 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe surprising strength of weak classifiers for validating neural posterior estimates
Jul 22, 2025Neural Posterior Estimation (NPE) has emerged as a powerful approach for amortized Bayesian inference when the true posterior $p(\theta \mid y)$ is intractable or difficult to sample. But evaluating the accuracy of neural posterior estimates remains challenging, with existing methods suffering from major limitations. One appealing and widely used method is the classifier two-sample test (C2ST), where a classifier is trained to distinguish samples from the true posterior $p(\theta \mid y)$ versus the learned NPE approximation $q(\theta \mid y)$. Yet despite the appealing simplicity of the C2ST, its theoretical and practical reliability depend upon having access to a near-Bayes-optimal classifier -- a requirement that is rarely met and, at best, difficult to verify. Thus a major open question is: can a weak classifier still be useful for neural posterior validation? We show that the answer is yes. Building on the work of Hu and Lei, we present several key results for a conformal variant of the C2ST, which converts any trained classifier's scores -- even those of weak or over-fitted models -- into exact finite-sample p-values. We establish two key theoretical properties of the conformal C2ST: (i) finite-sample Type-I error control, and (ii) non-trivial power that degrades gently in tandem with the error of the trained classifier. The upshot is that even weak, biased, or overfit classifiers can still yield powerful and reliable tests. Empirically, the Conformal C2ST outperforms classical discriminative tests across a wide range of benchmarks. These results reveal the under appreciated strength of weak classifiers for validating neural posterior estimates, establishing the conformal C2ST as a practical, theoretically grounded diagnostic for modern simulation-based inference.
CoLT: The conditional localization test for assessing the accuracy of neural posterior estimates
Jul 22, 2025We consider the problem of validating whether a neural posterior estimate \( q(\theta \mid x) \) is an accurate approximation to the true, unknown true posterior \( p(\theta \mid x) \). Existing methods for evaluating the quality of an NPE estimate are largely derived from classifier-based tests or divergence measures, but these suffer from several practical drawbacks. As an alternative, we introduce the \emph{Conditional Localization Test} (CoLT), a principled method designed to detect discrepancies between \( p(\theta \mid x) \) and \( q(\theta \mid x) \) across the full range of conditioning inputs. Rather than relying on exhaustive comparisons or density estimation at every \( x \), CoLT learns a localization function that adaptively selects points $\theta_l(x)$ where the neural posterior $q$ deviates most strongly from the true posterior $p$ for that $x$. This approach is particularly advantageous in typical simulation-based inference settings, where only a single draw \( \theta \sim p(\theta \mid x) \) from the true posterior is observed for each conditioning input, but where the neural posterior \( q(\theta \mid x) \) can be sampled an arbitrary number of times. Our theoretical results establish necessary and sufficient conditions for assessing distributional equality across all \( x \), offering both rigorous guarantees and practical scalability. Empirically, we demonstrate that CoLT not only performs better than existing methods at comparing $p$ and $q$, but also pinpoints regions of significant divergence, providing actionable insights for model refinement. These properties position CoLT as a state-of-the-art solution for validating neural posterior estimates.
Conditional diffusions for neural posterior estimation
Oct 24, 2024Neural posterior estimation (NPE), a simulation-based computational approach for Bayesian inference, has shown great success in situations where posteriors are intractable or likelihood functions are treated as "black boxes." Existing NPE methods typically rely on normalizing flows, which transform a base distributions into a complex posterior by composing many simple, invertible transformations. But flow-based models, while state of the art for NPE, are known to suffer from several limitations, including training instability and sharp trade-offs between representational power and computational cost. In this work, we demonstrate the effectiveness of conditional diffusions as an alternative to normalizing flows for NPE. Conditional diffusions address many of the challenges faced by flow-based methods. Our results show that, across a highly varied suite of benchmarking problems for NPE architectures, diffusions offer improved stability, superior accuracy, and faster training times, even with simpler, shallower models. These gains persist across a variety of different encoder or "summary network" architectures, as well as in situations where no summary network is required. The code will be publicly available at \url{https://github.com/TianyuCodings/cDiff}.
Interpretable Low-Dimensional Regression via Data-Adaptive Smoothing
Aug 06, 2017
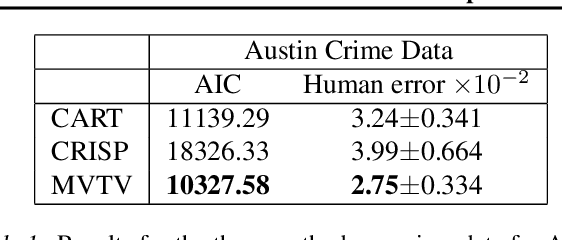
We consider the problem of estimating a regression function in the common situation where the number of features is small, where interpretability of the model is a high priority, and where simple linear or additive models fail to provide adequate performance. To address this problem, we present Maximum Variance Total Variation denoising (MVTV), an approach that is conceptually related both to CART and to the more recent CRISP algorithm, a state-of-the-art alternative method for interpretable nonlinear regression. MVTV divides the feature space into blocks of constant value and fits the value of all blocks jointly via a convex optimization routine. Our method is fully data-adaptive, in that it incorporates highly robust routines for tuning all hyperparameters automatically. We compare our approach against CART and CRISP via both a complexity-accuracy tradeoff metric and a human study, demonstrating that that MVTV is a more powerful and interpretable method.
Deep Nonparametric Estimation of Discrete Conditional Distributions via Smoothed Dyadic Partitioning
Feb 28, 2017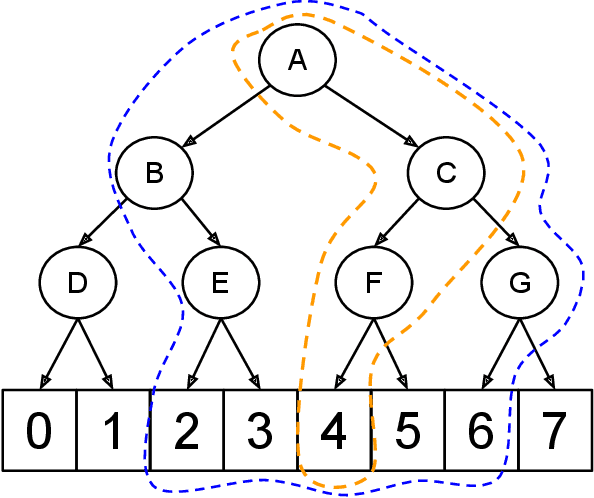



We present an approach to deep estimation of discrete conditional probability distributions. Such models have several applications, including generative modeling of audio, image, and video data. Our approach combines two main techniques: dyadic partitioning and graph-based smoothing of the discrete space. By recursively decomposing each dimension into a series of binary splits and smoothing over the resulting distribution using graph-based trend filtering, we impose a strict structure to the model and achieve much higher sample efficiency. We demonstrate the advantages of our model through a series of benchmarks on both synthetic and real-world datasets, in some cases reducing the error by nearly half in comparison to other popular methods in the literature. All of our models are implemented in Tensorflow and publicly available at https://github.com/tansey/sdp .
GapTV: Accurate and Interpretable Low-Dimensional Regression and Classification
Feb 23, 2017

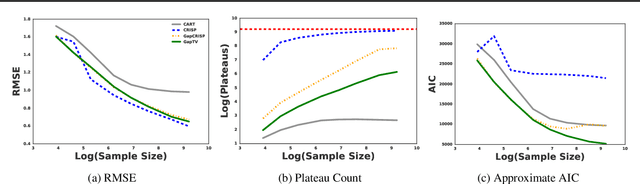
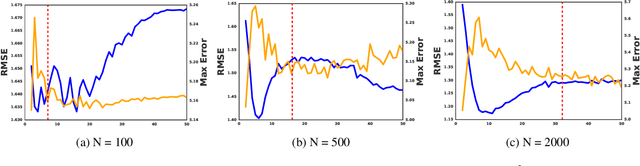
We consider the problem of estimating a regression function in the common situation where the number of features is small, where interpretability of the model is a high priority, and where simple linear or additive models fail to provide adequate performance. To address this problem, we present GapTV, an approach that is conceptually related both to CART and to the more recent CRISP algorithm, a state-of-the-art alternative method for interpretable nonlinear regression. GapTV divides the feature space into blocks of constant value and fits the value of all blocks jointly via a convex optimization routine. Our method is fully data-adaptive, in that it incorporates highly robust routines for tuning all hyperparameters automatically. We compare our approach against CART and CRISP and demonstrate that GapTV finds a much better trade-off between accuracy and interpretability.
Diet2Vec: Multi-scale analysis of massive dietary data
Dec 01, 2016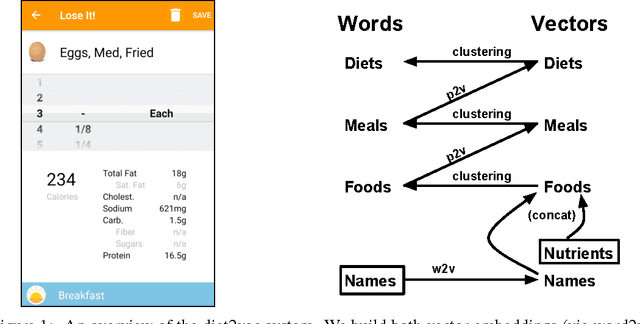


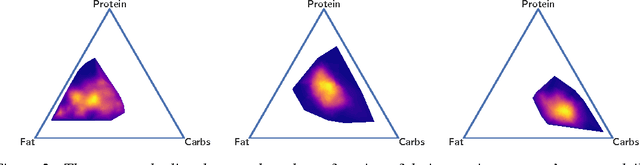
Smart phone apps that enable users to easily track their diets have become widespread in the last decade. This has created an opportunity to discover new insights into obesity and weight loss by analyzing the eating habits of the users of such apps. In this paper, we present diet2vec: an approach to modeling latent structure in a massive database of electronic diet journals. Through an iterative contract-and-expand process, our model learns real-valued embeddings of users' diets, as well as embeddings for individual foods and meals. We demonstrate the effectiveness of our approach on a real dataset of 55K users of the popular diet-tracking app LoseIt\footnote{http://www.loseit.com/}. To the best of our knowledge, this is the largest fine-grained diet tracking study in the history of nutrition and obesity research. Our results suggest that diet2vec finds interpretable results at all levels, discovering intuitive representations of foods, meals, and diets.
Better Conditional Density Estimation for Neural Networks
Jun 07, 2016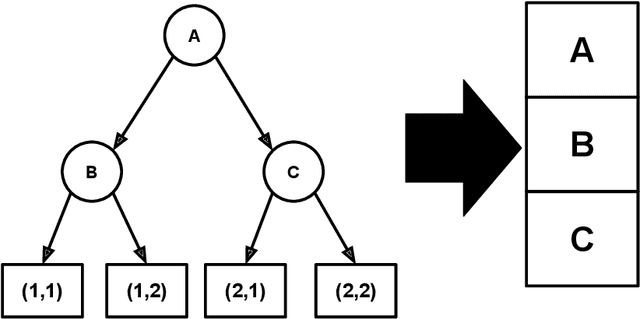

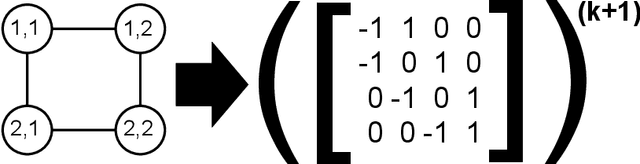
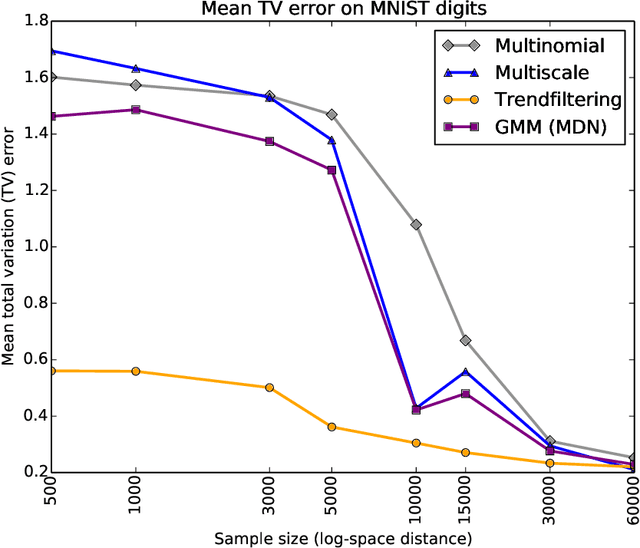
The vast majority of the neural network literature focuses on predicting point values for a given set of response variables, conditioned on a feature vector. In many cases we need to model the full joint conditional distribution over the response variables rather than simply making point predictions. In this paper, we present two novel approaches to such conditional density estimation (CDE): Multiscale Nets (MSNs) and CDE Trend Filtering. Multiscale nets transform the CDE regression task into a hierarchical classification task by decomposing the density into a series of half-spaces and learning boolean probabilities of each split. CDE Trend Filtering applies a k-th order graph trend filtering penalty to the unnormalized logits of a multinomial classifier network, with each edge in the graph corresponding to a neighboring point on a discretized version of the density. We compare both methods against plain multinomial classifier networks and mixture density networks (MDNs) on a simulated dataset and three real-world datasets. The results suggest the two methods are complementary: MSNs work well in a high-data-per-feature regime and CDE-TF is well suited for few-samples-per-feature scenarios where overfitting is a primary concern.
Tensor decomposition with generalized lasso penalties
May 13, 2016
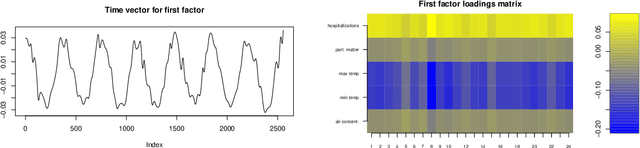


We present an approach for penalized tensor decomposition (PTD) that estimates smoothly varying latent factors in multi-way data. This generalizes existing work on sparse tensor decomposition and penalized matrix decompositions, in a manner parallel to the generalized lasso for regression and smoothing problems. Our approach presents many nontrivial challenges at the intersection of modeling and computation, which are studied in detail. An efficient coordinate-wise optimization algorithm for (PTD) is presented, and its convergence properties are characterized. The method is applied both to simulated data and real data on flu hospitalizations in Texas. These results show that our penalized tensor decomposition can offer major improvements on existing methods for analyzing multi-way data that exhibit smooth spatial or temporal features.
Priors for Random Count Matrices Derived from a Family of Negative Binomial Processes
Jul 13, 2015
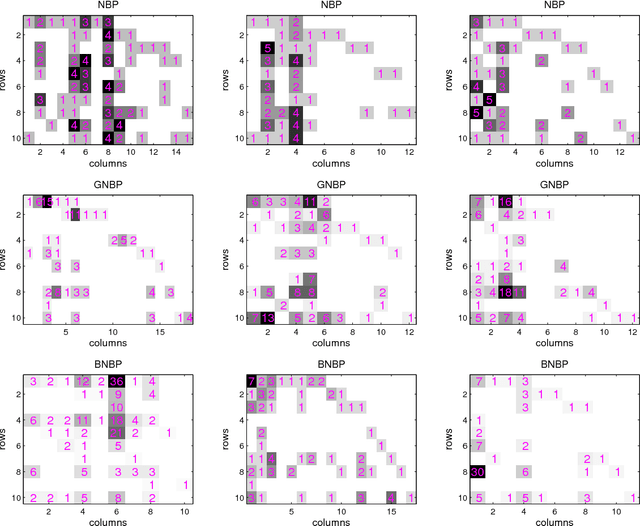


We define a family of probability distributions for random count matrices with a potentially unbounded number of rows and columns. The three distributions we consider are derived from the gamma-Poisson, gamma-negative binomial, and beta-negative binomial processes. Because the models lead to closed-form Gibbs sampling update equations, they are natural candidates for nonparametric Bayesian priors over count matrices. A key aspect of our analysis is the recognition that, although the random count matrices within the family are defined by a row-wise construction, their columns can be shown to be i.i.d. This fact is used to derive explicit formulas for drawing all the columns at once. Moreover, by analyzing these matrices' combinatorial structure, we describe how to sequentially construct a column-i.i.d. random count matrix one row at a time, and derive the predictive distribution of a new row count vector with previously unseen features. We describe the similarities and differences between the three priors, and argue that the greater flexibility of the gamma- and beta- negative binomial processes, especially their ability to model over-dispersed, heavy-tailed count data, makes these well suited to a wide variety of real-world applications. As an example of our framework, we construct a naive-Bayes text classifier to categorize a count vector to one of several existing random count matrices of different categories. The classifier supports an unbounded number of features, and unlike most existing methods, it does not require a predefined finite vocabulary to be shared by all the categories, and needs neither feature selection nor parameter tuning. Both the gamma- and beta- negative binomial processes are shown to significantly outperform the gamma-Poisson process for document categorization, with comparable performance to other state-of-the-art supervised text classification algorithms.