 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Conformal CBF and CLF Controllers via Iterative Policy Updates
Jun 13, 2026Conformal prediction (CP) has been used to obtain probabilistic bounds on the error between a learned dynamics model and the true but unknown system. Such CP bounds can then be embedded into robust control Lyapunov function (CLF) and control barrier function (CBF) frameworks. However, such an approach does not retain stability/safety guarantees because of the distribution shift between the closed-loop trajectory distribution under the deployed CLF/CBF policy and the trajectory distribution from which the CP bound and its guarantees were derived. To address this issue, we propose an episodic framework that iteratively updates the robust conformal CLF/CBF policy while maintaining stability/safety guarantees across episodes. We achieve this by (1) using adversarially robust conformal prediction, and (2) quantifying a distribution shift budget that allows us to control how much the model error can increase across policy updates. This distribution shift budget is derived via a closed-loop trajectory sensitivity analysis, yielding an implicit and an explicit update rule for the CP bound. We analyze convergence of our algorithm, which we demonstrate on three case studies. To the best of our knowledge, these are the first results that provide stability/safety guarantees for robust conformal CBF/CLF policies.
Double Preconditioning (DoPr): Optimization for Test-Time Performance, not Validation Loss
Jun 04, 2026Many modern applications of deep learning involve training a neural network via a one-step prediction loss (e.g., $L^2$ regression, cross-entropy), but deploy the network by rolling out along its own predictions. Key examples include autoregressive language modeling, flow-based generative modeling, and robot policy learning. It is well-documented that these settings induce a phenomenon we call test-time feedback (TTF): the mismatch between the training/validation loss and downstream metrics of interest, such as task success rate and generation quality, which grows with task length. While data curation, architecture, and objective design have been proposed to combat train-test shift in TTF settings, this paper proposes optimization as a new design axis to mitigate error accumulation. Specifically, we introduce a new optimization paradigm called double-preconditioning (DoPr) uniquely tailored to the challenges of TTF. DoPr combines gradient-wise preconditioning, as in Adam and Muon, with activation-wise preconditioning (AP), such as in KFAC. We show that the addition of AP yields a drop-in intervention for increasing downstream model performance across a range of TTF settings. Interestingly, these gains in test-time performance do not consistently accompany improvements in validation loss, opening new questions about how to properly evaluate models trained with one-step supervised objectives.
Learning-Based Fault Detection for Legged Robots in Remote Dynamic Environments
Apr 03, 2026Operations in hazardous environments put humans, animals, and machines at high risk for physically damaging consequences. In contrast to humans and animals, quadruped robots cannot naturally identify and adjust their locomotion to a severely debilitated limb. The ability to detect limb damage and adjust movement to a new physical morphology is the difference between survival and death for humans and animals. The same can be said for quadruped robots autonomously carrying out remote assignments in dynamic, complex settings. This work presents the development and implementation of an off-line learning-based method to detect single limb faults from proprioceptive sensor data in a quadrupedal robot. The aim of the fault detection technique is to provide the correct output for the controller to select the appropriate tripedal gait to use given the robot's current physical morphology.
Beyond Binary Success: Sample-Efficient and Statistically Rigorous Robot Policy Comparison
Mar 13, 2026Generalist robot manipulation policies are becoming increasingly capable, but are limited in evaluation to a small number of hardware rollouts. This strong resource constraint in real-world testing necessitates both more informative performance measures and reliable and efficient evaluation procedures to properly assess model capabilities and benchmark progress in the field. This work presents a novel framework for robot policy comparison that is sample-efficient, statistically rigorous, and applicable to a broad set of evaluation metrics used in practice. Based on safe, anytime-valid inference (SAVI), our test procedure is sequential, allowing the evaluator to stop early when sufficient statistical evidence has accumulated to reach a decision at a pre-specified level of confidence. Unlike previous work developed for binary success, our unified approach addresses a wide range of informative metrics: from discrete partial credit task progress to continuous measures of episodic reward or trajectory smoothness, spanning both parametric and nonparametric comparison problems. Through extensive validation on simulated and real-world evaluation data, we demonstrate up to 70% reduction in evaluation burden compared to standard batch methods and up to 50% reduction compared to state-of-the-art sequential procedures designed for binary outcomes, with no loss of statistical rigor. Notably, our empirical results show that competing policies can be separated more quickly when using fine-grained task progress than binary success metrics.
Distributionally Robust Imitation Learning: Layered Control Architecture for Certifiable Autonomy
Dec 19, 2025Imitation learning (IL) enables autonomous behavior by learning from expert demonstrations. While more sample-efficient than comparative alternatives like reinforcement learning, IL is sensitive to compounding errors induced by distribution shifts. There are two significant sources of distribution shifts when using IL-based feedback laws on systems: distribution shifts caused by policy error and distribution shifts due to exogenous disturbances and endogenous model errors due to lack of learning. Our previously developed approaches, Taylor Series Imitation Learning (TaSIL) and $\mathcal{L}_1$ -Distributionally Robust Adaptive Control (\ellonedrac), address the challenge of distribution shifts in complementary ways. While TaSIL offers robustness against policy error-induced distribution shifts, \ellonedrac offers robustness against distribution shifts due to aleatoric and epistemic uncertainties. To enable certifiable IL for learned and/or uncertain dynamical systems, we formulate \textit{Distributionally Robust Imitation Policy (DRIP)} architecture, a Layered Control Architecture (LCA) that integrates TaSIL and~\ellonedrac. By judiciously designing individual layer-centric input and output requirements, we show how we can guarantee certificates for the entire control pipeline. Our solution paves the path for designing fully certifiable autonomy pipelines, by integrating learning-based components, such as perception, with certifiable model-based decision-making through the proposed LCA approach.
Safe Planning in Interactive Environments via Iterative Policy Updates and Adversarially Robust Conformal Prediction
Nov 13, 2025Safe planning of an autonomous agent in interactive environments -- such as the control of a self-driving vehicle among pedestrians and human-controlled vehicles -- poses a major challenge as the behavior of the environment is unknown and reactive to the behavior of the autonomous agent. This coupling gives rise to interaction-driven distribution shifts where the autonomous agent's control policy may change the environment's behavior, thereby invalidating safety guarantees in existing work. Indeed, recent works have used conformal prediction (CP) to generate distribution-free safety guarantees using observed data of the environment. However, CP's assumption on data exchangeability is violated in interactive settings due to a circular dependency where a control policy update changes the environment's behavior, and vice versa. To address this gap, we propose an iterative framework that robustly maintains safety guarantees across policy updates by quantifying the potential impact of a planned policy update on the environment's behavior. We realize this via adversarially robust CP where we perform a regular CP step in each episode using observed data under the current policy, but then transfer safety guarantees across policy updates by analytically adjusting the CP result to account for distribution shifts. This adjustment is performed based on a policy-to-trajectory sensitivity analysis, resulting in a safe, episodic open-loop planner. We further conduct a contraction analysis of the system providing conditions under which both the CP results and the policy updates are guaranteed to converge. We empirically demonstrate these safety and convergence guarantees on a two-dimensional car-pedestrian case study. To the best of our knowledge, these are the first results that provide valid safety guarantees in such interactive settings.
Occupancy-aware Trajectory Planning for Autonomous Valet Parking in Uncertain Dynamic Environments
Sep 11, 2025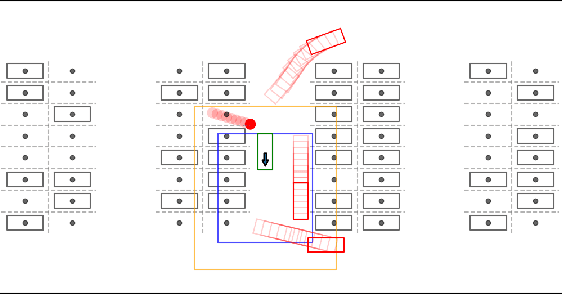
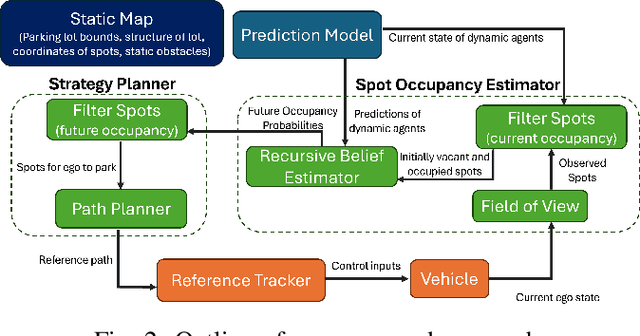
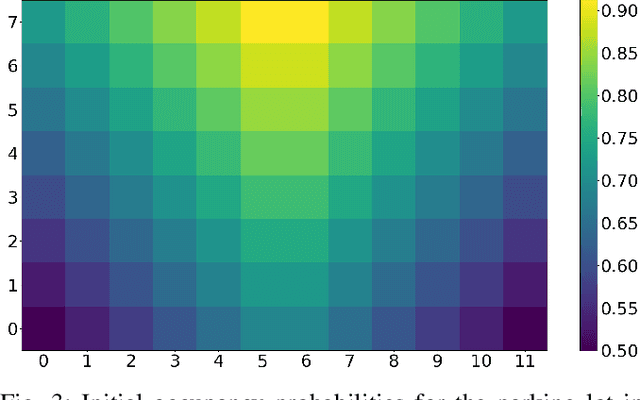
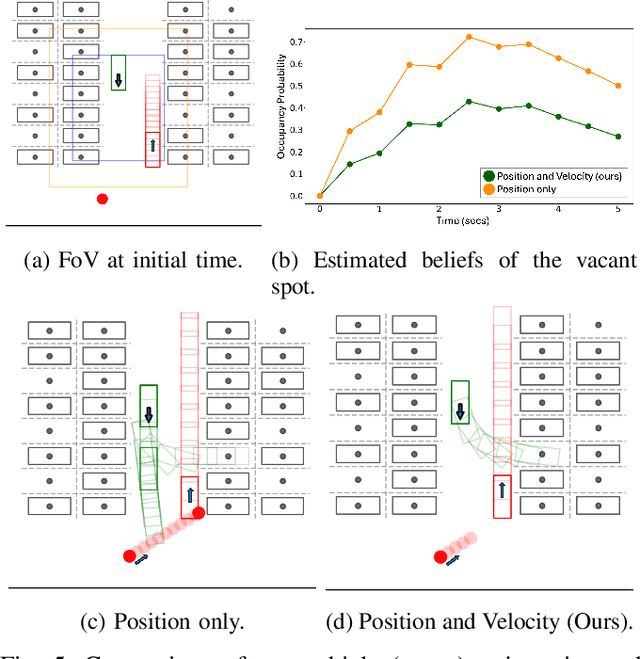
Accurately reasoning about future parking spot availability and integrated planning is critical for enabling safe and efficient autonomous valet parking in dynamic, uncertain environments. Unlike existing methods that rely solely on instantaneous observations or static assumptions, we present an approach that predicts future parking spot occupancy by explicitly distinguishing between initially vacant and occupied spots, and by leveraging the predicted motion of dynamic agents. We introduce a probabilistic spot occupancy estimator that incorporates partial and noisy observations within a limited Field-of-View (FoV) model and accounts for the evolving uncertainty of unobserved regions. Coupled with this, we design a strategy planner that adaptively balances goal-directed parking maneuvers with exploratory navigation based on information gain, and intelligently incorporates wait-and-go behaviors at promising spots. Through randomized simulations emulating large parking lots, we demonstrate that our framework significantly improves parking efficiency, safety margins, and trajectory smoothness compared to existing approaches.
Quad-LCD: Layered Control Decomposition Enables Actuator-Feasible Quadrotor Trajectory Planning
May 15, 2025In this work, we specialize contributions from prior work on data-driven trajectory generation for a quadrotor system with motor saturation constraints. When motors saturate in quadrotor systems, there is an ``uncontrolled drift" of the vehicle that results in a crash. To tackle saturation, we apply a control decomposition and learn a tracking penalty from simulation data consisting of low, medium and high-cost reference trajectories. Our approach reduces crash rates by around $49\%$ compared to baselines on aggressive maneuvers in simulation. On the Crazyflie hardware platform, we demonstrate feasibility through experiments that lead to successful flights. Motivated by the growing interest in data-driven methods to quadrotor planning, we provide open-source lightweight code with an easy-to-use abstraction of hardware platforms.
* 4 pages, 4 figures
Graph-based Path Planning with Dynamic Obstacle Avoidance for Autonomous Parking
Apr 17, 2025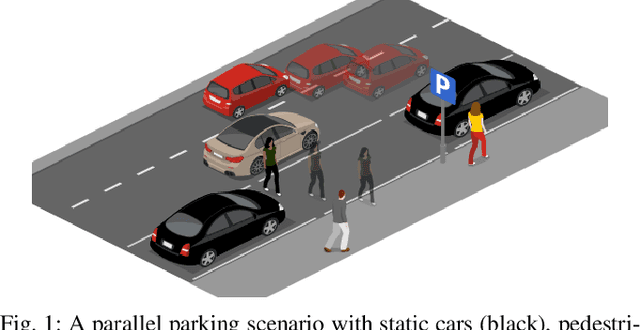
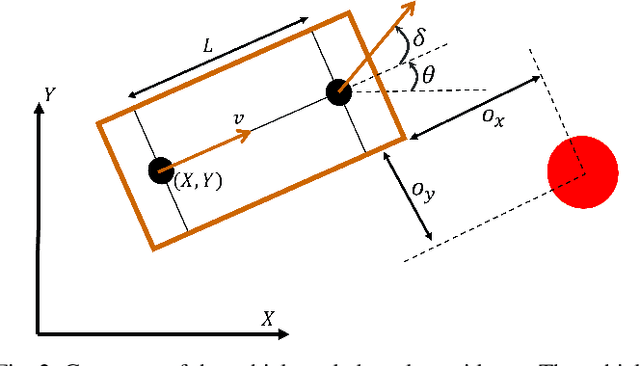
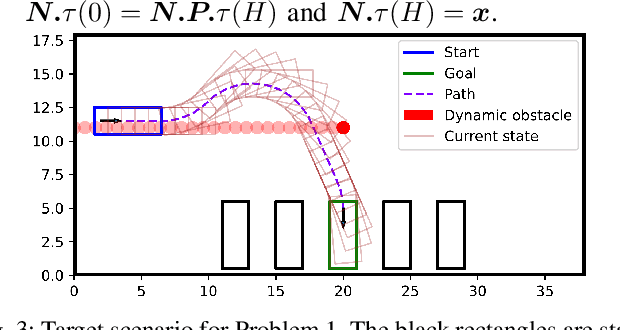
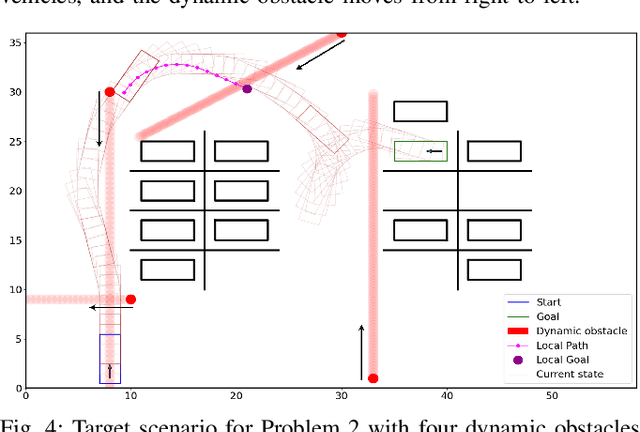
Safe and efficient path planning in parking scenarios presents a significant challenge due to the presence of cluttered environments filled with static and dynamic obstacles. To address this, we propose a novel and computationally efficient planning strategy that seamlessly integrates the predictions of dynamic obstacles into the planning process, ensuring the generation of collision-free paths. Our approach builds upon the conventional Hybrid A star algorithm by introducing a time-indexed variant that explicitly accounts for the predictions of dynamic obstacles during node exploration in the graph, thus enabling dynamic obstacle avoidance. We integrate the time-indexed Hybrid A star algorithm within an online planning framework to compute local paths at each planning step, guided by an adaptively chosen intermediate goal. The proposed method is validated in diverse parking scenarios, including perpendicular, angled, and parallel parking. Through simulations, we showcase our approach's potential in greatly improving the efficiency and safety when compared to the state of the art spline-based planning method for parking situations.
Learning with Imperfect Models: When Multi-step Prediction Mitigates Compounding Error
Apr 02, 2025



Compounding error, where small prediction mistakes accumulate over time, presents a major challenge in learning-based control. For example, this issue often limits the performance of model-based reinforcement learning and imitation learning. One common approach to mitigate compounding error is to train multi-step predictors directly, rather than relying on autoregressive rollout of a single-step model. However, it is not well understood when the benefits of multi-step prediction outweigh the added complexity of learning a more complicated model. In this work, we provide a rigorous analysis of this trade-off in the context of linear dynamical systems. We show that when the model class is well-specified and accurately captures the system dynamics, single-step models achieve lower asymptotic prediction error. On the other hand, when the model class is misspecified due to partial observability, direct multi-step predictors can significantly reduce bias and thus outperform single-step approaches. These theoretical results are supported by numerical experiments, wherein we also (a) empirically evaluate an intermediate strategy which trains a single-step model using a multi-step loss and (b) evaluate performance of single step and multi-step predictors in a closed loop control setting.