 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025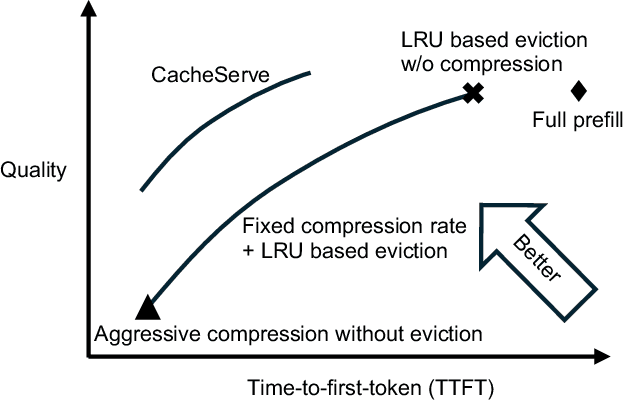
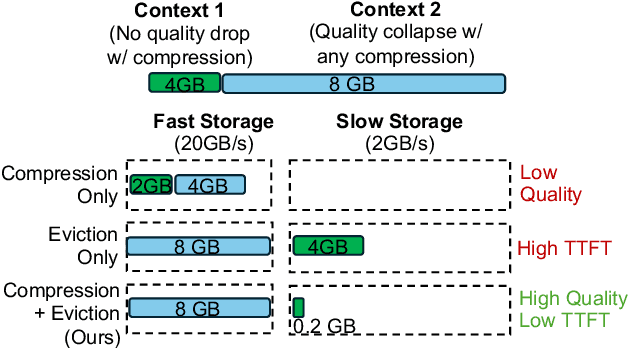
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024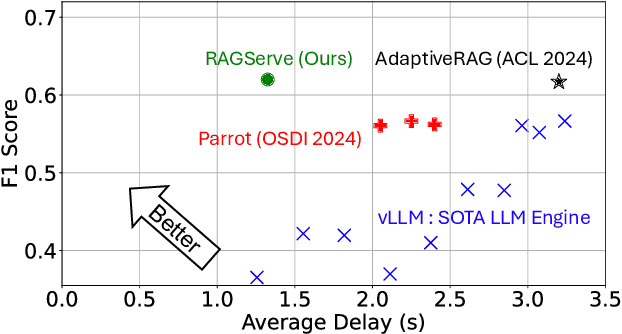

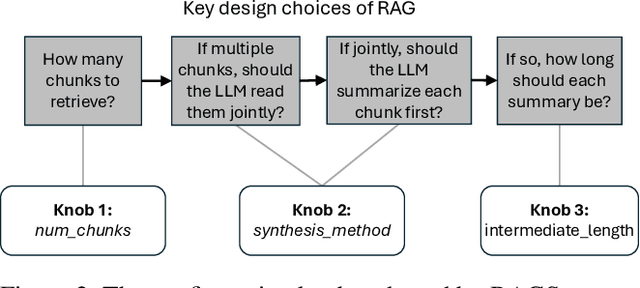
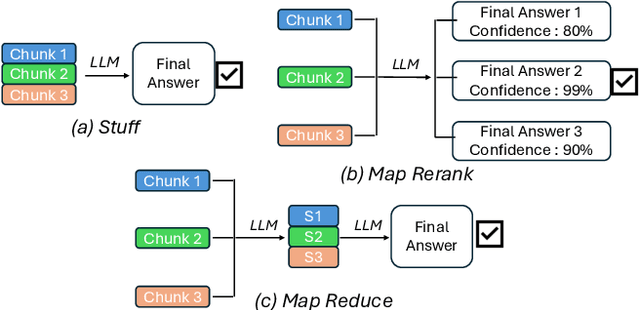
RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
LLMSteer: Improving Long-Context LLM Inference by Steering Attention on Reused Contexts
Nov 21, 2024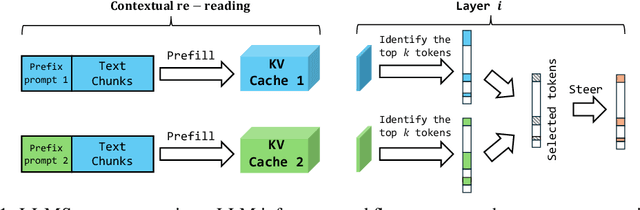
As large language models (LLMs) show impressive performance on complex tasks, they still struggle with longer contextual understanding and high computational costs. To balance efficiency and quality, we introduce LLMSteer, a fine-tuning-free framework that enhances LLMs through query-independent attention steering. Tested on popular LLMs and datasets, LLMSteer narrows the performance gap with baselines by 65.9% and reduces the runtime delay by up to 4.8x compared to recent attention steering methods.
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
May 26, 2024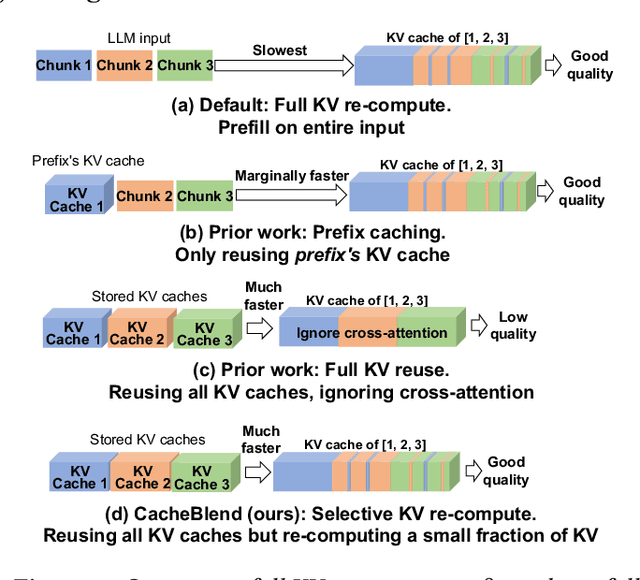
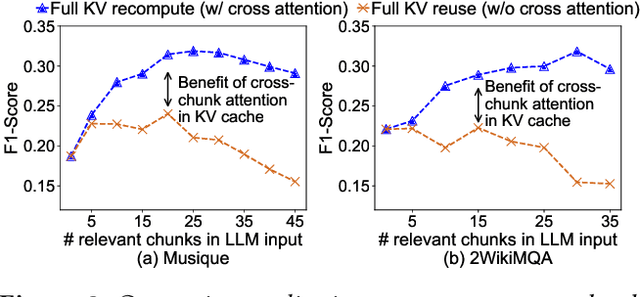
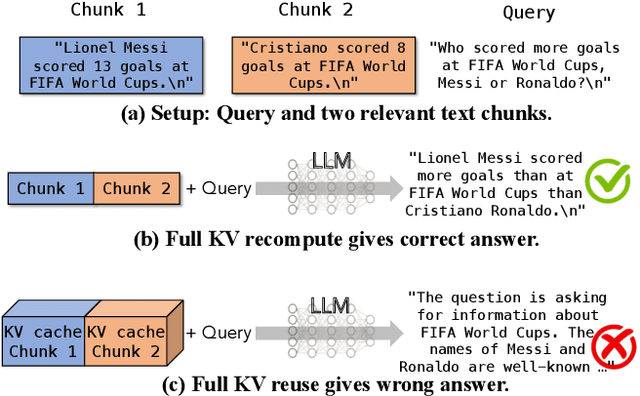
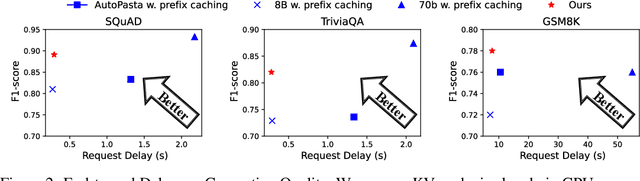
Large language models (LLMs) often incorporate multiple text chunks in their inputs to provide the necessary contexts. To speed up the prefill of the long LLM inputs, one can pre-compute the KV cache of a text and re-use the KV cache when the context is reused as the prefix of another LLM input. However, the reused text chunks are not always the input prefix, and when they are not, their precomputed KV caches cannot be directly used since they ignore the text's cross-attention with the preceding text in the LLM input. Thus, the benefits of reusing KV caches remain largely unrealized. This paper tackles just one question: when an LLM input contains multiple text chunks, how to quickly combine their precomputed KV caches in order to achieve the same generation quality as the expensive full prefill (i.e., without reusing KV cache)? We present CacheBlend, a scheme that reuses the pre-computed KV caches, regardless prefix or not, and selectively recomputes the KV values of a small subset of tokens to partially update each reused KV cache. In the meantime,the small extra delay for recomputing some tokens can be pipelined with the retrieval of KV caches within the same job,allowing CacheBlend to store KV caches in slower devices with more storage capacity while retrieving them without increasing the inference delay. By comparing CacheBlend with the state-of-the-art KV cache reusing schemes on three open-source LLMs of various sizes and four popular benchmark datasets of different tasks, we show that CacheBlend reduces time-to-first-token (TTFT) by 2.2-3.3X and increases the inference throughput by 2.8-5X, compared with full KV recompute, without compromising generation quality or incurring more storage cost.
Chatterbox: Robust Transport for LLM Token Streaming under Unstable Network
Jan 23, 2024



To render each generated token in real time, the LLM server generates response tokens one by one and streams each generated token (or group of a few tokens) through the network to the user right after it is generated, which we refer to as LLM token streaming. However, under unstable network conditions, the LLM token streaming experience could suffer greatly from stalls since one packet loss could block the rendering of tokens contained in subsequent packets even if they arrive on time. With a real-world measurement study, we show that current applications including ChatGPT, Claude, and Bard all suffer from increased stall under unstable network. For this emerging token streaming problem in LLM Chatbots, we propose a novel transport layer scheme, called Chatterbox, which puts new generated tokens as well as currently unacknowledged tokens in the next outgoing packet. This ensures that each packet contains some new tokens and can be independently rendered when received, thus avoiding aforementioned stalls caused by missing packets. Through simulation under various network conditions, we show Chatterbox reduces stall ratio (proportion of token rendering wait time) by 71.0% compared to the token streaming method commonly used by real chatbot applications and by 31.6% compared to a custom packet duplication scheme. By tailoring Chatterbox to fit the token-by-token generation of LLM, we enable the Chatbots to respond like an eloquent speaker for users to better enjoy pervasive AI.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
Automatic and Efficient Customization of Neural Networks for ML Applications
Oct 07, 2023



ML APIs have greatly relieved application developers of the burden to design and train their own neural network models -- classifying objects in an image can now be as simple as one line of Python code to call an API. However, these APIs offer the same pre-trained models regardless of how their output is used by different applications. This can be suboptimal as not all ML inference errors can cause application failures, and the distinction between inference errors that can or cannot cause failures varies greatly across applications. To tackle this problem, we first study 77 real-world applications, which collectively use six ML APIs from two providers, to reveal common patterns of how ML API output affects applications' decision processes. Inspired by the findings, we propose ChameleonAPI, an optimization framework for ML APIs, which takes effect without changing the application source code. ChameleonAPI provides application developers with a parser that automatically analyzes the application to produce an abstract of its decision process, which is then used to devise an application-specific loss function that only penalizes API output errors critical to the application. ChameleonAPI uses the loss function to efficiently train a neural network model customized for each application and deploys it to serve API invocations from the respective application via existing interface. Compared to a baseline that selects the best-of-all commercial ML API, we show that ChameleonAPI reduces incorrect application decisions by 43%.
OneAdapt: Fast Adaptation for Deep Learning Applications via Backpropagation
Oct 03, 2023



Deep learning inference on streaming media data, such as object detection in video or LiDAR feeds and text extraction from audio waves, is now ubiquitous. To achieve high inference accuracy, these applications typically require significant network bandwidth to gather high-fidelity data and extensive GPU resources to run deep neural networks (DNNs). While the high demand for network bandwidth and GPU resources could be substantially reduced by optimally adapting the configuration knobs, such as video resolution and frame rate, current adaptation techniques fail to meet three requirements simultaneously: adapt configurations (i) with minimum extra GPU or bandwidth overhead; (ii) to reach near-optimal decisions based on how the data affects the final DNN's accuracy, and (iii) do so for a range of configuration knobs. This paper presents OneAdapt, which meets these requirements by leveraging a gradient-ascent strategy to adapt configuration knobs. The key idea is to embrace DNNs' differentiability to quickly estimate the accuracy's gradient to each configuration knob, called AccGrad. Specifically, OneAdapt estimates AccGrad by multiplying two gradients: InputGrad (i.e. how each configuration knob affects the input to the DNN) and DNNGrad (i.e. how the DNN input affects the DNN inference output). We evaluate OneAdapt across five types of configurations, four analytic tasks, and five types of input data. Compared to state-of-the-art adaptation schemes, OneAdapt cuts bandwidth usage and GPU usage by 15-59% while maintaining comparable accuracy or improves accuracy by 1-5% while using equal or fewer resources.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022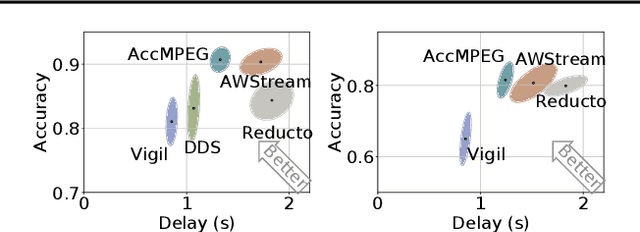
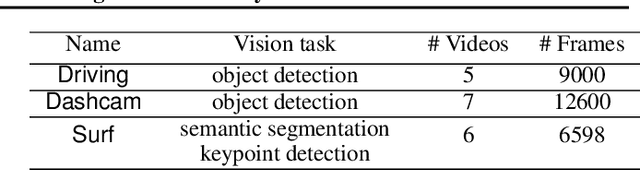
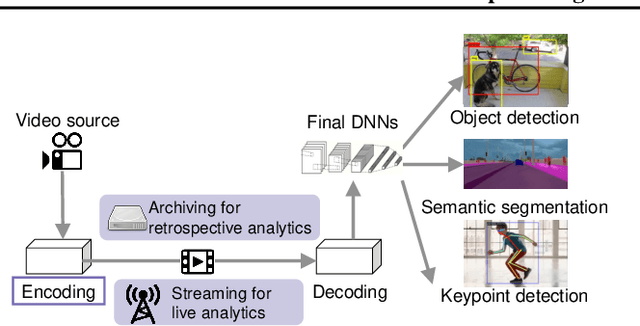

With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines