 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaST-Bench: Benchmarking Causal Chain-Grounded Spatio-Temporal Reasoning for Video Question Answering
May 22, 2026Cause-and-effect reasoning in video is a significant challenge for Vision-Language Models (VLMs), as it requires going beyond surface-level perception to a deeper understanding of causal mechanisms. However, existing benchmarks rarely provide the fine-grained, grounded evidence needed to rigorously evaluate this capability. To address this gap, we introduce CaST-Bench, a benchmark for Causal Chain-Grounded Spatio-Temporal Video Reasoning. CaST-Bench presents complex causal questions that require models to identify and localize a chain of multiple spatio-temporal evidences. Through a human-AI collaborative pipeline, we construct a high-quality dataset of 2,066 questions over 1,015 videos, with causal chains annotated by temporal segments and bounding-box tracks. Furthermore, we design a comprehensive evaluation suite with novel metrics that assess not only answer correctness but also the capability for visual evidence grounded reasoning. This grounding is crucial for improving accuracy by mitigating spurious correlations and for enhancing user trust by making models more transparent. Our experiments show that current VLMs struggle with causal questions, largely due to their limited ability to construct precise and grounded causal chains. This highlights an important direction for improving future VLMs.
InstAP: Instance-Aware Vision-Language Pre-Train for Spatial-Temporal Understanding
Apr 09, 2026Current vision-language pre-training (VLP) paradigms excel at global scene understanding but struggle with instance-level reasoning due to global-only supervision. We introduce InstAP, an Instance-Aware Pre-training framework that jointly optimizes global vision-text alignment and fine-grained, instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions. To support this, we present InstVL, a large-scale dataset (2 million images, 50,000 videos) with dual-granularity annotations: holistic scene captions and dense, grounded instance descriptions. On the InstVL benchmark, InstAP substantially outperforms existing VLP models on instance-level retrieval, and also surpasses a strong VLP baseline trained on the exact same data corpus, isolating the benefit of our instance-aware objective. Moreover, instance-centric pre-training improves global understanding: InstAP achieves competitive zero-shot performance on multiple video benchmarks, including MSR-VTT and DiDeMo. Qualitative visualizations further show that InstAP localizes textual mentions to the correct instances, while global-only models exhibit more diffuse, scene-level attention.
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Jul 22, 2024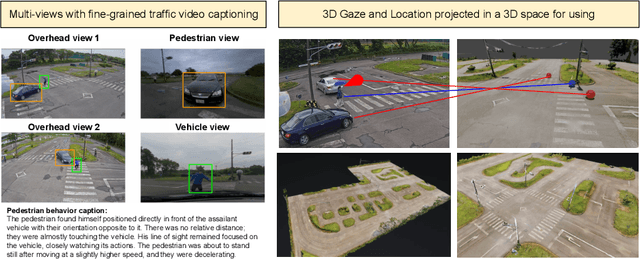
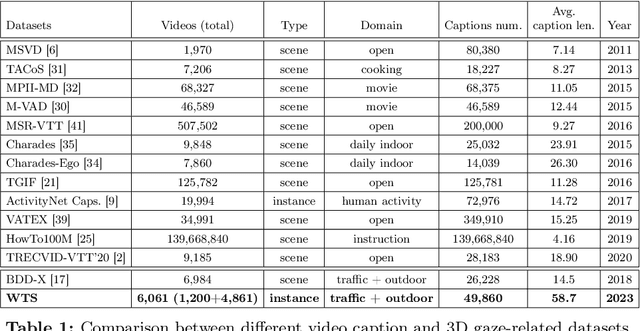
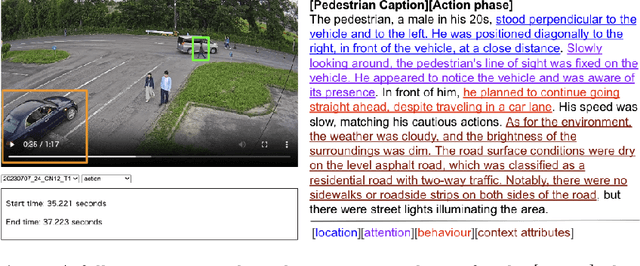
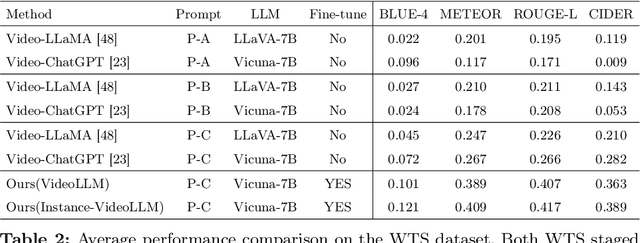
In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.
On the Demystification of Knowledge Distillation: A Residual Network Perspective
Jun 30, 2020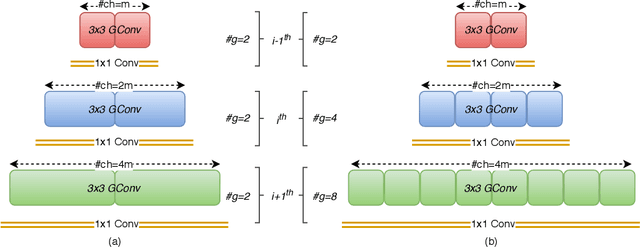
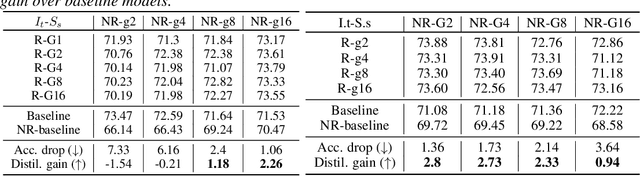
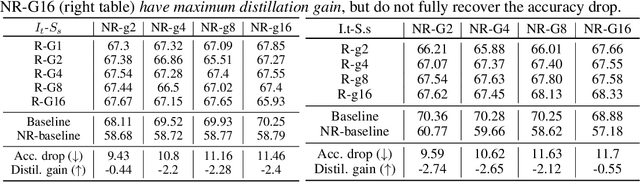
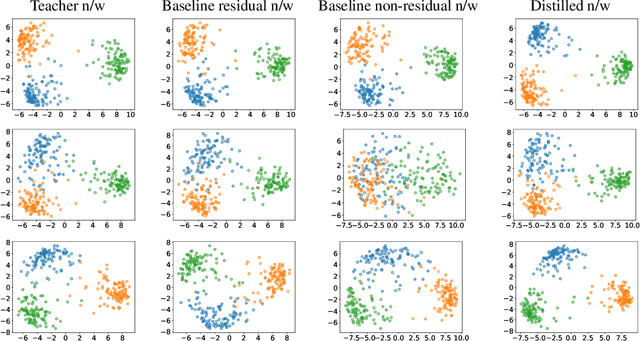
Knowledge distillation (KD) is generally considered as a technique for performing model compression and learned-label smoothing. However, in this paper, we study and investigate the KD approach from a new perspective: we study its efficacy in training a deeper network without any residual connections. We find that in most of the cases, non-residual student networks perform equally or better than their residual versions trained on raw data without KD (baseline network). Surprisingly, in some cases, they surpass the accuracy of baseline networks even with the inferior teachers. After a certain depth of non-residual student network, the accuracy drop, coming from the removal of residual connections, is substantial, and training with KD boosts the accuracy of the student up to a great extent; however, it does not fully recover the accuracy drop. Furthermore, we observe that the conventional teacher-student view of KD is incomplete and does not adequately explain our findings. We propose a novel interpretation of KD with the Trainee-Mentor hypothesis, which provides a holistic view of KD. We also present two viewpoints, loss landscape, and feature reuse, to explain the interplay between residual connections and KD. We substantiate our claims through extensive experiments on residual networks.
ULSAM: Ultra-Lightweight Subspace Attention Module for Compact Convolutional Neural Networks
Jun 26, 2020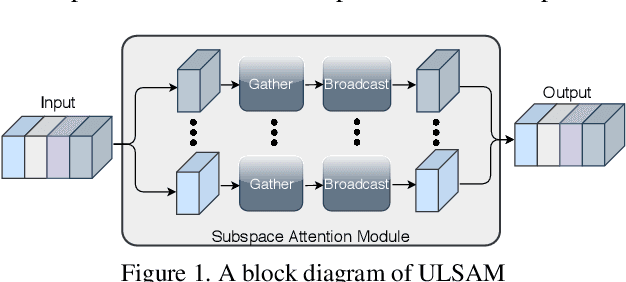

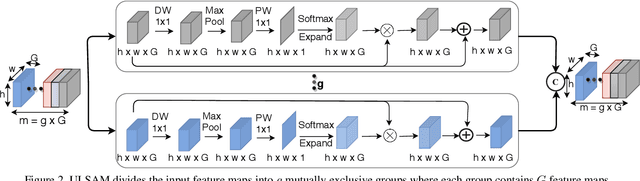
The capability of the self-attention mechanism to model the long-range dependencies has catapulted its deployment in vision models. Unlike convolution operators, self-attention offers infinite receptive field and enables compute-efficient modeling of global dependencies. However, the existing state-of-the-art attention mechanisms incur high compute and/or parameter overheads, and hence unfit for compact convolutional neural networks (CNNs). In this work, we propose a simple yet effective "Ultra-Lightweight Subspace Attention Mechanism" (ULSAM), which infers different attention maps for each feature map subspace. We argue that leaning separate attention maps for each feature subspace enables multi-scale and multi-frequency feature representation, which is more desirable for fine-grained image classification. Our method of subspace attention is orthogonal and complementary to the existing state-of-the-arts attention mechanisms used in vision models. ULSAM is end-to-end trainable and can be deployed as a plug-and-play module in the pre-existing compact CNNs. Notably, our work is the first attempt that uses a subspace attention mechanism to increase the efficiency of compact CNNs. To show the efficacy of ULSAM, we perform experiments with MobileNet-V1 and MobileNet-V2 as backbone architectures on ImageNet-1K and three fine-grained image classification datasets. We achieve $\approx$13% and $\approx$25% reduction in both the FLOPs and parameter counts of MobileNet-V2 with a 0.27% and more than 1% improvement in top-1 accuracy on the ImageNet-1K and fine-grained image classification datasets (respectively). Code and trained models are available at https://github.com/Nandan91/ULSAM.
* Accepted as a conference paper in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV)
E2GC: Energy-efficient Group Convolution in Deep Neural Networks
Jun 26, 2020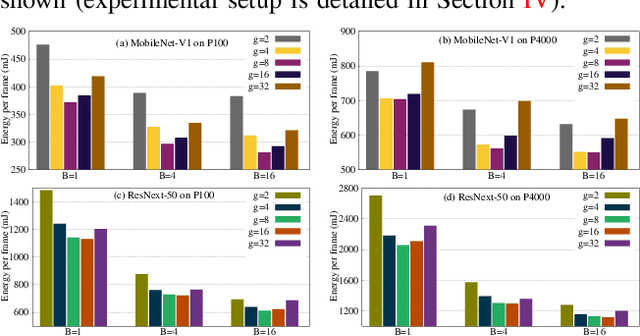
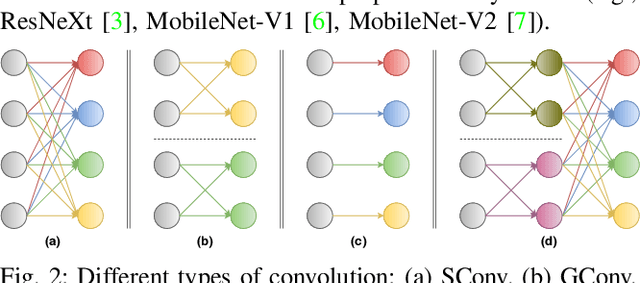
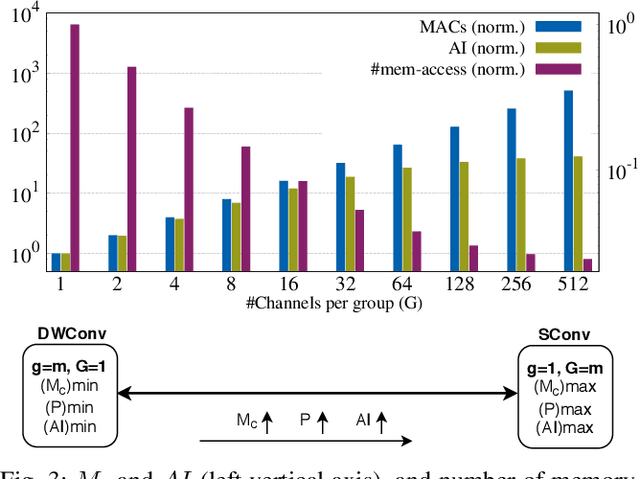

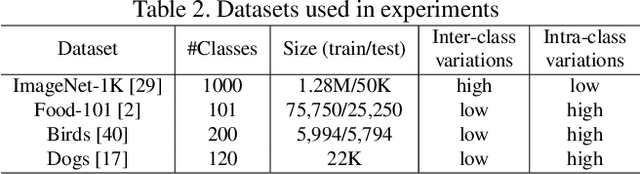
The number of groups ($g$) in group convolution (GConv) is selected to boost the predictive performance of deep neural networks (DNNs) in a compute and parameter efficient manner. However, we show that naive selection of $g$ in GConv creates an imbalance between the computational complexity and degree of data reuse, which leads to suboptimal energy efficiency in DNNs. We devise an optimum group size model, which enables a balance between computational cost and data movement cost, thus, optimize the energy-efficiency of DNNs. Based on the insights from this model, we propose an "energy-efficient group convolution" (E2GC) module where, unlike the previous implementations of GConv, the group size ($G$) remains constant. Further, to demonstrate the efficacy of the E2GC module, we incorporate this module in the design of MobileNet-V1 and ResNeXt-50 and perform experiments on two GPUs, P100 and P4000. We show that, at comparable computational complexity, DNNs with constant group size (E2GC) are more energy-efficient than DNNs with a fixed number of groups (F$g$GC). For example, on P100 GPU, the energy-efficiency of MobileNet-V1 and ResNeXt-50 is increased by 10.8% and 4.73% (respectively) when E2GC modules substitute the F$g$GC modules in both the DNNs. Furthermore, through our extensive experimentation with ImageNet-1K and Food-101 image classification datasets, we show that the E2GC module enables a trade-off between generalization ability and representational power of DNN. Thus, the predictive performance of DNNs can be optimized by selecting an appropriate $G$. The code and trained models are available at https://github.com/iithcandle/E2GC-release.
* Accepted as a conference paper in 2020 33rd International Conference on VLSI Design and 2020 19th International Conference on Embedded Systems (VLSID)