 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Minutes to Days: Scaling Intracranial Speech Decoding with Supervised Pretraining
Dec 17, 2025Decoding speech from brain activity has typically relied on limited neural recordings collected during short and highly controlled experiments. Here, we introduce a framework to leverage week-long intracranial and audio recordings from patients undergoing clinical monitoring, effectively increasing the training dataset size by over two orders of magnitude. With this pretraining, our contrastive learning model substantially outperforms models trained solely on classic experimental data, with gains that scale log-linearly with dataset size. Analysis of the learned representations reveals that, while brain activity represents speech features, its global structure largely drifts across days, highlighting the need for models that explicitly account for cross-day variability. Overall, our approach opens a scalable path toward decoding and modeling brain representations in both real-life and controlled task settings.
Can MLLMs Read the Room? A Multimodal Benchmark for Verifying Truthfulness in Multi-Party Social Interactions
Oct 31, 2025As AI systems become increasingly integrated into human lives, endowing them with robust social intelligence has emerged as a critical frontier. A key aspect of this intelligence is discerning truth from deception, a ubiquitous element of human interaction that is conveyed through a complex interplay of verbal language and non-verbal visual cues. However, automatic deception detection in dynamic, multi-party conversations remains a significant challenge. The recent rise of powerful Multimodal Large Language Models (MLLMs), with their impressive abilities in visual and textual understanding, makes them natural candidates for this task. Consequently, their capabilities in this crucial domain are mostly unquantified. To address this gap, we introduce a new task, Multimodal Interactive Veracity Assessment (MIVA), and present a novel multimodal dataset derived from the social deduction game Werewolf. This dataset provides synchronized video, text, with verifiable ground-truth labels for every statement. We establish a comprehensive benchmark evaluating state-of-the-art MLLMs, revealing a significant performance gap: even powerful models like GPT-4o struggle to distinguish truth from falsehood reliably. Our analysis of failure modes indicates that these models fail to ground language in visual social cues effectively and may be overly conservative in their alignment, highlighting the urgent need for novel approaches to building more perceptive and trustworthy AI systems.
Egocentric Action-aware Inertial Localization in Point Clouds
May 20, 2025



This paper presents a novel inertial localization framework named Egocentric Action-aware Inertial Localization (EAIL), which leverages egocentric action cues from head-mounted IMU signals to localize the target individual within a 3D point cloud. Human inertial localization is challenging due to IMU sensor noise that causes trajectory drift over time. The diversity of human actions further complicates IMU signal processing by introducing various motion patterns. Nevertheless, we observe that some actions observed through the head-mounted IMU correlate with spatial environmental structures (e.g., bending down to look inside an oven, washing dishes next to a sink), thereby serving as spatial anchors to compensate for the localization drift. The proposed EAIL framework learns such correlations via hierarchical multi-modal alignment. By assuming that the 3D point cloud of the environment is available, it contrastively learns modality encoders that align short-term egocentric action cues in IMU signals with local environmental features in the point cloud. These encoders are then used in reasoning the IMU data and the point cloud over time and space to perform inertial localization. Interestingly, these encoders can further be utilized to recognize the corresponding sequence of actions as a by-product. Extensive experiments demonstrate the effectiveness of the proposed framework over state-of-the-art inertial localization and inertial action recognition baselines.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
Feb 21, 2025



We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.
Brain-to-Text Decoding: A Non-invasive Approach via Typing
Feb 18, 2025Modern neuroprostheses can now restore communication in patients who have lost the ability to speak or move. However, these invasive devices entail risks inherent to neurosurgery. Here, we introduce a non-invasive method to decode the production of sentences from brain activity and demonstrate its efficacy in a cohort of 35 healthy volunteers. For this, we present Brain2Qwerty, a new deep learning architecture trained to decode sentences from either electro- (EEG) or magneto-encephalography (MEG), while participants typed briefly memorized sentences on a QWERTY keyboard. With MEG, Brain2Qwerty reaches, on average, a character-error-rate (CER) of 32% and substantially outperforms EEG (CER: 67%). For the best participants, the model achieves a CER of 19%, and can perfectly decode a variety of sentences outside of the training set. While error analyses suggest that decoding depends on motor processes, the analysis of typographical errors suggests that it also involves higher-level cognitive factors. Overall, these results narrow the gap between invasive and non-invasive methods and thus open the path for developing safe brain-computer interfaces for non-communicating patients.
Pre-Training for 3D Hand Pose Estimation with Contrastive Learning on Large-Scale Hand Images in the Wild
Sep 15, 2024



We present a contrastive learning framework based on in-the-wild hand images tailored for pre-training 3D hand pose estimators, dubbed HandCLR. Pre-training on large-scale images achieves promising results in various tasks, but prior 3D hand pose pre-training methods have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our method with contrastive learning. Specifically, we collected over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands; pairs of similar hand poses originating from different samples, and propose a novel contrastive learning method that embeds similar hand pairs closer in the latent space. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands.
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Jul 09, 2024Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being robust to lighting variation and occlusion. While these characteristics are intuitively valuable to help egocentric action recognition, the potential of IMUs remains under-explored. In this work, we present a novel method for action recognition that integrates motion data from body-worn IMUs with egocentric video. Due to the scarcity of labeled multimodal data, we design an MAE-based self-supervised pretraining method, obtaining strong multi-modal representations via modeling the natural correlation between visual and motion signals. To model the complex relation of multiple IMU devices placed across the body, we exploit the collaborative dynamics in multiple IMU devices and propose to embed the relative motion features of human joints into a graph structure. Experiments show our method can achieve state-of-the-art performance on multiple public datasets. The effectiveness of our MAE-based pretraining and graph-based IMU modeling are further validated by experiments in more challenging scenarios, including partially missing IMU devices and video quality corruption, promoting more flexible usages in the real world.
EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Mar 24, 2024
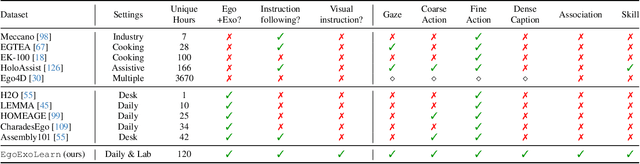


Being able to map the activities of others into one's own point of view is one fundamental human skill even from a very early age. Taking a step toward understanding this human ability, we introduce EgoExoLearn, a large-scale dataset that emulates the human demonstration following process, in which individuals record egocentric videos as they execute tasks guided by demonstration videos. Focusing on the potential applications in daily assistance and professional support, EgoExoLearn contains egocentric and demonstration video data spanning 120 hours captured in daily life scenarios and specialized laboratories. Along with the videos we record high-quality gaze data and provide detailed multimodal annotations, formulating a playground for modeling the human ability to bridge asynchronous procedural actions from different viewpoints. To this end, we present benchmarks such as cross-view association, cross-view action planning, and cross-view referenced skill assessment, along with detailed analysis. We expect EgoExoLearn can serve as an important resource for bridging the actions across views, thus paving the way for creating AI agents capable of seamlessly learning by observing humans in the real world. Code and data can be found at: https://github.com/OpenGVLab/EgoExoLearn
Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
Mar 09, 2024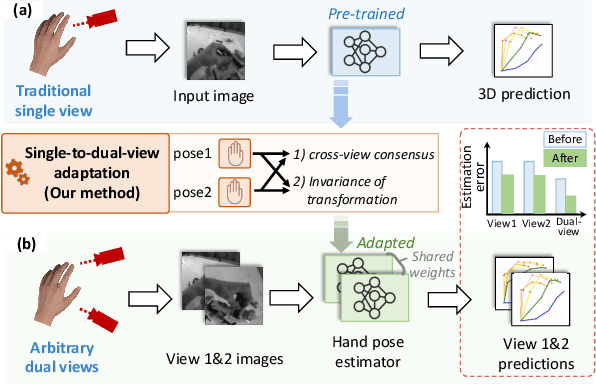

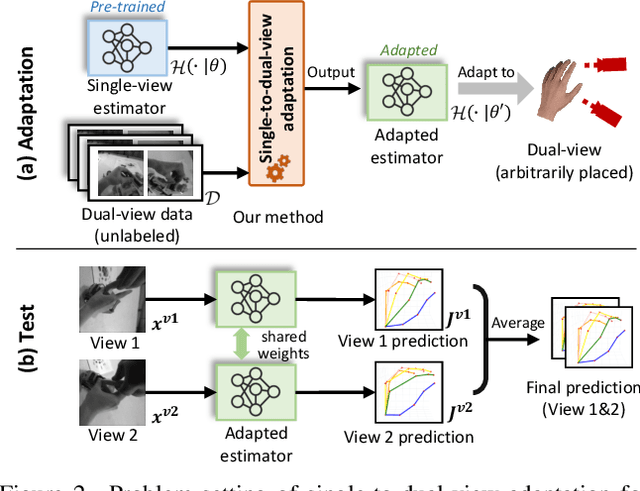
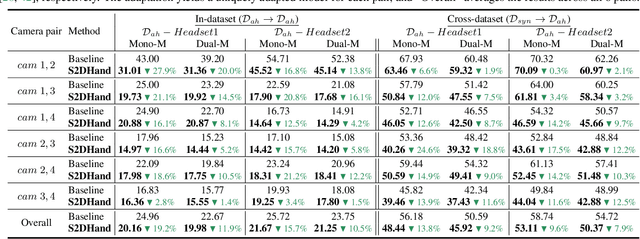
The pursuit of accurate 3D hand pose estimation stands as a keystone for understanding human activity in the realm of egocentric vision. The majority of existing estimation methods still rely on single-view images as input, leading to potential limitations, e.g., limited field-of-view and ambiguity in depth. To address these problems, adding another camera to better capture the shape of hands is a practical direction. However, existing multi-view hand pose estimation methods suffer from two main drawbacks: 1) Requiring multi-view annotations for training, which are expensive. 2) During testing, the model becomes inapplicable if camera parameters/layout are not the same as those used in training. In this paper, we propose a novel Single-to-Dual-view adaptation (S2DHand) solution that adapts a pre-trained single-view estimator to dual views. Compared with existing multi-view training methods, 1) our adaptation process is unsupervised, eliminating the need for multi-view annotation. 2) Moreover, our method can handle arbitrary dual-view pairs with unknown camera parameters, making the model applicable to diverse camera settings. Specifically, S2DHand is built on certain stereo constraints, including pair-wise cross-view consensus and invariance of transformation between both views. These two stereo constraints are used in a complementary manner to generate pseudo-labels, allowing reliable adaptation. Evaluation results reveal that S2DHand achieves significant improvements on arbitrary camera pairs under both in-dataset and cross-dataset settings, and outperforms existing adaptation methods with leading performance. Project page: https://github.com/MickeyLLG/S2DHand.