 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrace++: Loss-Resilient Real-Time Video Communication under High Network Latency
May 21, 2023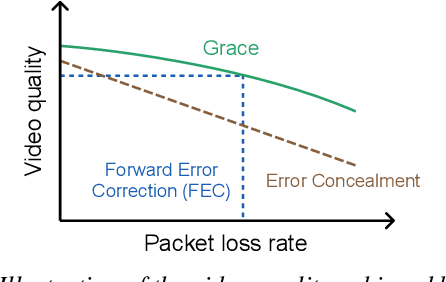
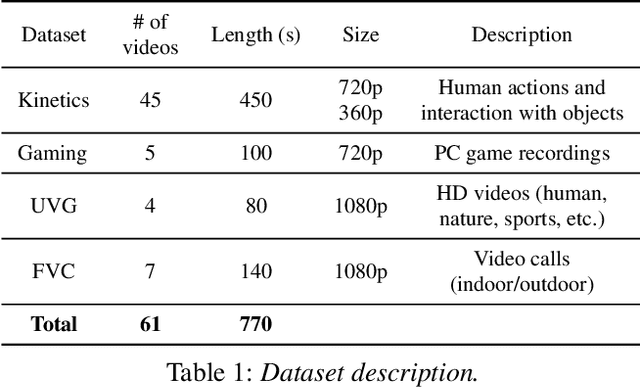

In real-time videos, resending any packets, especially in networks with high latency, can lead to stuttering, poor video quality, and user frustration. Despite extensive research, current real-time video systems still use redundancy to handle packet loss, thus compromising on quality in the the absence of packet loss. Since predicting packet loss is challenging, these systems only enhance their resilience to packet loss after it occurs, leaving some frames insufficiently protected against burst packet losses. They may also add too much redundancy even after the packet loss has subsided. We present Grace++, a new real-time video communication system. With Grace++, (i) a video frame can be decoded, as long as any non-empty subset of its packets are received, and (ii) the quality gracefully degrades as more packets are lost, and (iii) approximates that of a standard codec (like H.265) in absence of packet loss. To achieve this, Grace++ encodes and decodes frames by using neural networks (NNs). It uses a new packetization scheme that makes packet loss appear to have the same effect as randomly masking (zeroing) a subset of elements in the NN-encoded output, and the NN encoder and decoder are specially trained to achieve decent quality if a random subset of elements in the NN-encoded output are masked. Using various test videos and real network traces, we show that the quality of Grace++ is slightly lower than H.265 when no packets are lost, but significantly reduces the 95th percentile of frame delay (between encoding a frame and its decoding) by 2x when packet loss occurs compared to other loss-resilient schemes while achieving comparable quality. This is because Grace++ does not require retransmission of packets (unless all packets are lost) or skipping of frames.
AccMPEG: Optimizing Video Encoding for Video Analytics
Apr 26, 2022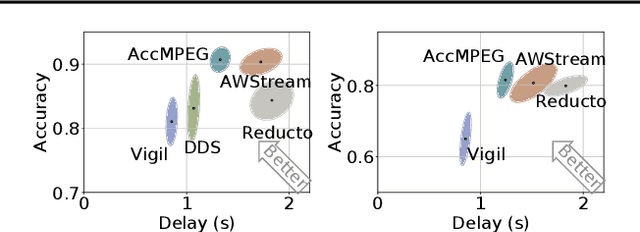
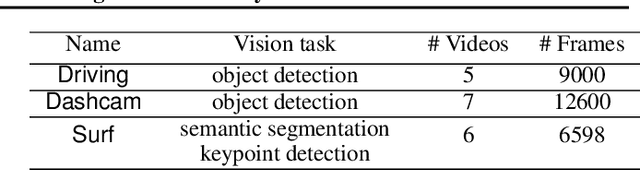
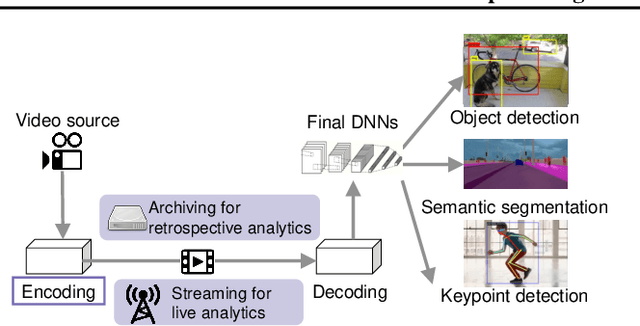

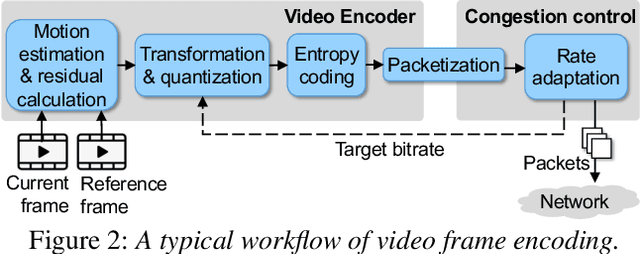
With more videos being recorded by edge sensors (cameras) and analyzed by computer-vision deep neural nets (DNNs), a new breed of video streaming systems has emerged, with the goal to compress and stream videos to remote servers in real time while preserving enough information to allow highly accurate inference by the server-side DNNs. An ideal design of the video streaming system should simultaneously meet three key requirements: (1) low latency of encoding and streaming, (2) high accuracy of server-side DNNs, and (3) low compute overheads on the camera. Unfortunately, despite many recent efforts, such video streaming system has hitherto been elusive, especially when serving advanced vision tasks such as object detection or semantic segmentation. This paper presents AccMPEG, a new video encoding and streaming system that meets all the three requirements. The key is to learn how much the encoding quality at each (16x16) macroblock can influence the server-side DNN accuracy, which we call accuracy gradient. Our insight is that these macroblock-level accuracy gradient can be inferred with sufficient precision by feeding the video frames through a cheap model. AccMPEG provides a suite of techniques that, given a new server-side DNN, can quickly create a cheap model to infer the accuracy gradient on any new frame in near realtime. Our extensive evaluation of AccMPEG on two types of edge devices (one Intel Xeon Silver 4100 CPU or NVIDIA Jetson Nano) and three vision tasks (six recent pre-trained DNNs) shows that AccMPEG (with the same camera-side compute resources) can reduce the end-to-end inference delay by 10-43% without hurting accuracy compared to the state-of-the-art baselines
Uncertainty-driven Planner for Exploration and Navigation
Feb 24, 2022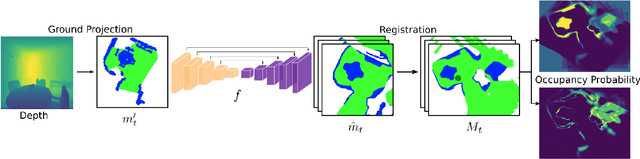
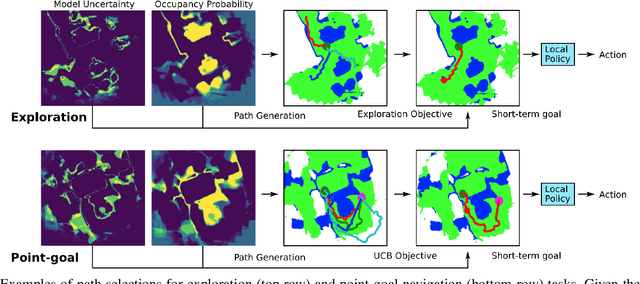
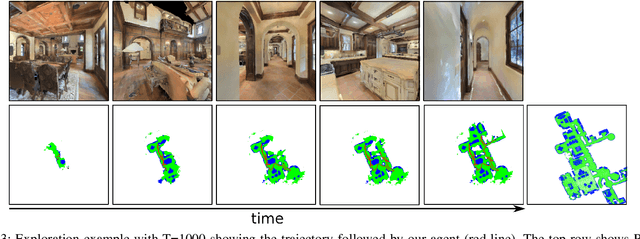
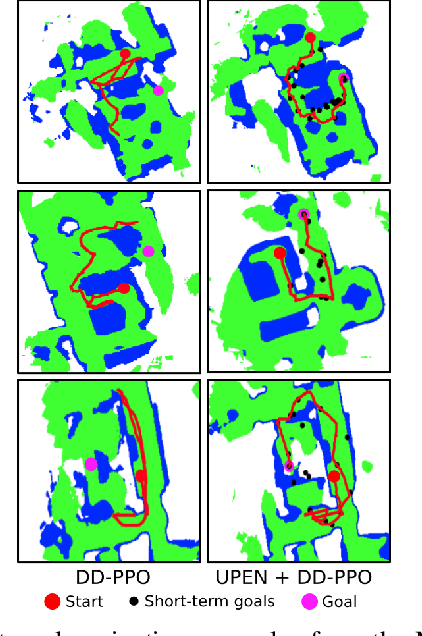
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.