 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Build Marcus's Algebraic Mind: Algebro-Deterministic Substrate over Galois Fields
May 21, 2026In The Algebraic Mind, Gary Marcus identified three components essential for any adequate cognitive architecture: operations over variables, recursively structured representations, and a distinction between mental representations of individuals and kinds. He argued that standard multilayer perceptrons supported none of these, acknowledging that a neural implementation using registers and treelets, constructed via developmental programs rather than gradient descent, remained a programmatic conjecture. Twenty-five years later, the required substrate is now available. Our newly developed PyVaCoAl/VaCoAl is a hyperdimensional computing architecture organized end-to-end around a single algebraic primitive: XOR-and-shift over GF(2), implemented by primitive-polynomial linear-feedback shift registers. The architecture supports reversible variable binding via Bind(R,F) = R XOR shift(F), non-commutative compositional bundling that distinguishes "the dog bites the man" from "the man bites the dog," and address-space individual/kind separation under the same algebra. A companion perspective argues that the dentate gyrus-CA3 circuit is a biological homologue of this same engine, with developmentally specified mossy-fiber targeting supplying the innate microcircuitry Marcus anticipated. In this paper, we map the correspondence between Marcus's three pillars and the operational commitments of PyVaCoAl/VaCoAl. We reinterpret the treelet as an algebraic register set indexed by a primitive generator polynomial, arguing that this architecture provides a functional neural substrate meeting Marcus's specifications far more closely than the tensor products, circular convolution, or temporal synchrony available in 2001. We also demonstrate how this substrate naturally extends to Pearl's rung-3 counterfactual reasoning, a capability the original treelet program did not directly target.
Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?
May 21, 2026Multimodal Large Language Models (MLLMs) are increasingly deployed in human-facing roles where personality perception is critical, yet existing benchmarks evaluate this capability solely on numerical Big Five score prediction, leaving open whether models truly perceive personality through behavioral understanding or merely prejudge through superficial pattern matching. We address this gap with three contributions. (i) A new task: we formalize Grounded Personality Reasoning (GPR), which requires MLLMs to anchor each Big Five rating in observable evidence through a chain of rating, reasoning, and grounding. (ii) A new dataset: we release MM-OCEAN (1,104 videos, 5,320 MCQs), produced by a multi-agent pipeline with human verification, with timestamped behavioral observations, evidence-grounded trait analyses, and seven categories of cue-grounding MCQs. (iii) Benchmark and analysis: we design a three-tier evaluation (rating, reasoning, grounding) plus four sample-level failure-mode metrics: Prejudice Rate (PR), Confabulation Rate (CR), Integration-failure Rate (IR), and Holistic-grounding Rate (HR), and benchmark 27 MLLMs (13 closed, 14 open). The analysis uncovers a striking Prejudice Gap: across the field, 51% of correct ratings are not grounded in retrieved cues, and the Holistic-Grounding Rate spans only 0-33.5%. These findings expose a disconnect between getting the right score and reasoning for the right reason, charting a roadmap for grounded social cognition in MLLMs.
SocialDirector: Training-Free Social Interaction Control for Multi-Person Video Generation
May 11, 2026Video generation has advanced rapidly, producing photorealistic videos from text or image prompts. Meanwhile, film production and social robotics increasingly demand multi-person videos with rich social interactions, including conversations, gestures, and coordinated actions. However, existing models offer no explicit control over interactions, such as who performs which action, when it occurs, and toward whom it is directed. This often results in wrong person performing unintended actions (actor-action mismatch), disordered social dynamics, and wrong action targets. To address these challenges, we present SocialDirector, a training-free interaction controller that enhances the generation model by modulating cross-attention maps. SocialDirector contains two modules: Social Actor Masking and Directional Reweighting. Social Actor Masking constrains each person's visual tokens to attend only to their own textual descriptions via a spatiotemporal mask, avoiding actor-action mismatch and disordered social dynamics. Directional Reweighting amplifies attention to directional words (e.g., "leftward", "right"), leading each action towards its intended target. To evaluate generated social interactions, we annotate existing datasets with interaction descriptions and build a fully automated evaluation pipeline powered by open-source VLMs. Experiments on different video generation models show that SocialDirector significantly improves interaction fidelity and approaches the upper bound set by real videos.
Beyond LLMs, Sparse Distributed Memory, and Neuromorphics <A Hyper-Dimensional SRAM-CAM "VaCoAl" for Ultra-High Speed, Ultra-Low Power, and Low Cost>
Apr 13, 2026This paper reports an unexpected finding: in a deterministic hyperdimensional computing (HDC) architecture based on Galois-field algebra, a path-dependent semantic selection mechanism emerges, equivalent to spike-timing-dependent plasticity (STDP), with magnitude predictable a priori by a closed-form expression matching large-scale measurements. This addresses limitations of modern AI including catastrophic forgetting, learning stagnation, and the Binding Problem at an algebraic level. We propose VaCoAl (Vague Coincident Algorithm) and its Python implementation PyVaCoAl, combining ultra-high-dimensional memory with deterministic logic. Rooted in Sparse Distributed Memory, it resolves orthogonalisation and retrieval in high-dimensional binary spaces via Galois-field diffusion, enabling low-load deployment. VaCoAl is a memory-centric architecture prioritising retrieval and association, enabling reversible composition while preserving element independence and supporting compositional generalisation with a transparent reliability metric (CR score). We evaluated multi-hop reasoning on about 470k mentor-student relations from Wikidata, tracing up to 57 generations (over 25.5M paths). Using HDC bundling and unbinding with CR-based denoising, we quantify concept propagation over DAGs. Results show a reinterpretation of the Newton-Leibniz dispute and a phase transition from sparse convergence to a post-Leibniz "superhighway", from which structural indicators emerge supporting a Kuhnian paradigm shift. Collision-tolerance mechanisms further induce path-based pruning that favors direct paths, yielding emergent semantic selection equivalent to STDP. VaCoAl thus defines a third paradigm, HDC-AI, complementing LLMs with reversible multi-hop reasoning.
Egocentric Gaze Estimation via Neck-Mounted Camera
Feb 12, 2026This paper introduces neck-mounted view gaze estimation, a new task that estimates user gaze from the neck-mounted camera perspective. Prior work on egocentric gaze estimation, which predicts device wearer's gaze location within the camera's field of view, mainly focuses on head-mounted cameras while alternative viewpoints remain underexplored. To bridge this gap, we collect the first dataset for this task, consisting of approximately 4 hours of video collected from 8 participants during everyday activities. We evaluate a transformer-based gaze estimation model, GLC, on the new dataset and propose two extensions: an auxiliary gaze out-of-bound classification task and a multi-view co-learning approach that jointly trains head-view and neck-view models using a geometry-aware auxiliary loss. Experimental results show that incorporating gaze out-of-bound classification improves performance over standard fine-tuning, while the co-learning approach does not yield gains. We further analyze these results and discuss implications for neck-mounted gaze estimation.
The N-Body Problem: Parallel Execution from Single-Person Egocentric Video
Dec 12, 2025Humans can intuitively parallelise complex activities, but can a model learn this from observing a single person? Given one egocentric video, we introduce the N-Body Problem: how N individuals, can hypothetically perform the same set of tasks observed in this video. The goal is to maximise speed-up, but naive assignment of video segments to individuals often violates real-world constraints, leading to physically impossible scenarios like two people using the same object or occupying the same space. To address this, we formalise the N-Body Problem and propose a suite of metrics to evaluate both performance (speed-up, task coverage) and feasibility (spatial collisions, object conflicts and causal constraints). We then introduce a structured prompting strategy that guides a Vision-Language Model (VLM) to reason about the 3D environment, object usage, and temporal dependencies to produce a viable parallel execution. On 100 videos from EPIC-Kitchens and HD-EPIC, our method for N = 2 boosts action coverage by 45% over a baseline prompt for Gemini 2.5 Pro, while simultaneously slashing collision rates, object and causal conflicts by 55%, 45% and 55% respectively.
Can MLLMs Read the Room? A Multimodal Benchmark for Verifying Truthfulness in Multi-Party Social Interactions
Oct 31, 2025As AI systems become increasingly integrated into human lives, endowing them with robust social intelligence has emerged as a critical frontier. A key aspect of this intelligence is discerning truth from deception, a ubiquitous element of human interaction that is conveyed through a complex interplay of verbal language and non-verbal visual cues. However, automatic deception detection in dynamic, multi-party conversations remains a significant challenge. The recent rise of powerful Multimodal Large Language Models (MLLMs), with their impressive abilities in visual and textual understanding, makes them natural candidates for this task. Consequently, their capabilities in this crucial domain are mostly unquantified. To address this gap, we introduce a new task, Multimodal Interactive Veracity Assessment (MIVA), and present a novel multimodal dataset derived from the social deduction game Werewolf. This dataset provides synchronized video, text, with verifiable ground-truth labels for every statement. We establish a comprehensive benchmark evaluating state-of-the-art MLLMs, revealing a significant performance gap: even powerful models like GPT-4o struggle to distinguish truth from falsehood reliably. Our analysis of failure modes indicates that these models fail to ground language in visual social cues effectively and may be overly conservative in their alignment, highlighting the urgent need for novel approaches to building more perceptive and trustworthy AI systems.
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025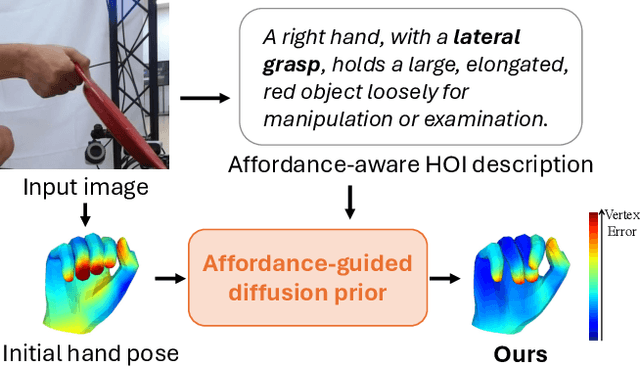
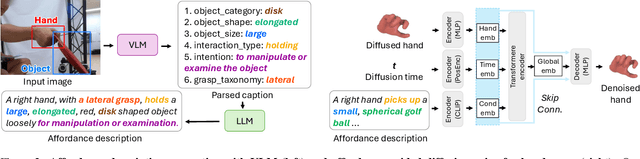
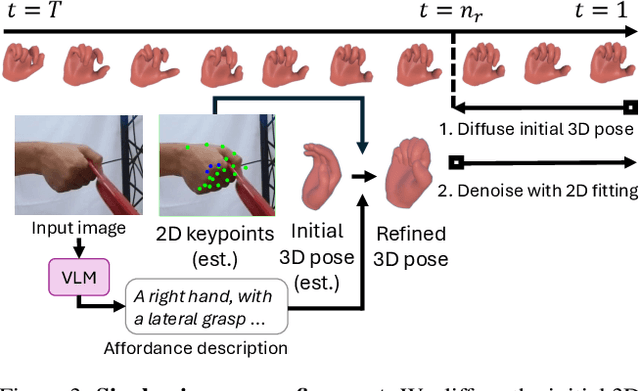
How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
EgoInstruct: An Egocentric Video Dataset of Face-to-face Instructional Interactions with Multi-modal LLM Benchmarking
Sep 26, 2025Analyzing instructional interactions between an instructor and a learner who are co-present in the same physical space is a critical problem for educational support and skill transfer. Yet such face-to-face instructional scenes have not been systematically studied in computer vision. We identify two key reasons: i) the lack of suitable datasets and ii) limited analytical techniques. To address this gap, we present a new egocentric video dataset of face-to-face instruction and provide ground-truth annotations for two fundamental tasks that serve as a first step toward a comprehensive understanding of instructional interactions: procedural step segmentation and conversation-state classification. Using this dataset, we benchmark multimodal large language models (MLLMs) against conventional task-specific models. Since face-to-face instruction involves multiple modalities (speech content and prosody, gaze and body motion, and visual context), effective understanding requires methods that handle verbal and nonverbal communication in an integrated manner. Accordingly, we evaluate recently introduced MLLMs that jointly process images, audio, and text. This evaluation quantifies the extent to which current machine learning models understand face-to-face instructional scenes. In experiments, MLLMs outperform specialized baselines even without task-specific fine-tuning, suggesting their promise for holistic understanding of instructional interactions.
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Jun 06, 2025



Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, enabling rich and complementary understanding of dynamic environments. In recent years, allowing the machines to leverage the synergistic potential of these dual perspectives has emerged as a compelling research direction in video understanding. In this survey, we provide a comprehensive review of video understanding from both exocentric and egocentric viewpoints. We begin by highlighting the practical applications of integrating egocentric and exocentric techniques, envisioning their potential collaboration across domains. We then identify key research tasks to realize these applications. Next, we systematically organize and review recent advancements into three main research directions: (1) leveraging egocentric data to enhance exocentric understanding, (2) utilizing exocentric data to improve egocentric analysis, and (3) joint learning frameworks that unify both perspectives. For each direction, we analyze a diverse set of tasks and relevant works. Additionally, we discuss benchmark datasets that support research in both perspectives, evaluating their scope, diversity, and applicability. Finally, we discuss limitations in current works and propose promising future research directions. By synthesizing insights from both perspectives, our goal is to inspire advancements in video understanding and artificial intelligence, bringing machines closer to perceiving the world in a human-like manner. A GitHub repo of related works can be found at https://github.com/ayiyayi/Awesome-Egocentric-and-Exocentric-Vision.