermarking Using Constant Weight Code
Jul 07, 2021
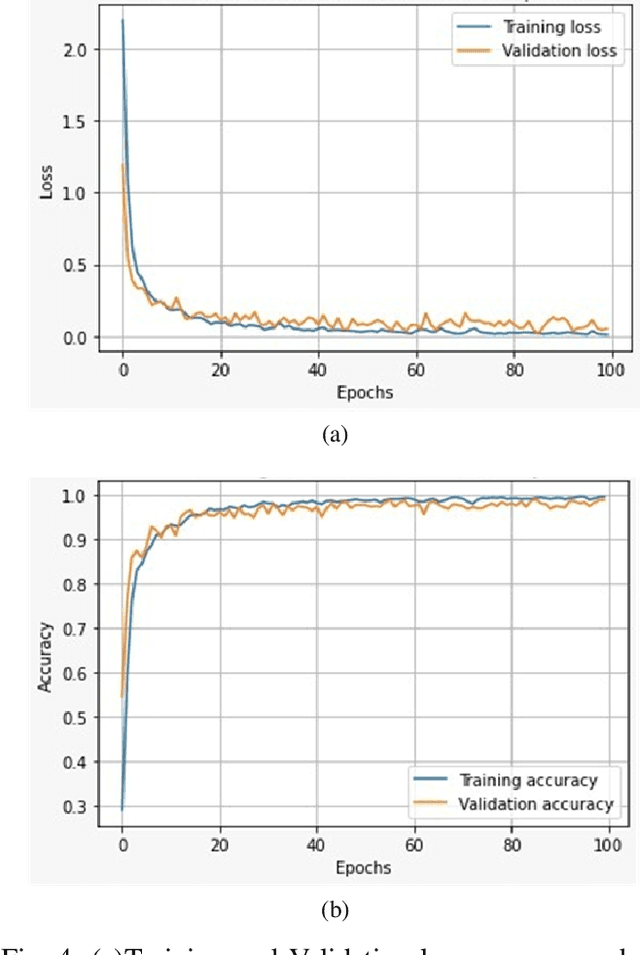
To ensure protection of the intellectual property rights of DNN models, watermarking techniques have been investigated to insert side-information into the models without seriously degrading the performance of original task. One of the threats for the DNN watermarking is the pruning attack such that less important neurons in the model are pruned to make it faster and more compact as well as to remove the watermark. In this study, we investigate a channel coding approach to resist the pruning attack. As the channel model is completely different from conventional models like digital images, it has been an open problem what kind of encoding method is suitable for DNN watermarking. A novel encoding approach by using constant weight codes to immunize the effects of pruning attacks is presented. To the best of our knowledge, this is the first study that introduces an encoding technique for DNN watermarking to make it robust against pruning attacks.
Detecting and Correcting Adversarial Images Using Image Processing Operations
Dec 30, 2019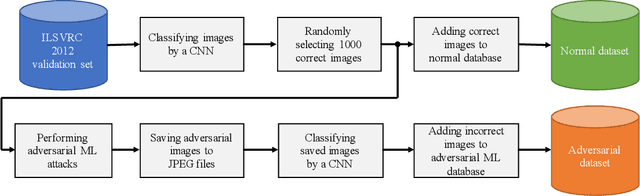
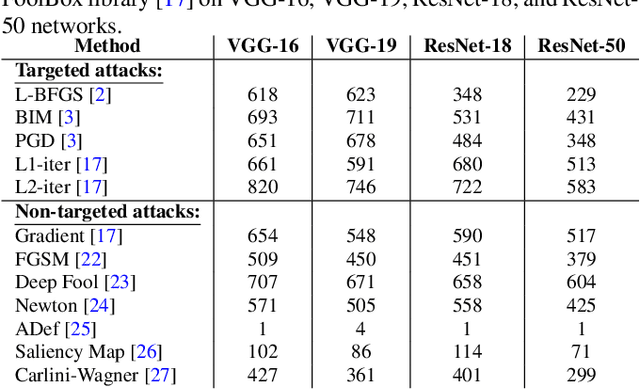

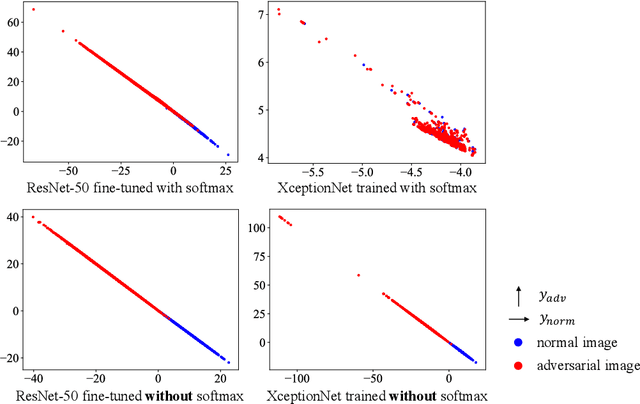
Deep neural networks (DNNs) have achieved excellent performance on several tasks and have been widely applied in both academia and industry. However, DNNs are vulnerable to adversarial machine learning attacks, in which noise is added to the input to change the network output. We have devised an image-processing-based method to detect adversarial images based on our observation that adversarial noise is reduced after applying these operations while the normal images almost remain unaffected. In addition to detection, this method can be used to restore the adversarial images' original labels, which is crucial to restoring the normal functionalities of DNN-based systems. Testing using an adversarial machine learning database we created for generating several types of attack using images from the ImageNet Large Scale Visual Recognition Challenge database demonstrated the efficiency of our proposed method for both detection and correction.