 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Jul 22, 2024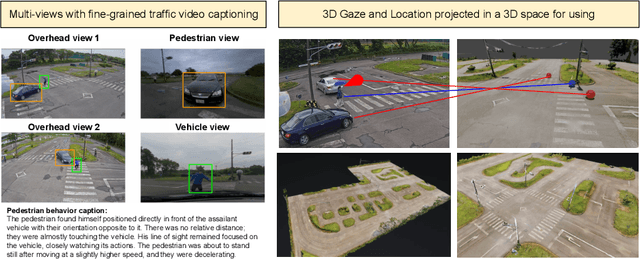
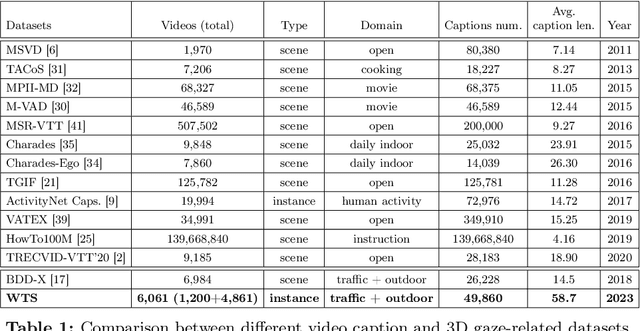
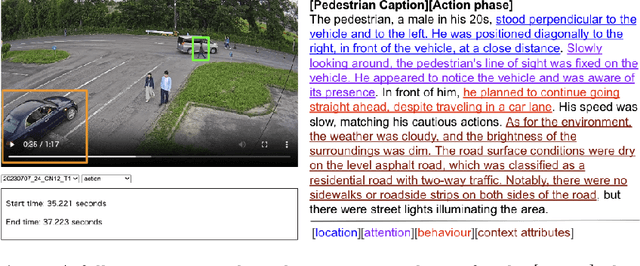
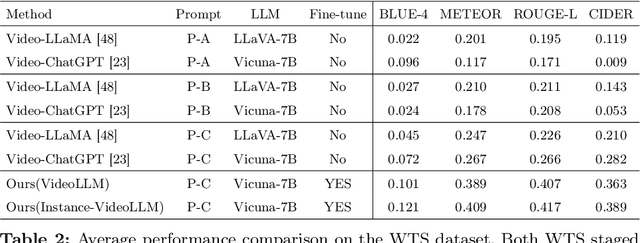
In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.
Rethinking Adversarial Examples for Location Privacy Protection
Jun 28, 2022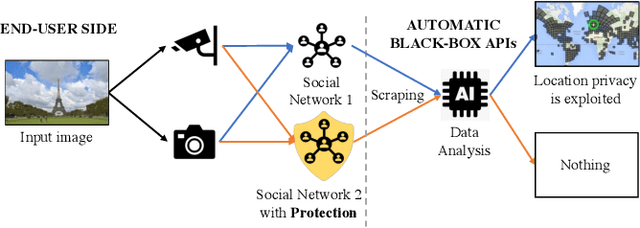



We have investigated a new application of adversarial examples, namely location privacy protection against landmark recognition systems. We introduce mask-guided multimodal projected gradient descent (MM-PGD), in which adversarial examples are trained on different deep models. Image contents are protected by analyzing the properties of regions to identify the ones most suitable for blending in adversarial examples. We investigated two region identification strategies: class activation map-based MM-PGD, in which the internal behaviors of trained deep models are targeted; and human-vision-based MM-PGD, in which regions that attract less human attention are targeted. Experiments on the Places365 dataset demonstrated that these strategies are potentially effective in defending against black-box landmark recognition systems without the need for much image manipulation.