 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Minutes to Days: Scaling Intracranial Speech Decoding with Supervised Pretraining
Dec 17, 2025Decoding speech from brain activity has typically relied on limited neural recordings collected during short and highly controlled experiments. Here, we introduce a framework to leverage week-long intracranial and audio recordings from patients undergoing clinical monitoring, effectively increasing the training dataset size by over two orders of magnitude. With this pretraining, our contrastive learning model substantially outperforms models trained solely on classic experimental data, with gains that scale log-linearly with dataset size. Analysis of the learned representations reveals that, while brain activity represents speech features, its global structure largely drifts across days, highlighting the need for models that explicitly account for cross-day variability. Overall, our approach opens a scalable path toward decoding and modeling brain representations in both real-life and controlled task settings.
Evaluation Of P300 Speller Performance Using Large Language Models Along With Cross-Subject Training
Oct 19, 2024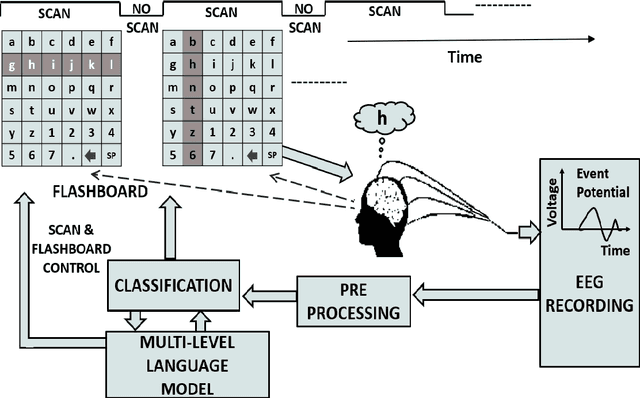
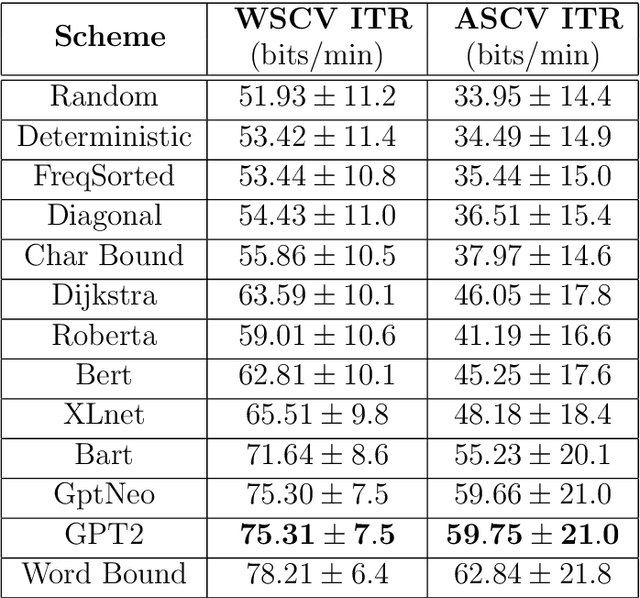
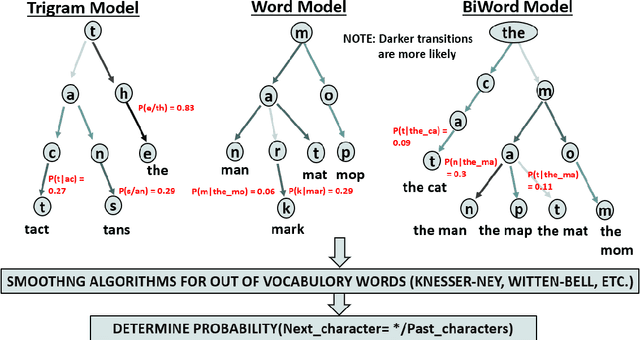

Amyotrophic lateral sclerosis (ALS), a progressive neuromuscular degenerative disease, severely restricts patient communication capacity within a few years of onset, resulting in a significant deterioration of quality of life. The P300 speller brain computer interface (BCI) offers an alternative communication medium by leveraging a subject's EEG response to characters traditionally highlighted on a character grid on a graphical user interface (GUI). A recurring theme in P300-based research is enhancing performance to enable faster subject interaction. This study builds on that theme by addressing key limitations, particularly in the training of multi-subject classifiers, and by integrating advanced language models to optimize stimuli presentation and word prediction, thereby improving communication efficiency. Furthermore, various advanced large language models such as Generative Pre-Trained Transformer (GPT2), BERT, and BART, alongside Dijkstra's algorithm, are utilized to optimize stimuli and provide word completion choices based on the spelling history. In addition, a multi-layered smoothing approach is applied to allow for out-of-vocabulary (OOV) words. By conducting extensive simulations based on randomly sampled EEG data from subjects, we show substantial speed improvements in typing passages that include rare and out-of-vocabulary (OOV) words, with the extent of improvement varying depending on the language model utilized. The gains through such character-level interface optimizations are approximately 10%, and GPT2 for multi-word prediction provides gains of around 40%. In particular, some large language models achieve performance levels within 10% of the theoretical performance limits established in this study. In addition, both within and across subjects, training techniques are explored, and speed improvements are shown to hold in both cases.
High Performance P300 Spellers Using GPT2 Word Prediction With Cross-Subject Training
May 22, 2024Amyotrophic lateral sclerosis (ALS) severely impairs patients' ability to communicate, often leading to a decline in their quality of life within a few years of diagnosis. The P300 speller brain-computer interface (BCI) offers an alternative communication method by interpreting a subject's EEG response to characters presented on a grid interface. This paper addresses the common speed limitations encountered in training efficient P300-based multi-subject classifiers by introducing innovative "across-subject" classifiers. We leverage a combination of the second-generation Generative Pre-Trained Transformer (GPT2) and Dijkstra's algorithm to optimize stimuli and suggest word completion choices based on typing history. Additionally, we employ a multi-layered smoothing technique to accommodate out-of-vocabulary (OOV) words. Through extensive simulations involving random sampling of EEG data from subjects, we demonstrate significant speed enhancements in typing passages containing rare and OOV words. These optimizations result in approximately 10% improvement in character-level typing speed and up to 40% improvement in multi-word prediction. We demonstrate that augmenting standard row/column highlighting techniques with layered word prediction yields close-to-optimal performance. Furthermore, we explore both "within-subject" and "across-subject" training techniques, showing that speed improvements are consistent across both approaches.