 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDroidSpeak: Enhancing Cross-LLM Communication
Paper and Code
Nov 05, 2024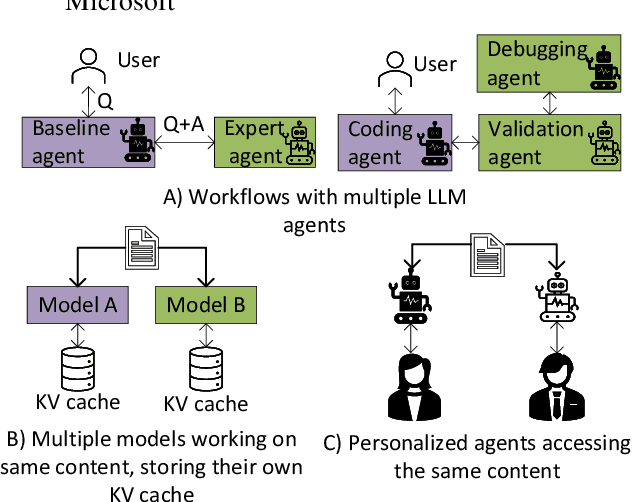

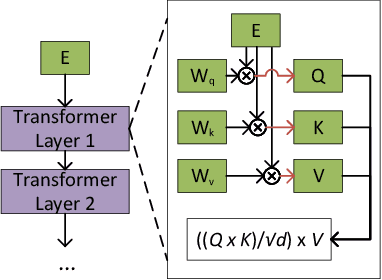
In multi-agent systems utilizing Large Language Models (LLMs), communication between agents traditionally relies on natural language. This communication often includes the full context of the query so far, which can introduce significant prefill-phase latency, especially with long contexts. We introduce DroidSpeak, a novel framework to target this cross-LLM communication by leveraging the reuse of intermediate data, such as input embeddings (E-cache) and key-value caches (KV-cache). We efficiently bypass the need to reprocess entire contexts for fine-tuned versions of the same foundational model. This approach allows faster context integration while maintaining the quality of task performance. Experimental evaluations demonstrate DroidSpeak's ability to significantly accelerate inter-agent communication, achieving up to a 2.78x speedup in prefill latency with negligible loss in accuracy. Our findings underscore the potential to create more efficient and scalable multi-agent systems.