 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
Feb 26, 2026Generating realistic conversational gestures are essential for achieving natural, socially engaging interactions with digital humans. However, existing methods typically map a single audio stream to a single speaker's motion, without considering social context or modeling the mutual dynamics between two people engaging in conversation. We present DyaDiT, a multi-modal diffusion transformer that generates contextually appropriate human motion from dyadic audio signals. Trained on Seamless Interaction Dataset, DyaDiT takes dyadic audio with optional social-context tokens to produce context-appropriate motion. It fuses information from both speakers to capture interaction dynamics, uses a motion dictionary to encode motion priors, and can optionally utilize the conversational partner's gestures to produce more responsive motion. We evaluate DyaDiT on standard motion generation metrics and conduct quantitative user studies, demonstrating that it not only surpasses existing methods on objective metrics but is also strongly preferred by users, highlighting its robustness and socially favorable motion generation. Code and models will be released upon acceptance.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
UniLS: End-to-End Audio-Driven Avatars for Unified Listening and Speaking
Dec 10, 2025Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Dec 08, 2025



We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.
Egocentric Action-aware Inertial Localization in Point Clouds
May 20, 2025



This paper presents a novel inertial localization framework named Egocentric Action-aware Inertial Localization (EAIL), which leverages egocentric action cues from head-mounted IMU signals to localize the target individual within a 3D point cloud. Human inertial localization is challenging due to IMU sensor noise that causes trajectory drift over time. The diversity of human actions further complicates IMU signal processing by introducing various motion patterns. Nevertheless, we observe that some actions observed through the head-mounted IMU correlate with spatial environmental structures (e.g., bending down to look inside an oven, washing dishes next to a sink), thereby serving as spatial anchors to compensate for the localization drift. The proposed EAIL framework learns such correlations via hierarchical multi-modal alignment. By assuming that the 3D point cloud of the environment is available, it contrastively learns modality encoders that align short-term egocentric action cues in IMU signals with local environmental features in the point cloud. These encoders are then used in reasoning the IMU data and the point cloud over time and space to perform inertial localization. Interestingly, these encoders can further be utilized to recognize the corresponding sequence of actions as a by-product. Extensive experiments demonstrate the effectiveness of the proposed framework over state-of-the-art inertial localization and inertial action recognition baselines.
ActionVOS: Actions as Prompts for Video Object Segmentation
Jul 10, 2024



Delving into the realm of egocentric vision, the advancement of referring video object segmentation (RVOS) stands as pivotal in understanding human activities. However, existing RVOS task primarily relies on static attributes such as object names to segment target objects, posing challenges in distinguishing target objects from background objects and in identifying objects undergoing state changes. To address these problems, this work proposes a novel action-aware RVOS setting called ActionVOS, aiming at segmenting only active objects in egocentric videos using human actions as a key language prompt. This is because human actions precisely describe the behavior of humans, thereby helping to identify the objects truly involved in the interaction and to understand possible state changes. We also build a method tailored to work under this specific setting. Specifically, we develop an action-aware labeling module with an efficient action-guided focal loss. Such designs enable ActionVOS model to prioritize active objects with existing readily-available annotations. Experimental results on VISOR dataset reveal that ActionVOS significantly reduces the mis-segmentation of inactive objects, confirming that actions help the ActionVOS model understand objects' involvement. Further evaluations on VOST and VSCOS datasets show that the novel ActionVOS setting enhances segmentation performance when encountering challenging circumstances involving object state changes. We will make our implementation available at https://github.com/ut-vision/ActionVOS.
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Jul 09, 2024Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being robust to lighting variation and occlusion. While these characteristics are intuitively valuable to help egocentric action recognition, the potential of IMUs remains under-explored. In this work, we present a novel method for action recognition that integrates motion data from body-worn IMUs with egocentric video. Due to the scarcity of labeled multimodal data, we design an MAE-based self-supervised pretraining method, obtaining strong multi-modal representations via modeling the natural correlation between visual and motion signals. To model the complex relation of multiple IMU devices placed across the body, we exploit the collaborative dynamics in multiple IMU devices and propose to embed the relative motion features of human joints into a graph structure. Experiments show our method can achieve state-of-the-art performance on multiple public datasets. The effectiveness of our MAE-based pretraining and graph-based IMU modeling are further validated by experiments in more challenging scenarios, including partially missing IMU devices and video quality corruption, promoting more flexible usages in the real world.
Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
Mar 09, 2024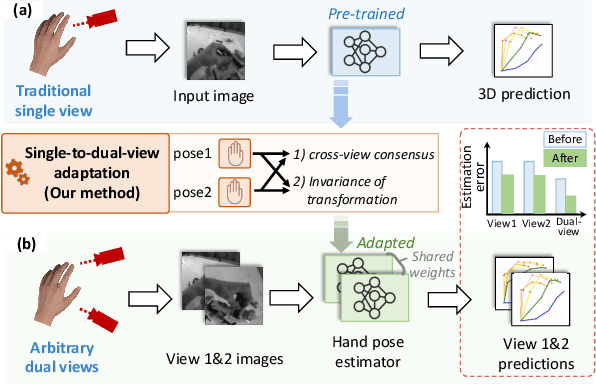

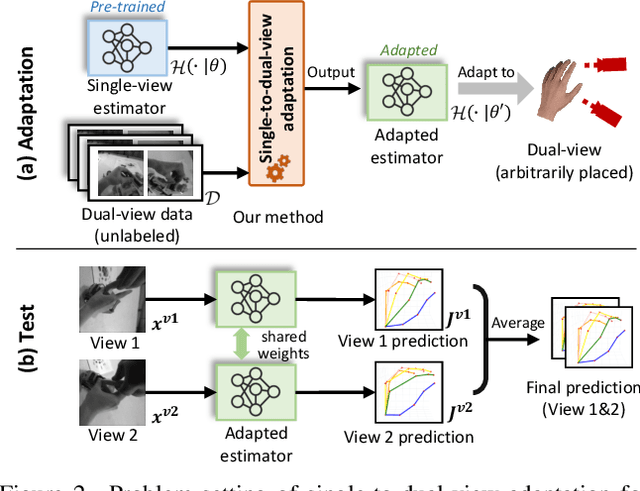
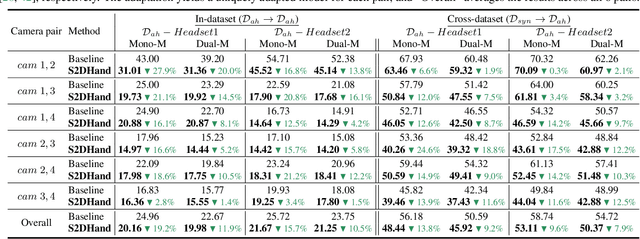
The pursuit of accurate 3D hand pose estimation stands as a keystone for understanding human activity in the realm of egocentric vision. The majority of existing estimation methods still rely on single-view images as input, leading to potential limitations, e.g., limited field-of-view and ambiguity in depth. To address these problems, adding another camera to better capture the shape of hands is a practical direction. However, existing multi-view hand pose estimation methods suffer from two main drawbacks: 1) Requiring multi-view annotations for training, which are expensive. 2) During testing, the model becomes inapplicable if camera parameters/layout are not the same as those used in training. In this paper, we propose a novel Single-to-Dual-view adaptation (S2DHand) solution that adapts a pre-trained single-view estimator to dual views. Compared with existing multi-view training methods, 1) our adaptation process is unsupervised, eliminating the need for multi-view annotation. 2) Moreover, our method can handle arbitrary dual-view pairs with unknown camera parameters, making the model applicable to diverse camera settings. Specifically, S2DHand is built on certain stereo constraints, including pair-wise cross-view consensus and invariance of transformation between both views. These two stereo constraints are used in a complementary manner to generate pseudo-labels, allowing reliable adaptation. Evaluation results reveal that S2DHand achieves significant improvements on arbitrary camera pairs under both in-dataset and cross-dataset settings, and outperforms existing adaptation methods with leading performance. Project page: https://github.com/MickeyLLG/S2DHand.
UVAGaze: Unsupervised 1-to-2 Views Adaptation for Gaze Estimation
Dec 25, 2023



Gaze estimation has become a subject of growing interest in recent research. Most of the current methods rely on single-view facial images as input. Yet, it is hard for these approaches to handle large head angles, leading to potential inaccuracies in the estimation. To address this issue, adding a second-view camera can help better capture eye appearance. However, existing multi-view methods have two limitations. 1) They require multi-view annotations for training, which are expensive. 2) More importantly, during testing, the exact positions of the multiple cameras must be known and match those used in training, which limits the application scenario. To address these challenges, we propose a novel 1-view-to-2-views (1-to-2 views) adaptation solution in this paper, the Unsupervised 1-to-2 Views Adaptation framework for Gaze estimation (UVAGaze). Our method adapts a traditional single-view gaze estimator for flexibly placed dual cameras. Here, the "flexibly" means we place the dual cameras in arbitrary places regardless of the training data, without knowing their extrinsic parameters. Specifically, the UVAGaze builds a dual-view mutual supervision adaptation strategy, which takes advantage of the intrinsic consistency of gaze directions between both views. In this way, our method can not only benefit from common single-view pre-training, but also achieve more advanced dual-view gaze estimation. The experimental results show that a single-view estimator, when adapted for dual views, can achieve much higher accuracy, especially in cross-dataset settings, with a substantial improvement of 47.0%. Project page: https://github.com/MickeyLLG/UVAGaze.
Jitter Does Matter: Adapting Gaze Estimation to New Domains
Oct 05, 2022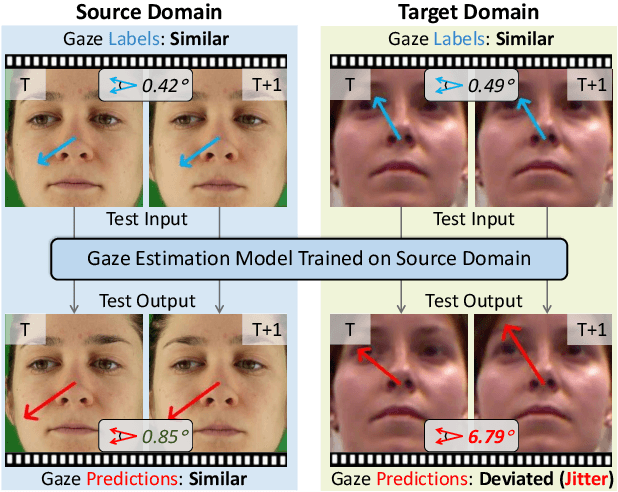
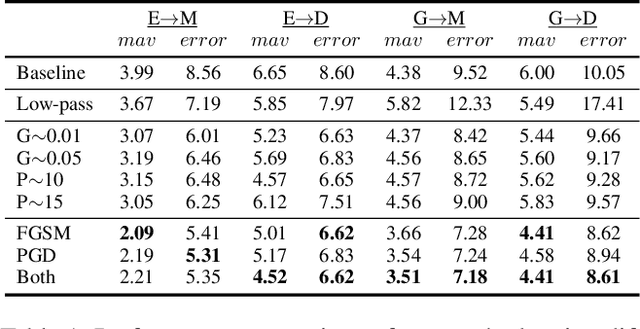
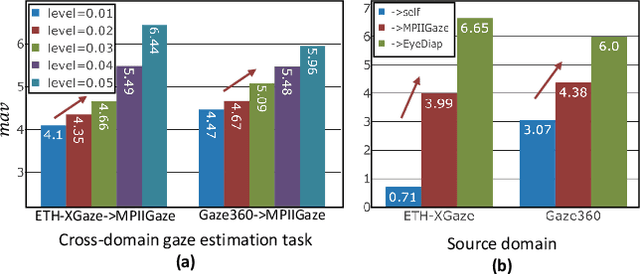
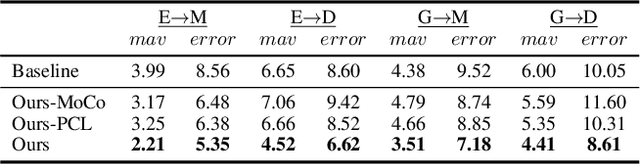
Deep neural networks have demonstrated superior performance on appearance-based gaze estimation tasks. However, due to variations in person, illuminations, and background, performance degrades dramatically when applying the model to a new domain. In this paper, we discover an interesting gaze jitter phenomenon in cross-domain gaze estimation, i.e., the gaze predictions of two similar images can be severely deviated in target domain. This is closely related to cross-domain gaze estimation tasks, but surprisingly, it has not been noticed yet previously. Therefore, we innovatively propose to utilize the gaze jitter to analyze and optimize the gaze domain adaptation task. We find that the high-frequency component (HFC) is an important factor that leads to jitter. Based on this discovery, we add high-frequency components to input images using the adversarial attack and employ contrastive learning to encourage the model to obtain similar representations between original and perturbed data, which reduces the impacts of HFC. We evaluate the proposed method on four cross-domain gaze estimation tasks, and experimental results demonstrate that it significantly reduces the gaze jitter and improves the gaze estimation performance in target domains.