 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Visual Genome
Jun 09, 2025Reasoning over visual relationships-spatial, functional, interactional, social, etc.-is considered to be a fundamental component of human cognition. Yet, despite the major advances in visual comprehension in multimodal language models (MLMs), precise reasoning over relationships and their generations remains a challenge. We introduce ROBIN: an MLM instruction-tuned with densely annotated relationships capable of constructing high-quality dense scene graphs at scale. To train ROBIN, we curate SVG, a synthetic scene graph dataset by completing the missing relations of selected objects in existing scene graphs using a teacher MLM and a carefully designed filtering process to ensure high-quality. To generate more accurate and rich scene graphs at scale for any image, we introduce SG-EDIT: a self-distillation framework where GPT-4o further refines ROBIN's predicted scene graphs by removing unlikely relations and/or suggesting relevant ones. In total, our dataset contains 146K images and 5.6M relationships for 2.6M objects. Results show that our ROBIN-3B model, despite being trained on less than 3 million instances, outperforms similar-size models trained on over 300 million instances on relationship understanding benchmarks, and even surpasses larger models up to 13B parameters. Notably, it achieves state-of-the-art performance in referring expression comprehension with a score of 88.9, surpassing the previous best of 87.4. Our results suggest that training on the refined scene graph data is crucial to maintaining high performance across diverse visual reasoning task.
One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory
May 29, 2025Effective video tokenization is critical for scaling transformer models for long videos. Current approaches tokenize videos using space-time patches, leading to excessive tokens and computational inefficiencies. The best token reduction strategies degrade performance and barely reduce the number of tokens when the camera moves. We introduce grounded video tokenization, a paradigm that organizes tokens based on panoptic sub-object trajectories rather than fixed patches. Our method aligns with fundamental perceptual principles, ensuring that tokenization reflects scene complexity rather than video duration. We propose TrajViT, a video encoder that extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence. Trained with contrastive learning, TrajViT significantly outperforms space-time ViT (ViT3D) across multiple video understanding benchmarks, e.g., TrajViT outperforms ViT3D by a large margin of 6% top-5 recall in average at video-text retrieval task with 10x token deduction. We also show TrajViT as a stronger model than ViT3D for being the video encoder for modern VideoLLM, obtaining an average of 5.2% performance improvement across 6 VideoQA benchmarks while having 4x faster training time and 18x less inference FLOPs. TrajViT is the first efficient encoder to consistently outperform ViT3D across diverse video analysis tasks, making it a robust and scalable solution.
Distance Estimation in Outdoor Driving Environments Using Phase-only Correlation Method with Event Cameras
May 23, 2025With the growing adoption of autonomous driving, the advancement of sensor technology is crucial for ensuring safety and reliable operation. Sensor fusion techniques that combine multiple sensors such as LiDAR, radar, and cameras have proven effective, but the integration of multiple devices increases both hardware complexity and cost. Therefore, developing a single sensor capable of performing multiple roles is highly desirable for cost-efficient and scalable autonomous driving systems. Event cameras have emerged as a promising solution due to their unique characteristics, including high dynamic range, low latency, and high temporal resolution. These features enable them to perform well in challenging lighting conditions, such as low-light or backlit environments. Moreover, their ability to detect fine-grained motion events makes them suitable for applications like pedestrian detection and vehicle-to-infrastructure communication via visible light. In this study, we present a method for distance estimation using a monocular event camera and a roadside LED bar. By applying a phase-only correlation technique to the event data, we achieve sub-pixel precision in detecting the spatial shift between two light sources. This enables accurate triangulation-based distance estimation without requiring stereo vision. Field experiments conducted in outdoor driving scenarios demonstrated that the proposed approach achieves over 90% success rate with less than 0.5-meter error for distances ranging from 20 to 60 meters. Future work includes extending this method to full position estimation by leveraging infrastructure such as smart poles equipped with LEDs, enabling event-camera-based vehicles to determine their own position in real time. This advancement could significantly enhance navigation accuracy, route optimization, and integration into intelligent transportation systems.
Evaluation of Mobile Environment for Vehicular Visible Light Communication Using Multiple LEDs and Event Cameras
May 21, 2025In the fields of Advanced Driver Assistance Systems (ADAS) and Autonomous Driving (AD), sensors that serve as the ``eyes'' for sensing the vehicle's surrounding environment are essential. Traditionally, image sensors and LiDAR have played this role. However, a new type of vision sensor, event cameras, has recently attracted attention. Event cameras respond to changes in the surrounding environment (e.g., motion), exhibit strong robustness against motion blur, and perform well in high dynamic range environments, which are desirable in robotics applications. Furthermore, the asynchronous and low-latency principles of data acquisition make event cameras suitable for optical communication. By adding communication functionality to event cameras, it becomes possible to utilize I2V communication to immediately share information about forward collisions, sudden braking, and road conditions, thereby contributing to hazard avoidance. Additionally, receiving information such as signal timing and traffic volume enables speed adjustment and optimal route selection, facilitating more efficient driving. In this study, we construct a vehicle visible light communication system where event cameras are receivers, and multiple LEDs are transmitters. In driving scenes, the system tracks the transmitter positions and separates densely packed LED light sources using pilot sequences based on Walsh-Hadamard codes. As a result, outdoor vehicle experiments demonstrate error-free communication under conditions where the transmitter-receiver distance was within 40 meters and the vehicle's driving speed was 30 km/h (8.3 m/s).
GA3CE: Unconstrained 3D Gaze Estimation with Gaze-Aware 3D Context Encoding
May 15, 2025We propose a novel 3D gaze estimation approach that learns spatial relationships between the subject and objects in the scene, and outputs 3D gaze direction. Our method targets unconstrained settings, including cases where close-up views of the subject's eyes are unavailable, such as when the subject is distant or facing away. Previous approaches typically rely on either 2D appearance alone or incorporate limited spatial cues using depth maps in the non-learnable post-processing step. Estimating 3D gaze direction from 2D observations in these scenarios is challenging; variations in subject pose, scene layout, and gaze direction, combined with differing camera poses, yield diverse 2D appearances and 3D gaze directions even when targeting the same 3D scene. To address this issue, we propose GA3CE: Gaze-Aware 3D Context Encoding. Our method represents subject and scene using 3D poses and object positions, treating them as 3D context to learn spatial relationships in 3D space. Inspired by human vision, we align this context in an egocentric space, significantly reducing spatial complexity. Furthermore, we propose D$^3$ (direction-distance-decomposed) positional encoding to better capture the spatial relationship between 3D context and gaze direction in direction and distance space. Experiments demonstrate substantial improvements, reducing mean angle error by 13%-37% compared to leading baselines on benchmark datasets in single-frame settings.
E-VLC: A Real-World Dataset for Event-based Visible Light Communication And Localization
Apr 25, 2025Optical communication using modulated LEDs (e.g., visible light communication) is an emerging application for event cameras, thanks to their high spatio-temporal resolutions. Event cameras can be used simply to decode the LED signals and also to localize the camera relative to the LED marker positions. However, there is no public dataset to benchmark the decoding and localization in various real-world settings. We present, to the best of our knowledge, the first public dataset that consists of an event camera, a frame camera, and ground-truth poses that are precisely synchronized with hardware triggers. It provides various camera motions with various sensitivities in different scene brightness settings, both indoor and outdoor. Furthermore, we propose a novel method of localization that leverages the Contrast Maximization framework for motion estimation and compensation. The detailed analysis and experimental results demonstrate the advantages of LED-based localization with events over the conventional AR-marker--based one with frames, as well as the efficacy of the proposed method in localization. We hope that the proposed dataset serves as a future benchmark for both motion-related classical computer vision tasks and LED marker decoding tasks simultaneously, paving the way to broadening applications of event cameras on mobile devices. https://woven-visionai.github.io/evlc-dataset
Reprojection Errors as Prompts for Efficient Scene Coordinate Regression
Sep 06, 2024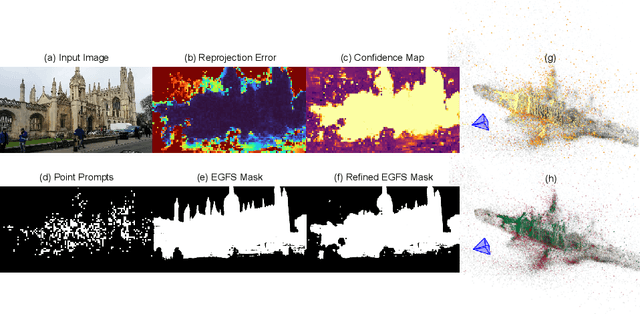
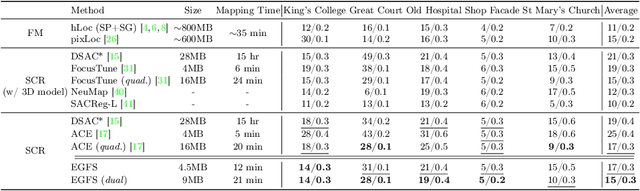
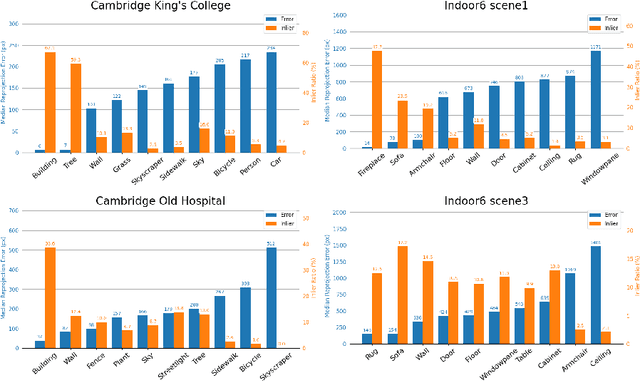
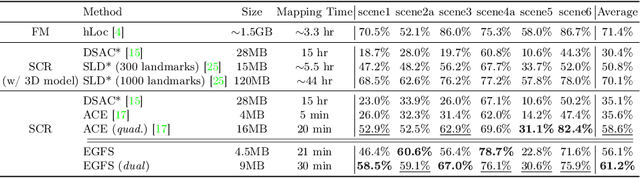
Scene coordinate regression (SCR) methods have emerged as a promising area of research due to their potential for accurate visual localization. However, many existing SCR approaches train on samples from all image regions, including dynamic objects and texture-less areas. Utilizing these areas for optimization during training can potentially hamper the overall performance and efficiency of the model. In this study, we first perform an in-depth analysis to validate the adverse impacts of these areas. Drawing inspiration from our analysis, we then introduce an error-guided feature selection (EGFS) mechanism, in tandem with the use of the Segment Anything Model (SAM). This mechanism seeds low reprojection areas as prompts and expands them into error-guided masks, and then utilizes these masks to sample points and filter out problematic areas in an iterative manner. The experiments demonstrate that our method outperforms existing SCR approaches that do not rely on 3D information on the Cambridge Landmarks and Indoor6 datasets.
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Jul 22, 2024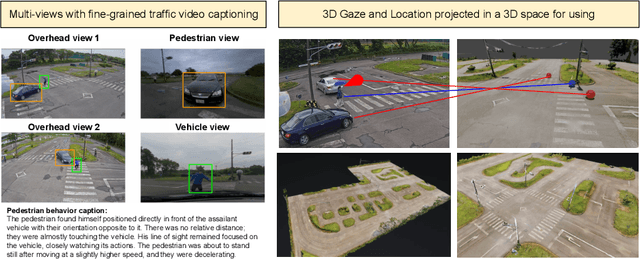
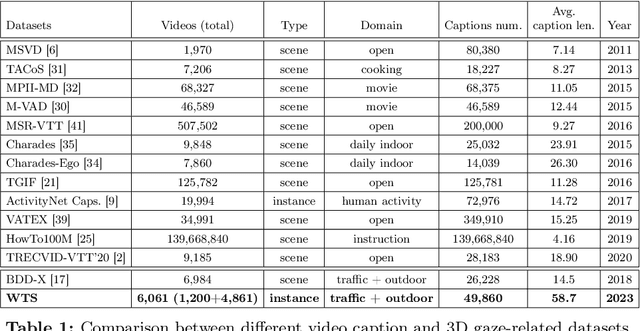
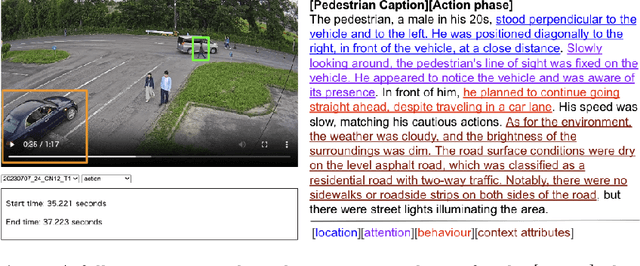
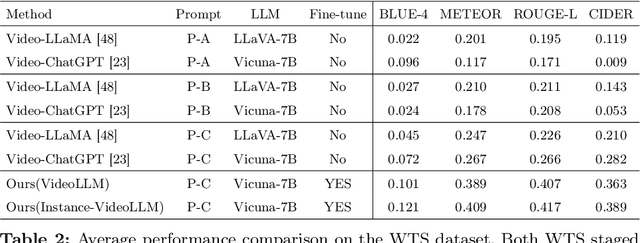
In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.
The 8th AI City Challenge
Apr 15, 2024
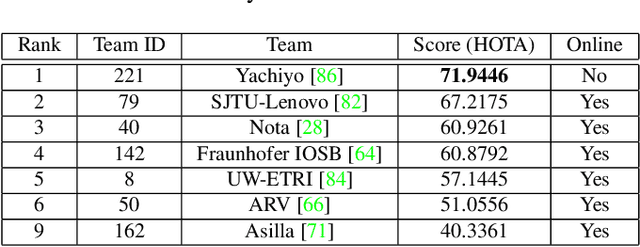

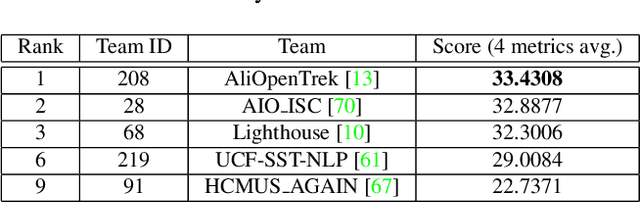
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.