 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Of P300 Speller Performance Using Large Language Models Along With Cross-Subject Training
Oct 19, 2024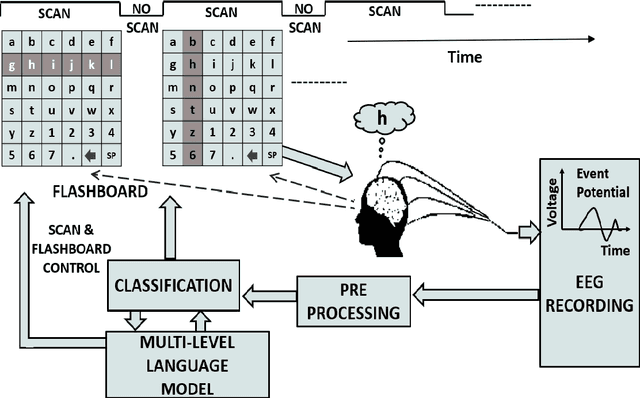
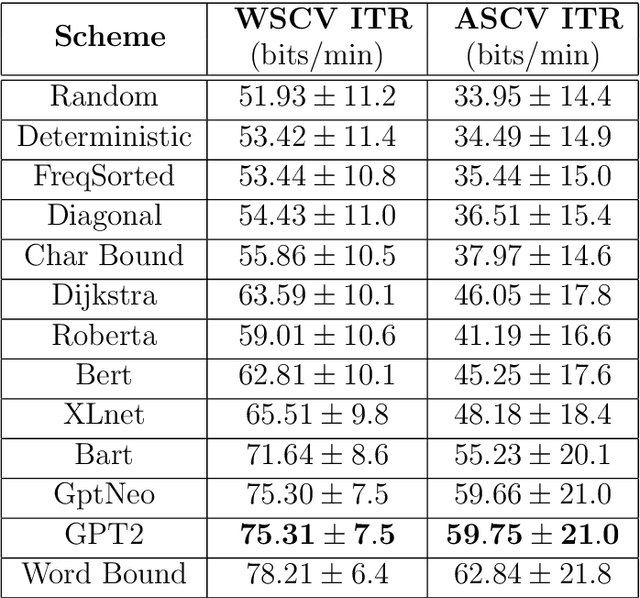
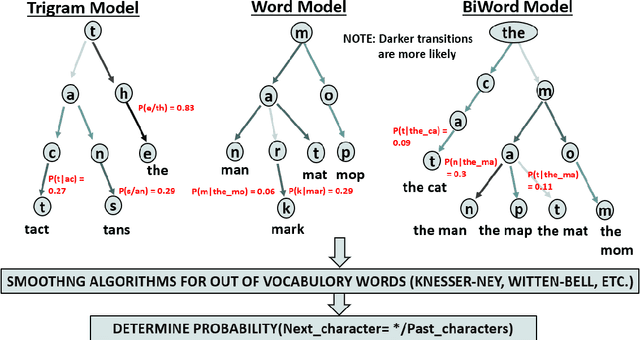

Amyotrophic lateral sclerosis (ALS), a progressive neuromuscular degenerative disease, severely restricts patient communication capacity within a few years of onset, resulting in a significant deterioration of quality of life. The P300 speller brain computer interface (BCI) offers an alternative communication medium by leveraging a subject's EEG response to characters traditionally highlighted on a character grid on a graphical user interface (GUI). A recurring theme in P300-based research is enhancing performance to enable faster subject interaction. This study builds on that theme by addressing key limitations, particularly in the training of multi-subject classifiers, and by integrating advanced language models to optimize stimuli presentation and word prediction, thereby improving communication efficiency. Furthermore, various advanced large language models such as Generative Pre-Trained Transformer (GPT2), BERT, and BART, alongside Dijkstra's algorithm, are utilized to optimize stimuli and provide word completion choices based on the spelling history. In addition, a multi-layered smoothing approach is applied to allow for out-of-vocabulary (OOV) words. By conducting extensive simulations based on randomly sampled EEG data from subjects, we show substantial speed improvements in typing passages that include rare and out-of-vocabulary (OOV) words, with the extent of improvement varying depending on the language model utilized. The gains through such character-level interface optimizations are approximately 10%, and GPT2 for multi-word prediction provides gains of around 40%. In particular, some large language models achieve performance levels within 10% of the theoretical performance limits established in this study. In addition, both within and across subjects, training techniques are explored, and speed improvements are shown to hold in both cases.
High Performance P300 Spellers Using GPT2 Word Prediction With Cross-Subject Training
May 22, 2024Amyotrophic lateral sclerosis (ALS) severely impairs patients' ability to communicate, often leading to a decline in their quality of life within a few years of diagnosis. The P300 speller brain-computer interface (BCI) offers an alternative communication method by interpreting a subject's EEG response to characters presented on a grid interface. This paper addresses the common speed limitations encountered in training efficient P300-based multi-subject classifiers by introducing innovative "across-subject" classifiers. We leverage a combination of the second-generation Generative Pre-Trained Transformer (GPT2) and Dijkstra's algorithm to optimize stimuli and suggest word completion choices based on typing history. Additionally, we employ a multi-layered smoothing technique to accommodate out-of-vocabulary (OOV) words. Through extensive simulations involving random sampling of EEG data from subjects, we demonstrate significant speed enhancements in typing passages containing rare and OOV words. These optimizations result in approximately 10% improvement in character-level typing speed and up to 40% improvement in multi-word prediction. We demonstrate that augmenting standard row/column highlighting techniques with layered word prediction yields close-to-optimal performance. Furthermore, we explore both "within-subject" and "across-subject" training techniques, showing that speed improvements are consistent across both approaches.
Translating neural signals to text using a Brain-Machine Interface
Jul 09, 2019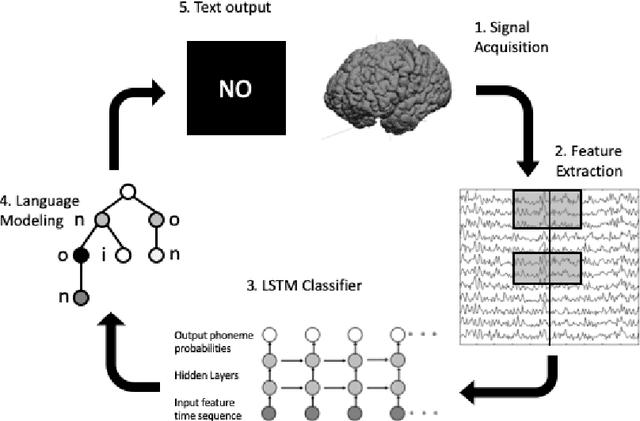
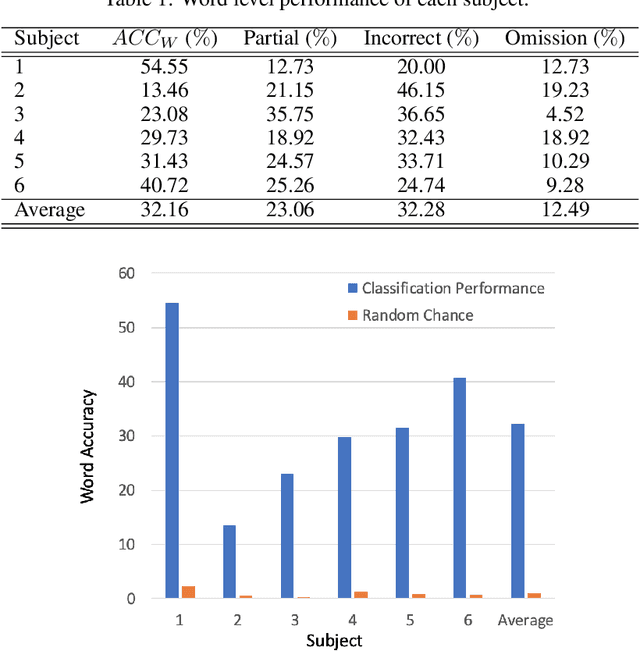
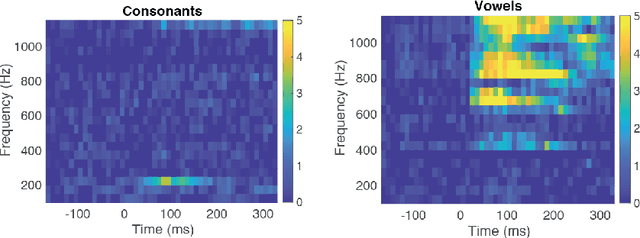
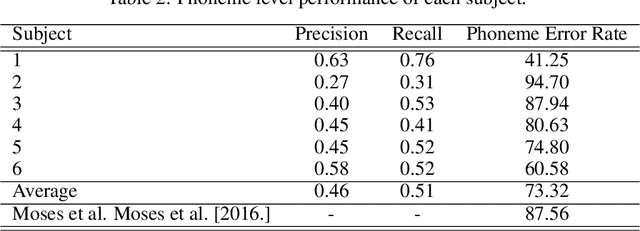
Brain-Computer Interfaces (BCI) help patients with faltering communication abilities due to neurodegenerative diseases produce text or speech output by direct neural processing. However, practical implementation of such a system has proven difficult due to limitations in speed, accuracy, and generalizability of the existing interfaces. To this end, we aim to create a BCI system that decodes text directly from neural signals. We implement a framework that initially isolates frequency bands in the input signal encapsulating differential information regarding production of various phonemic classes. These bands then form a feature set that feeds into an LSTM which discerns at each time point probability distributions across all phonemes uttered by a subject. Finally, these probabilities are fed into a particle filtering algorithm which incorporates prior knowledge of the English language to output text corresponding to the decoded word. Performance of this model on data obtained from six patients shows encouragingly high levels of accuracy at speeds and bit rates significantly higher than existing BCI communication systems. Further, in producing an output, our network abstains from constraining the reconstructed word to be from a given bag-of-words, unlike previous studies. The success of our proposed approach, offers promise for the employment of a BCI interface by patients in unfettered, naturalistic environments.