 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonconvex Linear System Identification with Minimal State Representation
Apr 26, 2025
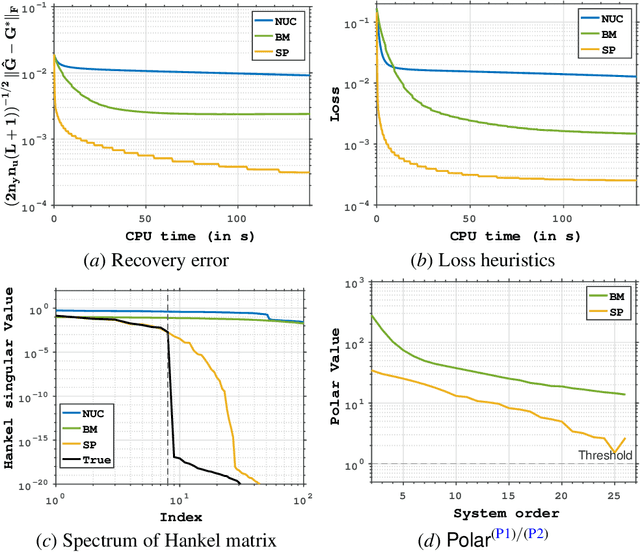
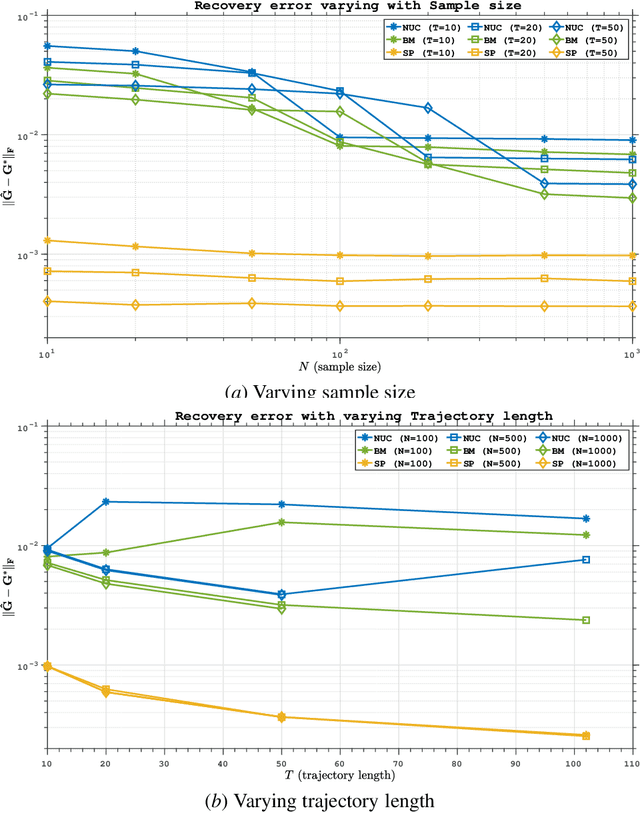
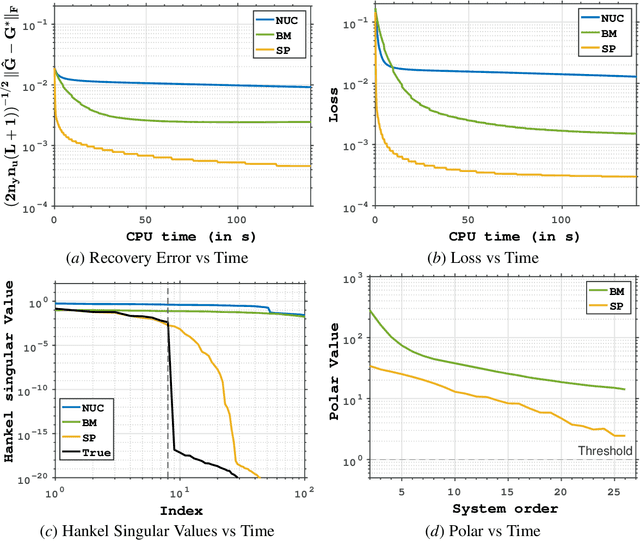
Low-order linear System IDentification (SysID) addresses the challenge of estimating the parameters of a linear dynamical system from finite samples of observations and control inputs with minimal state representation. Traditional approaches often utilize Hankel-rank minimization, which relies on convex relaxations that can require numerous, costly singular value decompositions (SVDs) to optimize. In this work, we propose two nonconvex reformulations to tackle low-order SysID (i) Burer-Monterio (BM) factorization of the Hankel matrix for efficient nuclear norm minimization, and (ii) optimizing directly over system parameters for real, diagonalizable systems with an atomic norm style decomposition. These reformulations circumvent the need for repeated heavy SVD computations, significantly improving computational efficiency. Moreover, we prove that optimizing directly over the system parameters yields lower statistical error rates, and lower sample complexities that do not scale linearly with trajectory length like in Hankel-nuclear norm minimization. Additionally, while our proposed formulations are nonconvex, we provide theoretical guarantees of achieving global optimality in polynomial time. Finally, we demonstrate algorithms that solve these nonconvex programs and validate our theoretical claims on synthetic data.
Logarithmic Regret for Nonlinear Control
Jan 17, 2025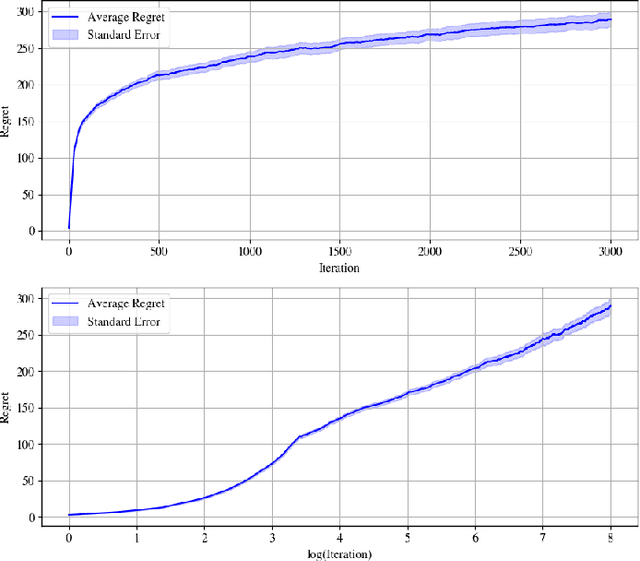
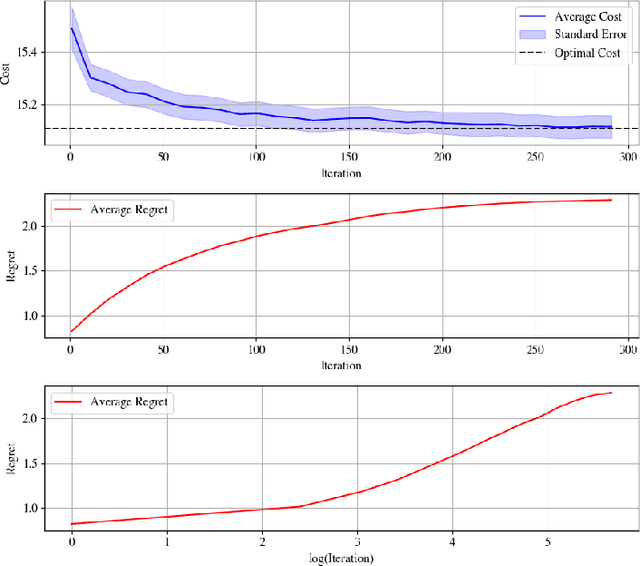
We address the problem of learning to control an unknown nonlinear dynamical system through sequential interactions. Motivated by high-stakes applications in which mistakes can be catastrophic, such as robotics and healthcare, we study situations where it is possible for fast sequential learning to occur. Fast sequential learning is characterized by the ability of the learning agent to incur logarithmic regret relative to a fully-informed baseline. We demonstrate that fast sequential learning is achievable in a diverse class of continuous control problems where the system dynamics depend smoothly on unknown parameters, provided the optimal control policy is persistently exciting. Additionally, we derive a regret bound which grows with the square root of the number of interactions for cases where the optimal policy is not persistently exciting. Our results provide the first regret bounds for controlling nonlinear dynamical systems depending nonlinearly on unknown parameters. We validate the trends our theory predicts in simulation on a simple dynamical system.
Shallow diffusion networks provably learn hidden low-dimensional structure
Oct 15, 2024Diffusion-based generative models provide a powerful framework for learning to sample from a complex target distribution. The remarkable empirical success of these models applied to high-dimensional signals, including images and video, stands in stark contrast to classical results highlighting the curse of dimensionality for distribution recovery. In this work, we take a step towards understanding this gap through a careful analysis of learning diffusion models over the Barron space of single layer neural networks. In particular, we show that these shallow models provably adapt to simple forms of low dimensional structure, thereby avoiding the curse of dimensionality. We combine our results with recent analyses of sampling with diffusion models to provide an end-to-end sample complexity bound for learning to sample from structured distributions. Importantly, our results do not require specialized architectures tailored to particular latent structures, and instead rely on the low-index structure of the Barron space to adapt to the underlying distribution.
Guarantees for Nonlinear Representation Learning: Non-identical Covariates, Dependent Data, Fewer Samples
Oct 15, 2024


A driving force behind the diverse applicability of modern machine learning is the ability to extract meaningful features across many sources. However, many practical domains involve data that are non-identically distributed across sources, and statistically dependent within its source, violating vital assumptions in existing theoretical studies. Toward addressing these issues, we establish statistical guarantees for learning general $\textit{nonlinear}$ representations from multiple data sources that admit different input distributions and possibly dependent data. Specifically, we study the sample-complexity of learning $T+1$ functions $f_\star^{(t)} \circ g_\star$ from a function class $\mathcal F \times \mathcal G$, where $f_\star^{(t)}$ are task specific linear functions and $g_\star$ is a shared nonlinear representation. A representation $\hat g$ is estimated using $N$ samples from each of $T$ source tasks, and a fine-tuning function $\hat f^{(0)}$ is fit using $N'$ samples from a target task passed through $\hat g$. We show that when $N \gtrsim C_{\mathrm{dep}} (\mathrm{dim}(\mathcal F) + \mathrm{C}(\mathcal G)/T)$, the excess risk of $\hat f^{(0)} \circ \hat g$ on the target task decays as $\nu_{\mathrm{div}} \big(\frac{\mathrm{dim}(\mathcal F)}{N'} + \frac{\mathrm{C}(\mathcal G)}{N T} \big)$, where $C_{\mathrm{dep}}$ denotes the effect of data dependency, $\nu_{\mathrm{div}}$ denotes an (estimatable) measure of $\textit{task-diversity}$ between the source and target tasks, and $\mathrm C(\mathcal G)$ denotes the complexity of the representation class $\mathcal G$. In particular, our analysis reveals: as the number of tasks $T$ increases, both the sample requirement and risk bound converge to that of $r$-dimensional regression as if $g_\star$ had been given, and the effect of dependency only enters the sample requirement, leaving the risk bound matching the iid setting.
A Short Information-Theoretic Analysis of Linear Auto-Regressive Learning
Sep 10, 2024In this note, we give a short information-theoretic proof of the consistency of the Gaussian maximum likelihood estimator in linear auto-regressive models. Our proof yields nearly optimal non-asymptotic rates for parameter recovery and works without any invocation of stability in the case of finite hypothesis classes.
Active Learning for Control-Oriented Identification of Nonlinear Systems
Apr 13, 2024


Model-based reinforcement learning is an effective approach for controlling an unknown system. It is based on a longstanding pipeline familiar to the control community in which one performs experiments on the environment to collect a dataset, uses the resulting dataset to identify a model of the system, and finally performs control synthesis using the identified model. As interacting with the system may be costly and time consuming, targeted exploration is crucial for developing an effective control-oriented model with minimal experimentation. Motivated by this challenge, recent work has begun to study finite sample data requirements and sample efficient algorithms for the problem of optimal exploration in model-based reinforcement learning. However, existing theory and algorithms are limited to model classes which are linear in the parameters. Our work instead focuses on models with nonlinear parameter dependencies, and presents the first finite sample analysis of an active learning algorithm suitable for a general class of nonlinear dynamics. In certain settings, the excess control cost of our algorithm achieves the optimal rate, up to logarithmic factors. We validate our approach in simulation, showcasing the advantage of active, control-oriented exploration for controlling nonlinear systems.
Rate-Optimal Non-Asymptotics for the Quadratic Prediction Error Method
Apr 11, 2024We study the quadratic prediction error method -- i.e., nonlinear least squares -- for a class of time-varying parametric predictor models satisfying a certain identifiability condition. While this method is known to asymptotically achieve the optimal rate for a wide range of problems, there have been no non-asymptotic results matching these optimal rates outside of a select few, typically linear, model classes. By leveraging modern tools from learning with dependent data, we provide the first rate-optimal non-asymptotic analysis of this method for our more general setting of nonlinearly parametrized model classes. Moreover, we show that our results can be applied to a particular class of identifiable AutoRegressive Moving Average (ARMA) models, resulting in the first optimal non-asymptotic rates for identification of ARMA models.
Sharp Rates in Dependent Learning Theory: Avoiding Sample Size Deflation for the Square Loss
Feb 08, 2024In this work, we study statistical learning with dependent ($\beta$-mixing) data and square loss in a hypothesis class $\mathscr{F}\subset L_{\Psi_p}$ where $\Psi_p$ is the norm $\|f\|_{\Psi_p} \triangleq \sup_{m\geq 1} m^{-1/p} \|f\|_{L^m} $ for some $p\in [2,\infty]$. Our inquiry is motivated by the search for a sharp noise interaction term, or variance proxy, in learning with dependent data. Absent any realizability assumption, typical non-asymptotic results exhibit variance proxies that are deflated \emph{multiplicatively} by the mixing time of the underlying covariates process. We show that whenever the topologies of $L^2$ and $\Psi_p$ are comparable on our hypothesis class $\mathscr{F}$ -- that is, $\mathscr{F}$ is a weakly sub-Gaussian class: $\|f\|_{\Psi_p} \lesssim \|f\|_{L^2}^\eta$ for some $\eta\in (0,1]$ -- the empirical risk minimizer achieves a rate that only depends on the complexity of the class and second order statistics in its leading term. Our result holds whether the problem is realizable or not and we refer to this as a \emph{near mixing-free rate}, since direct dependence on mixing is relegated to an additive higher order term. We arrive at our result by combining the above notion of a weakly sub-Gaussian class with mixed tail generic chaining. This combination allows us to compute sharp, instance-optimal rates for a wide range of problems. %Our approach, reliant on mixed tail generic chaining, allows us to obtain sharp, instance-optimal rates. Examples that satisfy our framework include sub-Gaussian linear regression, more general smoothly parameterized function classes, finite hypothesis classes, and bounded smoothness classes.
A Tutorial on the Non-Asymptotic Theory of System Identification
Sep 07, 2023This tutorial serves as an introduction to recently developed non-asymptotic methods in the theory of -- mainly linear -- system identification. We emphasize tools we deem particularly useful for a range of problems in this domain, such as the covering technique, the Hanson-Wright Inequality and the method of self-normalized martingales. We then employ these tools to give streamlined proofs of the performance of various least-squares based estimators for identifying the parameters in autoregressive models. We conclude by sketching out how the ideas presented herein can be extended to certain nonlinear identification problems.
The noise level in linear regression with dependent data
May 18, 2023We derive upper bounds for random design linear regression with dependent ($\beta$-mixing) data absent any realizability assumptions. In contrast to the strictly realizable martingale noise regime, no sharp instance-optimal non-asymptotics are available in the literature. Up to constant factors, our analysis correctly recovers the variance term predicted by the Central Limit Theorem -- the noise level of the problem -- and thus exhibits graceful degradation as we introduce misspecification. Past a burn-in, our result is sharp in the moderate deviations regime, and in particular does not inflate the leading order term by mixing time factors.