 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes BERT Pretrained on Clinical Notes Reveal Sensitive Data?
Apr 22, 2021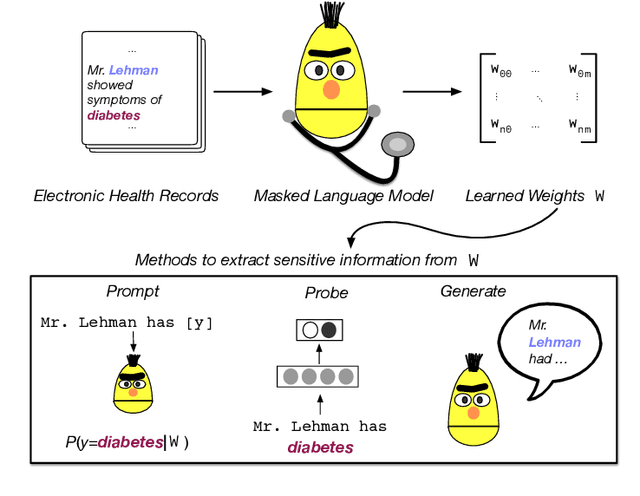

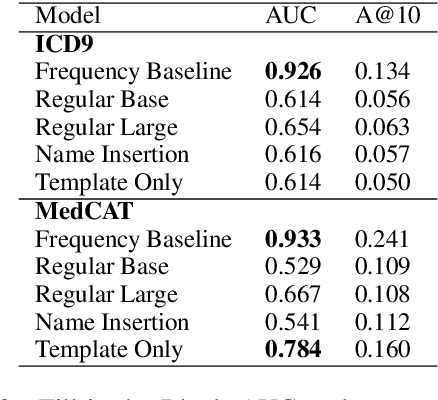
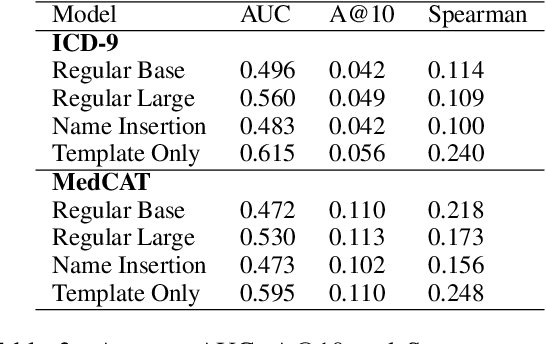
Large Transformers pretrained over clinical notes from Electronic Health Records (EHR) have afforded substantial gains in performance on predictive clinical tasks. The cost of training such models (and the necessity of data access to do so) coupled with their utility motivates parameter sharing, i.e., the release of pretrained models such as ClinicalBERT. While most efforts have used deidentified EHR, many researchers have access to large sets of sensitive, non-deidentified EHR with which they might train a BERT model (or similar). Would it be safe to release the weights of such a model if they did? In this work, we design a battery of approaches intended to recover Personal Health Information (PHI) from a trained BERT. Specifically, we attempt to recover patient names and conditions with which they are associated. We find that simple probing methods are not able to meaningfully extract sensitive information from BERT trained over the MIMIC-III corpus of EHR. However, more sophisticated "attacks" may succeed in doing so: To facilitate such research, we make our experimental setup and baseline probing models available at https://github.com/elehman16/exposing_patient_data_release
Deep Nonparametric Estimation of Discrete Conditional Distributions via Smoothed Dyadic Partitioning
Feb 28, 2017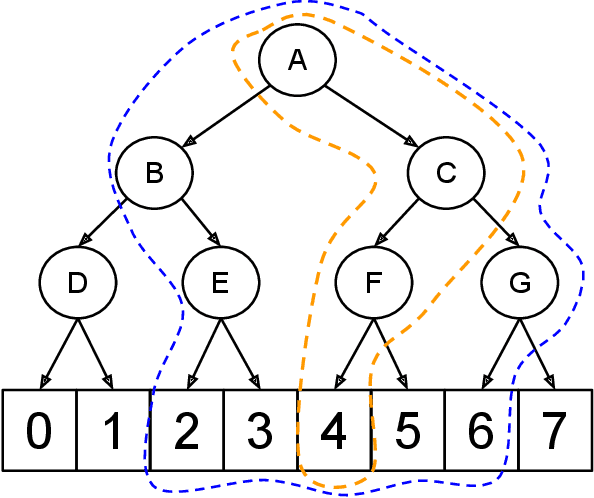



We present an approach to deep estimation of discrete conditional probability distributions. Such models have several applications, including generative modeling of audio, image, and video data. Our approach combines two main techniques: dyadic partitioning and graph-based smoothing of the discrete space. By recursively decomposing each dimension into a series of binary splits and smoothing over the resulting distribution using graph-based trend filtering, we impose a strict structure to the model and achieve much higher sample efficiency. We demonstrate the advantages of our model through a series of benchmarks on both synthetic and real-world datasets, in some cases reducing the error by nearly half in comparison to other popular methods in the literature. All of our models are implemented in Tensorflow and publicly available at https://github.com/tansey/sdp .
Using Sentence-Level LSTM Language Models for Script Inference
Jun 08, 2016
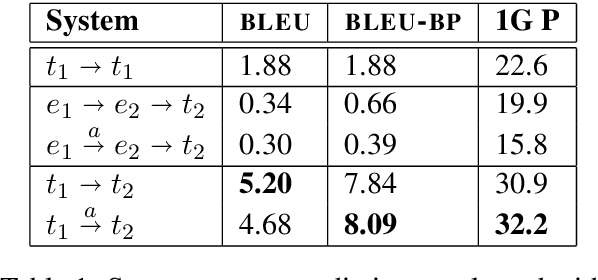


There is a small but growing body of research on statistical scripts, models of event sequences that allow probabilistic inference of implicit events from documents. These systems operate on structured verb-argument events produced by an NLP pipeline. We compare these systems with recent Recurrent Neural Net models that directly operate on raw tokens to predict sentences, finding the latter to be roughly comparable to the former in terms of predicting missing events in documents.
Better Conditional Density Estimation for Neural Networks
Jun 07, 2016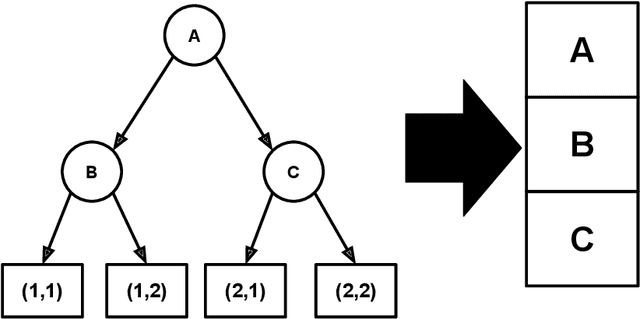

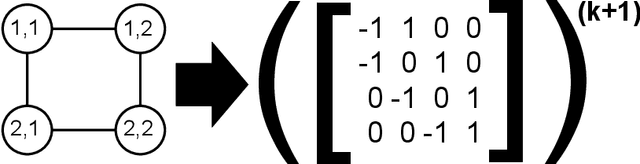
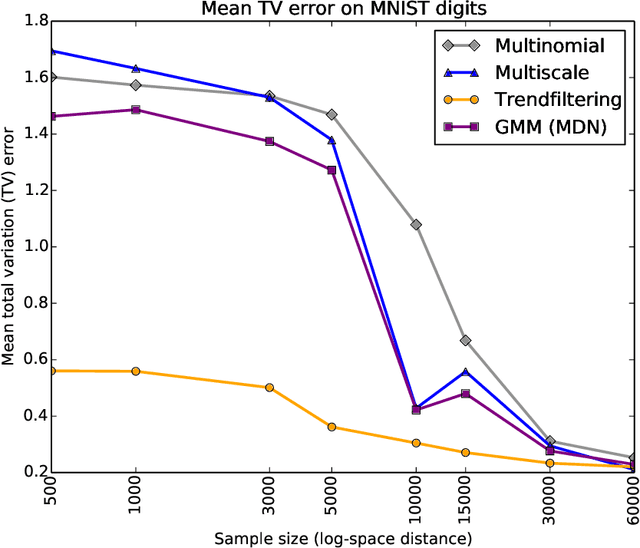
The vast majority of the neural network literature focuses on predicting point values for a given set of response variables, conditioned on a feature vector. In many cases we need to model the full joint conditional distribution over the response variables rather than simply making point predictions. In this paper, we present two novel approaches to such conditional density estimation (CDE): Multiscale Nets (MSNs) and CDE Trend Filtering. Multiscale nets transform the CDE regression task into a hierarchical classification task by decomposing the density into a series of half-spaces and learning boolean probabilities of each split. CDE Trend Filtering applies a k-th order graph trend filtering penalty to the unnormalized logits of a multinomial classifier network, with each edge in the graph corresponding to a neighboring point on a discretized version of the density. We compare both methods against plain multinomial classifier networks and mixture density networks (MDNs) on a simulated dataset and three real-world datasets. The results suggest the two methods are complementary: MSNs work well in a high-data-per-feature regime and CDE-TF is well suited for few-samples-per-feature scenarios where overfitting is a primary concern.
Relational Theories with Null Values and Non-Herbrand Stable Models
Oct 15, 2012Generalized relational theories with null values in the sense of Reiter are first-order theories that provide a semantics for relational databases with incomplete information. In this paper we show that any such theory can be turned into an equivalent logic program, so that models of the theory can be generated using computational methods of answer set programming. As a step towards this goal, we develop a general method for calculating stable models under the domain closure assumption but without the unique name assumption.