 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TCNFormer: Temporal Convolutional Network Former for Short-Term Wind Speed Forecasting
Aug 27, 2024



Global environmental challenges and rising energy demands have led to extensive exploration of wind energy technologies. Accurate wind speed forecasting (WSF) is crucial for optimizing wind energy capture and ensuring system stability. However, predicting wind speed remains challenging due to its inherent randomness, fluctuation, and unpredictability. This study proposes the Temporal Convolutional Network Former (TCNFormer) for short-term (12-hour) wind speed forecasting. The TCNFormer integrates the Temporal Convolutional Network (TCN) and transformer encoder to capture the spatio-temporal features of wind speed. The transformer encoder consists of two distinct attention mechanisms: causal temporal multi-head self-attention (CT-MSA) and temporal external attention (TEA). CT-MSA ensures that the output of a step derives only from previous steps, i.e., causality. Locality is also introduced to improve efficiency. TEA explores potential relationships between different sample sequences in wind speed data. This study utilizes wind speed data from the NASA Prediction of Worldwide Energy Resources (NASA POWER) of Patenga Sea Beach, Chittagong, Bangladesh (latitude 22.2352{\deg} N, longitude 91.7914{\deg} E) over a year (six seasons). The findings indicate that the TCNFormer outperforms state-of-the-art models in prediction accuracy. The proposed TCNFormer presents a promising method for spatio-temporal WSF and may achieve desirable performance in real-world applications of wind power systems.
MIM-GAN-based Anomaly Detection for Multivariate Time Series Data
Oct 26, 2023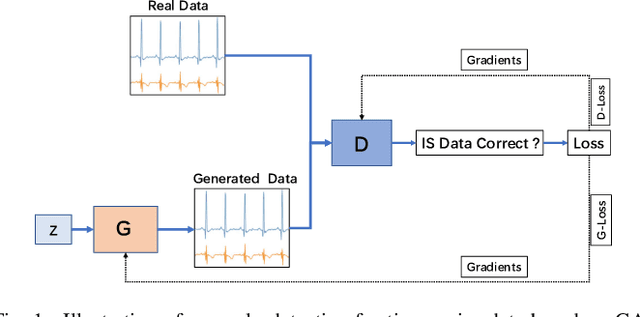
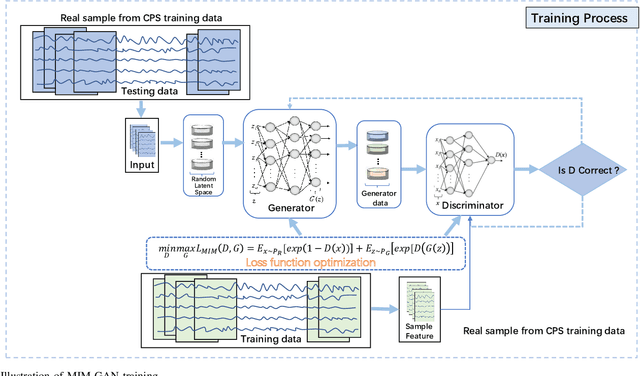
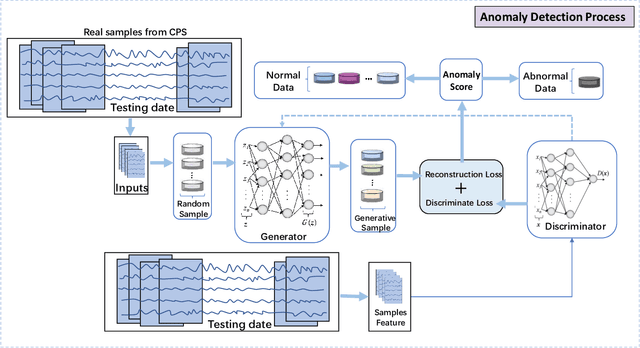
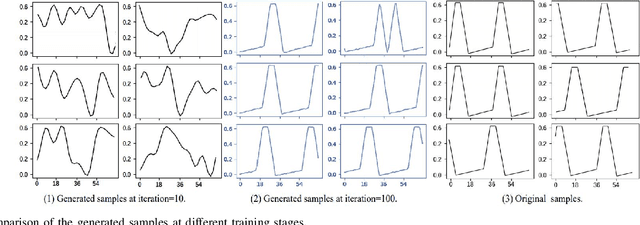
The loss function of Generative adversarial network(GAN) is an important factor that affects the quality and diversity of the generated samples for anomaly detection. In this paper, we propose an unsupervised multiple time series anomaly detection algorithm based on the GAN with message importance measure(MIM-GAN). In particular, the time series data is divided into subsequences using a sliding window. Then a generator and a discriminator designed based on the Long Short-Term Memory (LSTM) are employed to capture the temporal correlations of the time series data. To avoid the local optimal solution of loss function and the model collapse, we introduce an exponential information measure into the loss function of GAN. Additionally, a discriminant reconstruction score consisting on discrimination and reconstruction loss is taken into account. The global optimal solution for the loss function is derived and the model collapse is proved to be avoided in our proposed MIM-GAN-based anomaly detection algorithm. Experimental results show that the proposed MIM-GAN-based anomaly detection algorithm has superior performance in terms of precision, recall, and F1 score.
PRSNet: A Masked Self-Supervised Learning Pedestrian Re-Identification Method
Mar 11, 2023



In recent years, self-supervised learning has attracted widespread academic debate and addressed many of the key issues of computer vision. The present research focus is on how to construct a good agent task that allows for improved network learning of advanced semantic information on images so that model reasoning is accelerated during pre-training of the current task. In order to solve the problem that existing feature extraction networks are pre-trained on the ImageNet dataset and cannot extract the fine-grained information in pedestrian images well, and the existing pre-task of contrast self-supervised learning may destroy the original properties of pedestrian images, this paper designs a pre-task of mask reconstruction to obtain a pre-training model with strong robustness and uses it for the pedestrian re-identification task. The training optimization of the network is performed by improving the triplet loss based on the centroid, and the mask image is added as an additional sample to the loss calculation, so that the network can better cope with the pedestrian matching in practical applications after the training is completed. This method achieves about 5% higher mAP on Marker1501 and CUHK03 data than existing self-supervised learning pedestrian re-identification methods, and about 1% higher for Rank1, and ablation experiments are conducted to demonstrate the feasibility of this method. Our model code is located at https://github.com/ZJieX/prsnet.
Two-Stage Channel Estimation Approach for Cell-Free IoT With Massive Random Access
Sep 28, 2021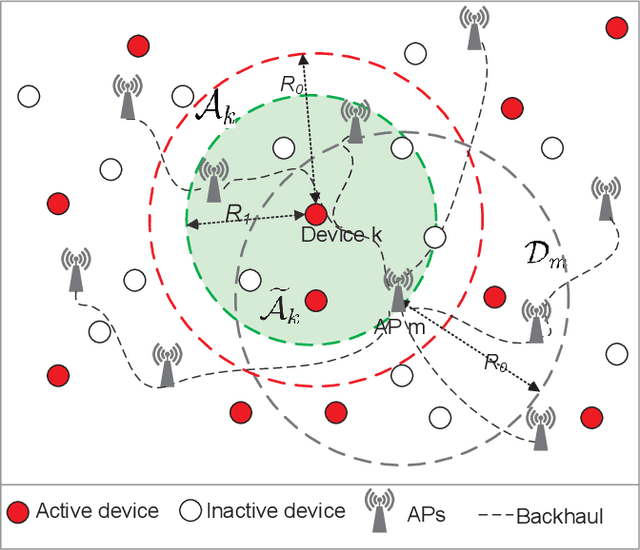
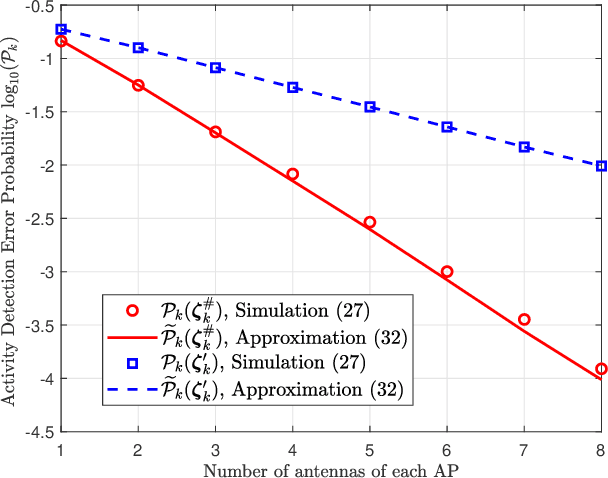
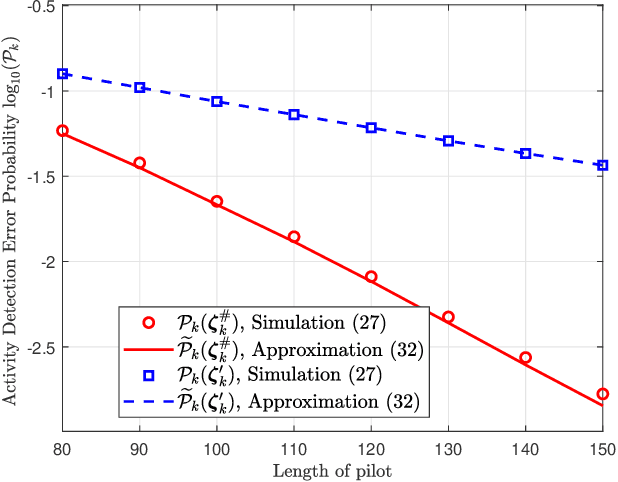
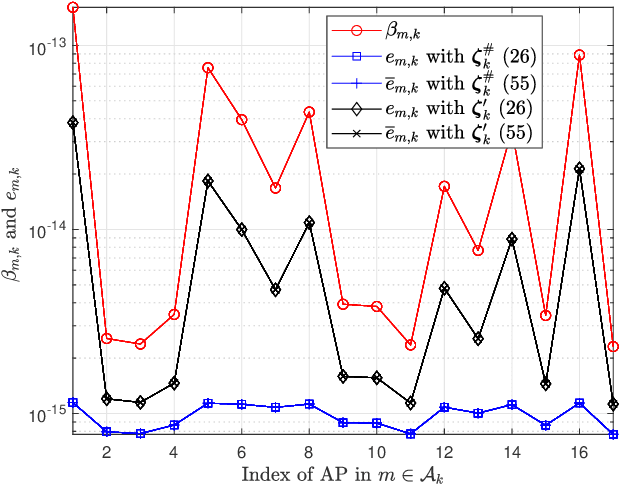
We investigate the activity detection and channel estimation issues for cell-free Internet of Things (IoT) networks with massive random access. In each time slot, only partial devices are active and communicate with neighboring access points (APs) using non-orthogonal random pilot sequences. Different from the centralized processing in cellular networks, the activity detection and channel estimation in cell-free IoT is more challenging due to the distributed and user-centric architecture. We propose a two-stage approach to detect the random activities of devices and estimate their channel states. In the first stage, the activity of each device is jointly detected by its adjacent APs based on the vector approximate message passing (Vector AMP) algorithm. In the second stage, each AP re-estimates the channel using the linear minimum mean square error (LMMSE) method based on the detected activities to improve the channel estimation accuracy. We derive closed-form expressions for the activity detection error probability and the mean-squared channel estimation errors for a typical device. Finally, we analyze the performance of the entire cell-free IoT network in terms of coverage probability. Simulation results validate the derived closed-form expressions and show that the cell-free IoT significantly outperforms the collocated massive MIMO and small-cell schemes in terms of coverage probability.
Deep High-Resolution Representation Learning for Cross-Resolution Person Re-identification
May 25, 2021
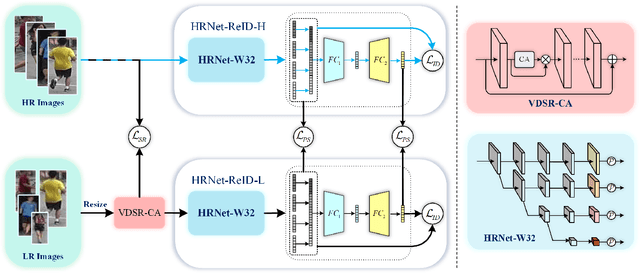
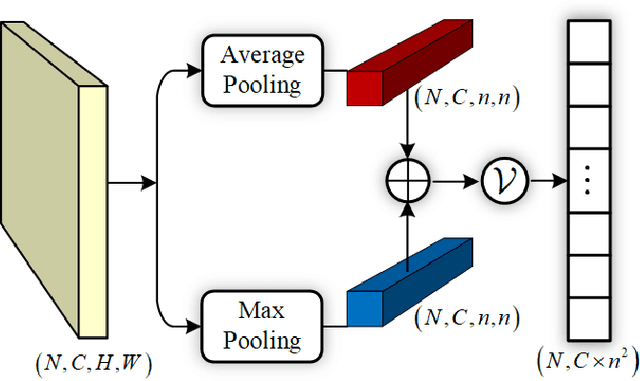
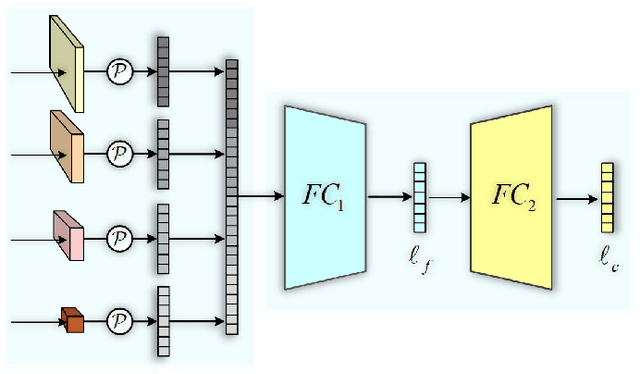
Person re-identification (re-ID) tackles the problem of matching person images with the same identity from different cameras. In practical applications, due to the differences in camera performance and distance between cameras and persons of interest, captured person images usually have various resolutions. We name this problem as Cross-Resolution Person Re-identification which brings a great challenge for matching correctly. In this paper, we propose a Deep High-Resolution Pseudo-Siamese Framework (PS-HRNet) to solve the above problem. Specifically, in order to restore the resolution of low-resolution images and make reasonable use of different channel information of feature maps, we introduce and innovate VDSR module with channel attention (CA) mechanism, named as VDSR-CA. Then we reform the HRNet by designing a novel representation head to extract discriminating features, named as HRNet-ReID. In addition, a pseudo-siamese framework is constructed to reduce the difference of feature distributions between low-resolution images and high-resolution images. The experimental results on five cross-resolution person datasets verify the effectiveness of our proposed approach. Compared with the state-of-the-art methods, our proposed PS-HRNet improves 3.4\%, 6.2\%, 2.5\%,1.1\% and 4.2\% at Rank-1 on MLR-Market-1501, MLR-CUHK03, MLR-VIPeR, MLR-DukeMTMC-reID, and CAVIAR datasets, respectively. Our code is available at \url{https://github.com/zhguoqing}.