 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility Study of VLC-Based Collective Perception for Vehicular Communication
May 22, 2026This study explores the use of Visible Light Communication (VLC) in Collective Perception (CP), a technology that enables vehicles and infrastructure to share sensor information to help reduce traffic accidents. Recent advances in Vehicle-to-Everything (V2X) communication have spurred growing research interest in CP. However, in regions such as the United States and Japan, only 30 MHz of radio spectrum is allocated for V2X, which is insufficient to effectively support CP. In this paper, we propose integrating VLC into V2X systems to enhance CP, complementing the existing 5.9 GHz band for V2X communications. VLC can coexist with wireless systems that use radio waves, providing an additional optical channel for data exchange. To the best of the authors' knowledge, this is the first study to investigate VLC for CP. We evaluate the feasibility of VLC-based CP through three experiments. First, we measured the application-level delay of a VLC-based CP system in a stationary indoor environment. Next, we evaluated its communication range in a stationary outdoor setting. Finally, to assess robustness under realistic conditions, we conducted driving experiments at vehicle speeds up to 90 km/h. The results demonstrate that VLC-based CP is feasible and could serve as a promising solution to spectrum scarcity in the 5.9 GHz band for future V2X communications.
* 6 pages, 7 figures
Deep-Learning-Aided Successive Cancellation List Flip Decoding for Polar Codes
May 22, 2026Polar codes are the first error-correcting code proven to achieve channel capacity based on infinite code length. The Successive Cancellation List Flip (SCLF) decoding algorithm was proposed by flipping an erroneous bit during the next decoding attempt. To identify the erroneous bits, the Log-Likelihood Ratio (LLR) is used to indicate the reliability of each decision bit. To improve the accuracy of the erroneous bit prediction, we propose deep-learning-aided (DL-aided) SCLF decoding algorithms. We first offer a stacked LSTM network that contains new features to train our models, which are able to improve the accuracy of the prediction of positions of erroneous bits. Then we separately train the stacked LSTM models to predict the position of both the first and second erroneous bits and whether to continue flipping. As a result, the DL-aided SCLF decoding algorithms based on the proposed stacked LSTM \mbox{flip-1} model, stacked LSTM \mbox{flip-2} model, and the stacked LSTM \mbox{continue-flipping} check (CFC) model are able to provide a better performance at a lower number of average decoding attempts when compared to other state-of-the-art decoding algorithms.
ExVerus: Verus Proof Repair via Counterexample Reasoning
Mar 26, 2026Large Language Models (LLMs) have shown promising results in automating formal verification. However, existing approaches treat proof generation as a static, end-to-end prediction over source code, relying on limited verifier feedback and lacking access to concrete program behaviors. We present EXVERUS, a counterexample-guided framework that enables LLMs to reason about proofs using behavioral feedback via counterexamples. When a proof fails, EXVERUS automatically generates and validates counterexamples, and then guides the LLM to generalize them into inductive invariants to block these failures. Our evaluation shows that EXVERUS significantly improves proof accuracy, robustness, and token efficiency over the state-of-the-art prompting-based Verus proof generator.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
VeruSAGE: A Study of Agent-Based Verification for Rust Systems
Dec 20, 2025Large language models (LLMs) have shown impressive capability to understand and develop code. However, their capability to rigorously reason about and prove code correctness remains in question. This paper offers a comprehensive study of LLMs' capability to develop correctness proofs for system software written in Rust. We curate a new system-verification benchmark suite, VeruSAGE-Bench, which consists of 849 proof tasks extracted from eight open-source Verus-verified Rust systems. Furthermore, we design different agent systems to match the strengths and weaknesses of different LLMs (o4-mini, GPT-5, Sonnet 4, and Sonnet 4.5). Our study shows that different tools and agent settings are needed to stimulate the system-verification capability of different types of LLMs. The best LLM-agent combination in our study completes over 80% of system-verification tasks in VeruSAGE-Bench. It also completes over 90% of a set of system proof tasks not part of VeruSAGE-Bench because they had not yet been finished by human experts. This result shows the great potential for LLM-assisted development of verified system software.
Distance Estimation in Outdoor Driving Environments Using Phase-only Correlation Method with Event Cameras
May 23, 2025With the growing adoption of autonomous driving, the advancement of sensor technology is crucial for ensuring safety and reliable operation. Sensor fusion techniques that combine multiple sensors such as LiDAR, radar, and cameras have proven effective, but the integration of multiple devices increases both hardware complexity and cost. Therefore, developing a single sensor capable of performing multiple roles is highly desirable for cost-efficient and scalable autonomous driving systems. Event cameras have emerged as a promising solution due to their unique characteristics, including high dynamic range, low latency, and high temporal resolution. These features enable them to perform well in challenging lighting conditions, such as low-light or backlit environments. Moreover, their ability to detect fine-grained motion events makes them suitable for applications like pedestrian detection and vehicle-to-infrastructure communication via visible light. In this study, we present a method for distance estimation using a monocular event camera and a roadside LED bar. By applying a phase-only correlation technique to the event data, we achieve sub-pixel precision in detecting the spatial shift between two light sources. This enables accurate triangulation-based distance estimation without requiring stereo vision. Field experiments conducted in outdoor driving scenarios demonstrated that the proposed approach achieves over 90% success rate with less than 0.5-meter error for distances ranging from 20 to 60 meters. Future work includes extending this method to full position estimation by leveraging infrastructure such as smart poles equipped with LEDs, enabling event-camera-based vehicles to determine their own position in real time. This advancement could significantly enhance navigation accuracy, route optimization, and integration into intelligent transportation systems.
Evaluation of Mobile Environment for Vehicular Visible Light Communication Using Multiple LEDs and Event Cameras
May 21, 2025In the fields of Advanced Driver Assistance Systems (ADAS) and Autonomous Driving (AD), sensors that serve as the ``eyes'' for sensing the vehicle's surrounding environment are essential. Traditionally, image sensors and LiDAR have played this role. However, a new type of vision sensor, event cameras, has recently attracted attention. Event cameras respond to changes in the surrounding environment (e.g., motion), exhibit strong robustness against motion blur, and perform well in high dynamic range environments, which are desirable in robotics applications. Furthermore, the asynchronous and low-latency principles of data acquisition make event cameras suitable for optical communication. By adding communication functionality to event cameras, it becomes possible to utilize I2V communication to immediately share information about forward collisions, sudden braking, and road conditions, thereby contributing to hazard avoidance. Additionally, receiving information such as signal timing and traffic volume enables speed adjustment and optimal route selection, facilitating more efficient driving. In this study, we construct a vehicle visible light communication system where event cameras are receivers, and multiple LEDs are transmitters. In driving scenes, the system tracks the transmitter positions and separates densely packed LED light sources using pilot sequences based on Walsh-Hadamard codes. As a result, outdoor vehicle experiments demonstrate error-free communication under conditions where the transmitter-receiver distance was within 40 meters and the vehicle's driving speed was 30 km/h (8.3 m/s).
MAS-Attention: Memory-Aware Stream Processing for Attention Acceleration on Resource-Constrained Edge Devices
Nov 20, 2024



The advent of foundation models have revolutionized various fields, enabling unprecedented task accuracy and flexibility in computational linguistics, computer vision and other domains. Attention mechanism has become an essential component of foundation models, due to their superb capability of capturing correlations in a sequence. However, attention results in quadratic complexity in memory and compute as the context length grows. Although many fusion-based exact attention acceleration algorithms have been developed for datacenter-grade GPUs and accelerators leveraging multi-core parallelism and data locality, yet it remains a significant challenge to accelerate attention on resource-constrained edge neural accelerators with limited compute units and stringent on-chip caches. In this paper, we propose a scheme for exact attention inference acceleration on memory-constrained edge accelerators, by parallelizing the utilization of heterogeneous compute units, i.e., vector processing units and matrix processing units. Our method involves scheduling workloads onto these different compute units in a multi-tiered tiling scheme to process tiled vector workloads and matrix workloads in attention as two streams, respecting the workload dependencies. We search for tiling factors to maximize the parallelization of both compute units while considering I/O overhead, and propose a proactive cache overwrite strategy to avoid undesirable cache spills in reality. Extensive results based on open-sourced simulation frameworks show up to 2.75x speedup and 54% reduction in energy consumption as compared to the state-of-the-art attention fusion method (FLAT) in the edge computing scenario. Further experiments on a real-world edge neural processing unit demonstrate speedup of up to 1.76x for attention as compared to FLAT, without affecting model output accuracy.
DroidSpeak: Enhancing Cross-LLM Communication
Nov 05, 2024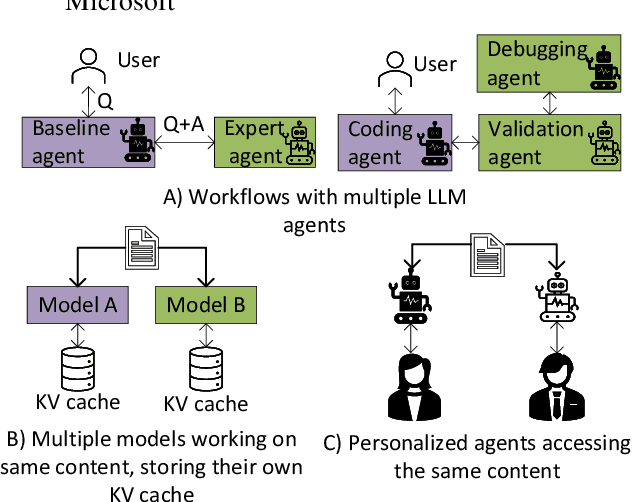

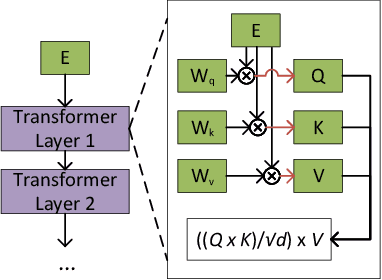
In multi-agent systems utilizing Large Language Models (LLMs), communication between agents traditionally relies on natural language. This communication often includes the full context of the query so far, which can introduce significant prefill-phase latency, especially with long contexts. We introduce DroidSpeak, a novel framework to target this cross-LLM communication by leveraging the reuse of intermediate data, such as input embeddings (E-cache) and key-value caches (KV-cache). We efficiently bypass the need to reprocess entire contexts for fine-tuned versions of the same foundational model. This approach allows faster context integration while maintaining the quality of task performance. Experimental evaluations demonstrate DroidSpeak's ability to significantly accelerate inter-agent communication, achieving up to a 2.78x speedup in prefill latency with negligible loss in accuracy. Our findings underscore the potential to create more efficient and scalable multi-agent systems.
Automated Proof Generation for Rust Code via Self-Evolution
Oct 21, 2024



Ensuring correctness is crucial for code generation. Formal verification offers a definitive assurance of correctness, but demands substantial human effort in proof construction and hence raises a pressing need for automation. The primary obstacle lies in the severe lack of data - there is much less proof than code for LLMs to train upon. In this paper, we introduce SAFE, a novel framework that overcomes the lack of human-written proof to enable automated proof generation of Rust code. SAFE establishes a self-evolving cycle where data synthesis and fine-tuning collaborate to enhance the model capability, leveraging the definitive power of a symbolic verifier in telling correct proof from incorrect ones. SAFE also re-purposes the large number of synthesized incorrect proofs to train the self-debugging capability of the fine-tuned models, empowering them to fix incorrect proofs based on the verifier's feedback. SAFE demonstrates superior efficiency and precision compared to GPT-4o. Through tens of thousands of synthesized proofs and the self-debugging mechanism, we improve the capability of open-source models, initially unacquainted with formal verification, to automatically write proof for Rust code. This advancement leads to a significant improvement in performance, achieving a 70.50% accuracy rate in a benchmark crafted by human experts, a significant leap over GPT-4o's performance of 24.46%.