 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Demystification of Knowledge Distillation: A Residual Network Perspective
Paper and Code
Jun 30, 2020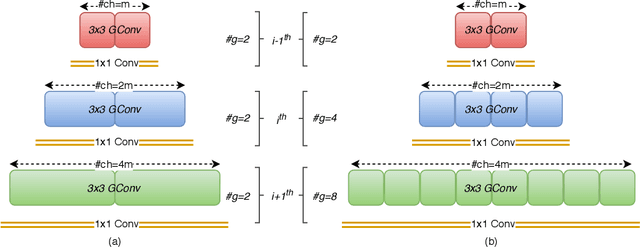
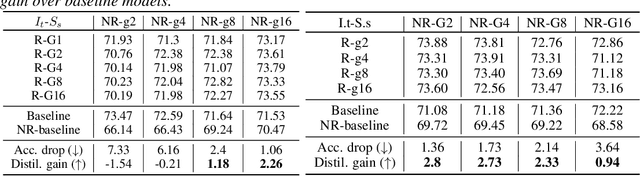
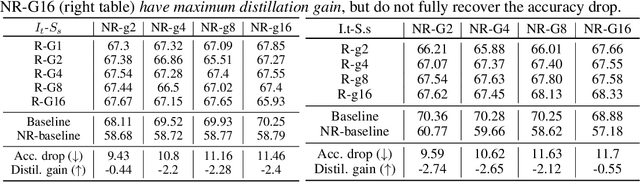
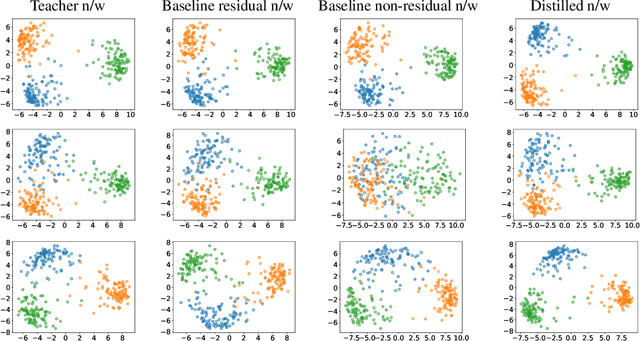
Knowledge distillation (KD) is generally considered as a technique for performing model compression and learned-label smoothing. However, in this paper, we study and investigate the KD approach from a new perspective: we study its efficacy in training a deeper network without any residual connections. We find that in most of the cases, non-residual student networks perform equally or better than their residual versions trained on raw data without KD (baseline network). Surprisingly, in some cases, they surpass the accuracy of baseline networks even with the inferior teachers. After a certain depth of non-residual student network, the accuracy drop, coming from the removal of residual connections, is substantial, and training with KD boosts the accuracy of the student up to a great extent; however, it does not fully recover the accuracy drop. Furthermore, we observe that the conventional teacher-student view of KD is incomplete and does not adequately explain our findings. We propose a novel interpretation of KD with the Trainee-Mentor hypothesis, which provides a holistic view of KD. We also present two viewpoints, loss landscape, and feature reuse, to explain the interplay between residual connections and KD. We substantiate our claims through extensive experiments on residual networks.