 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge
Mar 17, 2026Large language models (LLMs) are increasingly deployed as automated evaluators that assign numeric scores to model outputs, a paradigm known as LLM-as-a-Judge. However, standard Reinforcement Learning (RL) methods typically rely on binary rewards (e.g., 0-1 accuracy), thereby ignoring the ordinal structure inherent in regression tasks; for instance, they fail to recognize that predicting 4 is significantly better than predicting 1 when the ground truth is 5. Conversely, existing regression-aware approaches are often confined to Supervised Fine-Tuning (SFT), limiting their ability to explore optimal reasoning paths. To bridge this gap, we propose \textbf{REAL} (\underline{RE}gression-\underline{A}ware Reinforcement \underline{L}earning), a principled RL framework designed to optimize regression rewards, and also proven to be optimal for correlation metrics. A key technical challenge is that the regression objective is explicitly policy-dependent, thus invalidating standard policy gradient methods. To address this, we employ the generalized policy gradient estimator, which naturally decomposes optimization into two complementary components: (1) exploration over Chain-of-Thought (CoT) trajectory, and (2) regression-aware prediction refinement of the final score. Extensive experiments across model scales (8B to 32B) demonstrate that REAL consistently outperforms both regression-aware SFT baselines and standard RL methods, exhibiting significantly better generalization on out-of-domain benchmarks. On Qwen3-32B specifically, we achieve gains of +8.40 Pearson and +7.20 Spearman correlation over the SFT baseline, and +18.30/+11.20 over the base model. These findings highlight the critical value of integrating regression objectives into RL exploration for accurate LLM evaluation.
GIFSplat: Generative Prior-Guided Iterative Feed-Forward 3D Gaussian Splatting from Sparse Views
Feb 26, 2026Feed-forward 3D reconstruction offers substantial runtime advantages over per-scene optimization, which remains slow at inference and often fragile under sparse views. However, existing feed-forward methods still have potential for further performance gains, especially for out-of-domain data, and struggle to retain second-level inference time once a generative prior is introduced. These limitations stem from the one-shot prediction paradigm in existing feed-forward pipeline: models are strictly bounded by capacity, lack inference-time refinement, and are ill-suited for continuously injecting generative priors. We introduce GIFSplat, a purely feed-forward iterative refinement framework for 3D Gaussian Splatting from sparse unposed views. A small number of forward-only residual updates progressively refine current 3D scene using rendering evidence, achieve favorable balance between efficiency and quality. Furthermore, we distill a frozen diffusion prior into Gaussian-level cues from enhanced novel renderings without gradient backpropagation or ever-increasing view-set expansion, thereby enabling per-scene adaptation with generative prior while preserving feed-forward efficiency. Across DL3DV, RealEstate10K, and DTU, GIFSplat consistently outperforms state-of-the-art feed-forward baselines, improving PSNR by up to +2.1 dB, and it maintains second-scale inference time without requiring camera poses or any test-time gradient optimization.
A Trajectory-Based Safety Audit of Clawdbot (OpenClaw)
Feb 16, 2026Clawdbot is a self-hosted, tool-using personal AI agent with a broad action space spanning local execution and web-mediated workflows, which raises heightened safety and security concerns under ambiguity and adversarial steering. We present a trajectory-centric evaluation of Clawdbot across six risk dimensions. Our test suite samples and lightly adapts scenarios from prior agent-safety benchmarks (including ATBench and LPS-Bench) and supplements them with hand-designed cases tailored to Clawdbot's tool surface. We log complete interaction trajectories (messages, actions, tool-call arguments/outputs) and assess safety using both an automated trajectory judge (AgentDoG-Qwen3-4B) and human review. Across 34 canonical cases, we find a non-uniform safety profile: performance is generally consistent on reliability-focused tasks, while most failures arise under underspecified intent, open-ended goals, or benign-seeming jailbreak prompts, where minor misinterpretations can escalate into higher-impact tool actions. We supplemented the overall results with representative case studies and summarized the commonalities of these cases, analyzing the security vulnerabilities and typical failure modes that Clawdbot is prone to trigger in practice.
Pull Requests as a Training Signal for Repo-Level Code Editing
Feb 07, 2026Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a large codebase. While recent gains on SWE-bench rely heavily on complex agent scaffolding, it remains unclear how much of this capability can be internalised via high-quality training signals. To address this, we propose Clean Pull Request (Clean-PR), a mid-training paradigm that leverages real-world GitHub pull requests as a training signal for repository-level editing. We introduce a scalable pipeline that converts noisy pull request diffs into Search/Replace edit blocks through reconstruction and validation, resulting in the largest publicly available corpus of 2 million pull requests spanning 12 programming languages. Using this training signal, we perform a mid-training stage followed by an agentless-aligned supervised fine-tuning process with error-driven data augmentation. On SWE-bench, our model significantly outperforms the instruction-tuned baseline, achieving absolute improvements of 13.6% on SWE-bench Lite and 12.3% on SWE-bench Verified. These results demonstrate that repository-level code understanding and editing capabilities can be effectively internalised into model weights under a simplified, agentless protocol, without relying on heavy inference-time scaffolding.
LPS-Bench: Benchmarking Safety Awareness of Computer-Use Agents in Long-Horizon Planning under Benign and Adversarial Scenarios
Feb 03, 2026Computer-use agents (CUAs) that interact with real computer systems can perform automated tasks but face critical safety risks. Ambiguous instructions may trigger harmful actions, and adversarial users can manipulate tool execution to achieve malicious goals. Existing benchmarks mostly focus on short-horizon or GUI-based tasks, evaluating on execution-time errors but overlooking the ability to anticipate planning-time risks. To fill this gap, we present LPS-Bench, a benchmark that evaluates the planning-time safety awareness of MCP-based CUAs under long-horizon tasks, covering both benign and adversarial interactions across 65 scenarios of 7 task domains and 9 risk types. We introduce a multi-agent automated pipeline for scalable data generation and adopt an LLM-as-a-judge evaluation protocol to assess safety awareness through the planning trajectory. Experiments reveal substantial deficiencies in existing CUAs' ability to maintain safe behavior. We further analyze the risks and propose mitigation strategies to improve long-horizon planning safety in MCP-based CUA systems. We open-source our code at https://github.com/tychenn/LPS-Bench.
FRoD: Full-Rank Efficient Fine-Tuning with Rotational Degrees for Fast Convergence
Dec 29, 2025Parameter-efficient fine-tuning (PEFT) methods have emerged as a practical solution for adapting large foundation models to downstream tasks, reducing computational and memory costs by updating only a small subset of parameters. Among them, approaches like LoRA aim to strike a balance between efficiency and expressiveness, but often suffer from slow convergence and limited adaptation capacity due to their inherent low-rank constraints. This trade-off hampers the ability of PEFT methods to capture complex patterns needed for diverse tasks. To address these challenges, we propose FRoD, a novel fine-tuning method that combines hierarchical joint decomposition with rotational degrees of freedom. By extracting a globally shared basis across layers and injecting sparse, learnable perturbations into scaling factors for flexible full-rank updates, FRoD enhances expressiveness and efficiency, leading to faster and more robust convergence. On 20 benchmarks spanning vision, reasoning, and language understanding, FRoD matches full model fine-tuning in accuracy, while using only 1.72% of trainable parameters under identical training budgets.
Towards Long-window Anchoring in Vision-Language Model Distillation
Dec 25, 2025While large vision-language models (VLMs) demonstrate strong long-context understanding, their prevalent small branches fail on linguistics-photography alignment for a limited window size. We discover that knowledge distillation improves students' capability as a complement to Rotary Position Embeddings (RoPE) on window sizes (anchored from large models). Building on this insight, we propose LAid, which directly aims at the transfer of long-range attention mechanisms through two complementary components: (1) a progressive distance-weighted attention matching that dynamically emphasizes longer position differences during training, and (2) a learnable RoPE response gain modulation that selectively amplifies position sensitivity where needed. Extensive experiments across multiple model families demonstrate that LAid-distilled models achieve up to 3.2 times longer effective context windows compared to baseline small models, while maintaining or improving performance on standard VL benchmarks. Spectral analysis also suggests that LAid successfully preserves crucial low-frequency attention components that conventional methods fail to transfer. Our work not only provides practical techniques for building more efficient long-context VLMs but also offers theoretical insights into how positional understanding emerges and transfers during distillation.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025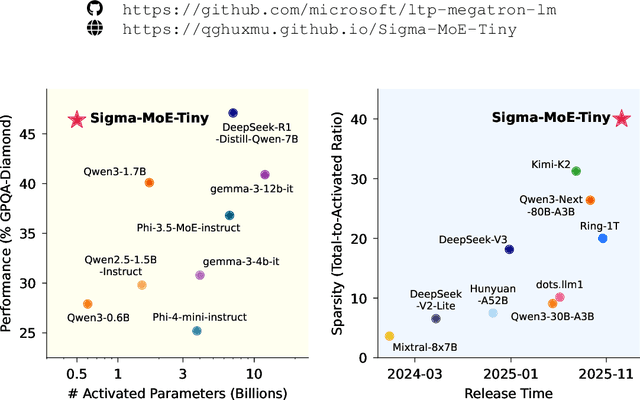

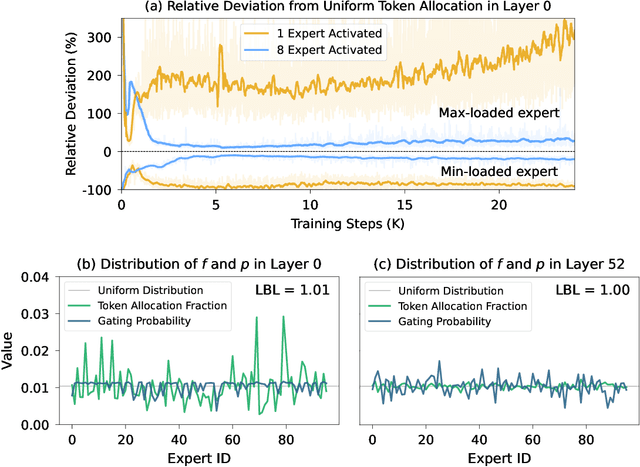
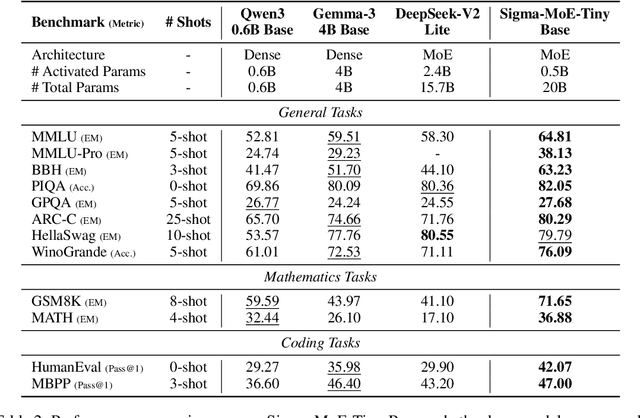
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025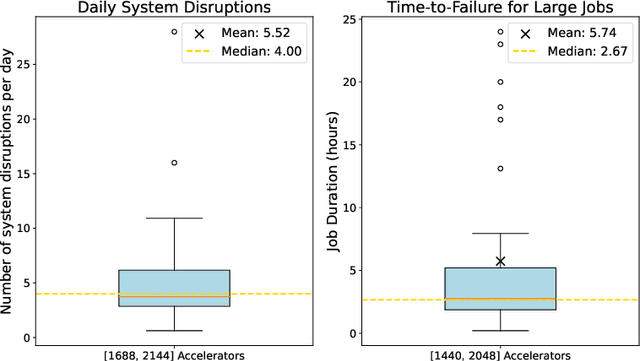

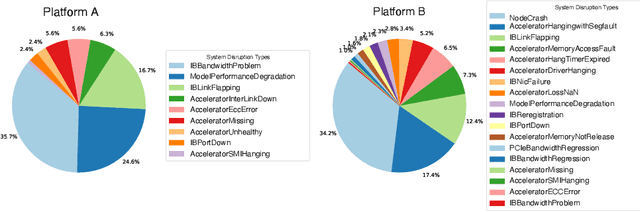

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Fine-Tuned LLMs Know They Don't Know: A Parameter-Efficient Approach to Recovering Honesty
Nov 17, 2025The honesty of Large Language Models (LLMs) is increasingly important for safe deployment in high-stakes domains. However, this crucial trait is severely undermined by supervised fine-tuning (SFT), a common technique for model specialization. Existing recovery methods rely on data-intensive global parameter adjustments, implicitly assuming that SFT deeply corrupts the models' ability to recognize their knowledge boundaries. However, we observe that fine-tuned LLMs still preserve this ability; what is damaged is their capacity to faithfully express that awareness. Building on this, we propose Honesty-Critical Neurons Restoration (HCNR) to surgically repair this suppressed capacity. HCNR identifies and restores key expression-governing neurons to their pre-trained state while harmonizing them with task-oriented neurons via Hessian-guided compensation. Experiments on four QA tasks and five LLM families demonstrate that HCNR effectively recovers 33.25% of the compromised honesty while achieving at least 2.23x speedup with over 10x less data compared to baseline methods, offering a practical solution for trustworthy LLM deployment.