 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADG: Margin-based Adversarial Learning for Domain Generalization
Nov 14, 2023



Domain Generalization (DG) techniques have emerged as a popular approach to address the challenges of domain shift in Deep Learning (DL), with the goal of generalizing well to the target domain unseen during the training. In recent years, numerous methods have been proposed to address the DG setting, among which one popular approach is the adversarial learning-based methodology. The main idea behind adversarial DG methods is to learn domain-invariant features by minimizing a discrepancy metric. However, most adversarial DG methods use 0-1 loss based $\mathcal{H}\Delta\mathcal{H}$ divergence metric. In contrast, the margin loss-based discrepancy metric has the following advantages: more informative, tighter, practical, and efficiently optimizable. To mitigate this gap, this work proposes a novel adversarial learning DG algorithm, MADG, motivated by a margin loss-based discrepancy metric. The proposed MADG model learns domain-invariant features across all source domains and uses adversarial training to generalize well to the unseen target domain. We also provide a theoretical analysis of the proposed MADG model based on the unseen target error bound. Specifically, we construct the link between the source and unseen domains in the real-valued hypothesis space and derive the generalization bound using margin loss and Rademacher complexity. We extensively experiment with the MADG model on popular real-world DG datasets, VLCS, PACS, OfficeHome, DomainNet, and TerraIncognita. We evaluate the proposed algorithm on DomainBed's benchmark and observe consistent performance across all the datasets.
Defining Traffic States using Spatio-temporal Traffic Graphs
Jul 27, 2020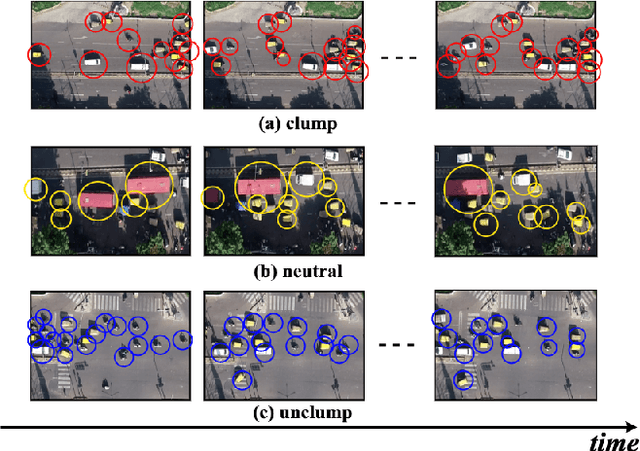
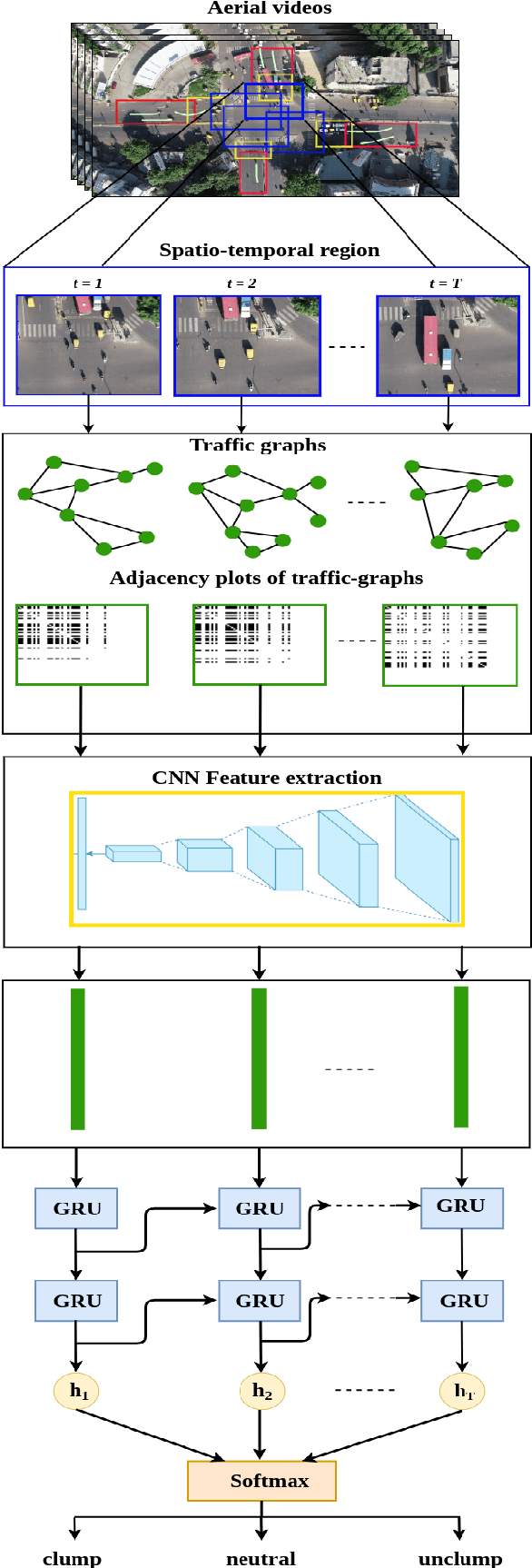
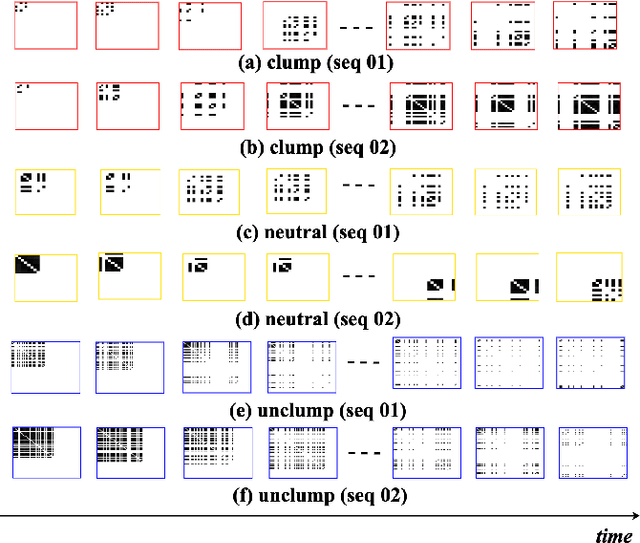
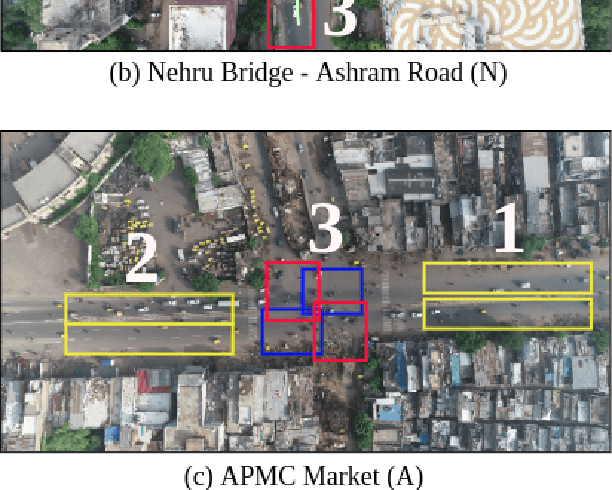
Intersections are one of the main sources of congestion and hence, it is important to understand traffic behavior at intersections. Particularly, in developing countries with high vehicle density, mixed traffic type, and lane-less driving behavior, it is difficult to distinguish between congested and normal traffic behavior. In this work, we propose a way to understand the traffic state of smaller spatial regions at intersections using traffic graphs. The way these traffic graphs evolve over time reveals different traffic states - a) a congestion is forming (clumping), the congestion is dispersing (unclumping), or c) the traffic is flowing normally (neutral). We train a spatio-temporal deep network to identify these changes. Also, we introduce a large dataset called EyeonTraffic (EoT) containing 3 hours of aerial videos collected at 3 busy intersections in Ahmedabad, India. Our experiments on the EoT dataset show that the traffic graphs can help in correctly identifying congestion-prone behavior in different spatial regions of an intersection.
ULSAM: Ultra-Lightweight Subspace Attention Module for Compact Convolutional Neural Networks
Jun 26, 2020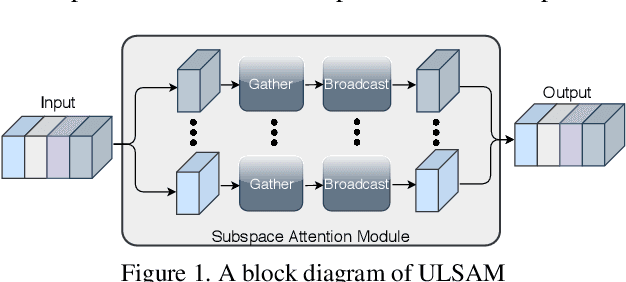

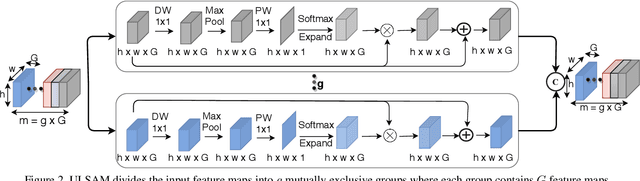
The capability of the self-attention mechanism to model the long-range dependencies has catapulted its deployment in vision models. Unlike convolution operators, self-attention offers infinite receptive field and enables compute-efficient modeling of global dependencies. However, the existing state-of-the-art attention mechanisms incur high compute and/or parameter overheads, and hence unfit for compact convolutional neural networks (CNNs). In this work, we propose a simple yet effective "Ultra-Lightweight Subspace Attention Mechanism" (ULSAM), which infers different attention maps for each feature map subspace. We argue that leaning separate attention maps for each feature subspace enables multi-scale and multi-frequency feature representation, which is more desirable for fine-grained image classification. Our method of subspace attention is orthogonal and complementary to the existing state-of-the-arts attention mechanisms used in vision models. ULSAM is end-to-end trainable and can be deployed as a plug-and-play module in the pre-existing compact CNNs. Notably, our work is the first attempt that uses a subspace attention mechanism to increase the efficiency of compact CNNs. To show the efficacy of ULSAM, we perform experiments with MobileNet-V1 and MobileNet-V2 as backbone architectures on ImageNet-1K and three fine-grained image classification datasets. We achieve $\approx$13% and $\approx$25% reduction in both the FLOPs and parameter counts of MobileNet-V2 with a 0.27% and more than 1% improvement in top-1 accuracy on the ImageNet-1K and fine-grained image classification datasets (respectively). Code and trained models are available at https://github.com/Nandan91/ULSAM.
* Accepted as a conference paper in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV)