 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinating Planning and Tracking in Layered Control Policies via Actor-Critic Learning
Aug 03, 2024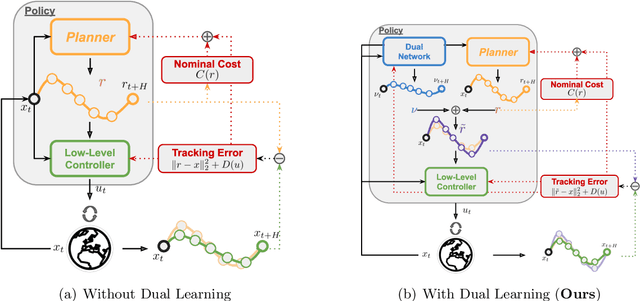
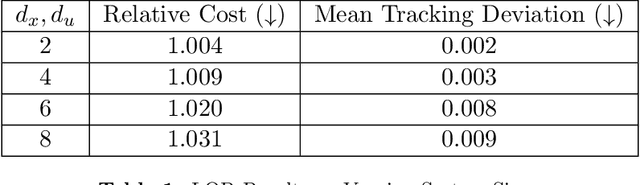
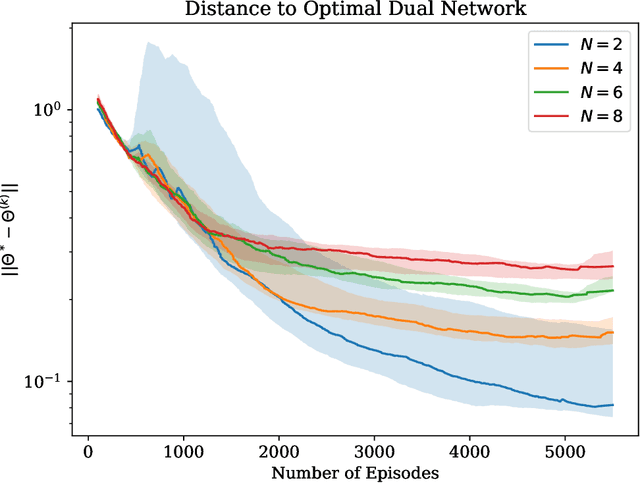
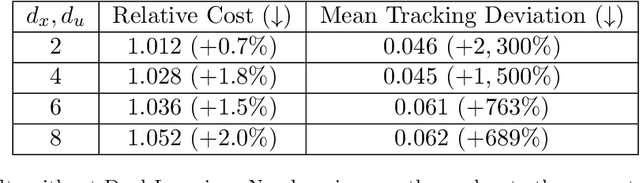
We propose a reinforcement learning (RL)-based algorithm to jointly train (1) a trajectory planner and (2) a tracking controller in a layered control architecture. Our algorithm arises naturally from a rewrite of the underlying optimal control problem that lends itself to an actor-critic learning approach. By explicitly learning a \textit{dual} network to coordinate the interaction between the planning and tracking layers, we demonstrate the ability to achieve an effective consensus between the two components, leading to an interpretable policy. We theoretically prove that our algorithm converges to the optimal dual network in the Linear Quadratic Regulator (LQR) setting and empirically validate its applicability to nonlinear systems through simulation experiments on a unicycle model.
A Data-Driven Approach to Synthesizing Dynamics-Aware Trajectories for Underactuated Robotic Systems
Jul 25, 2023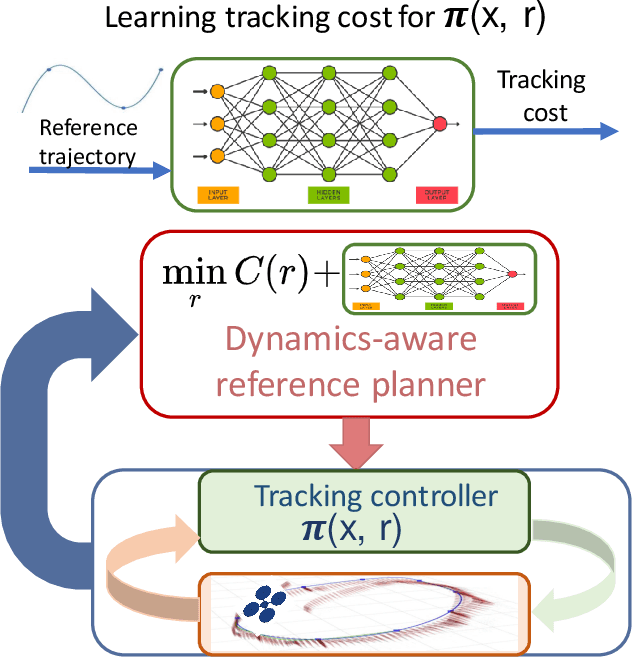
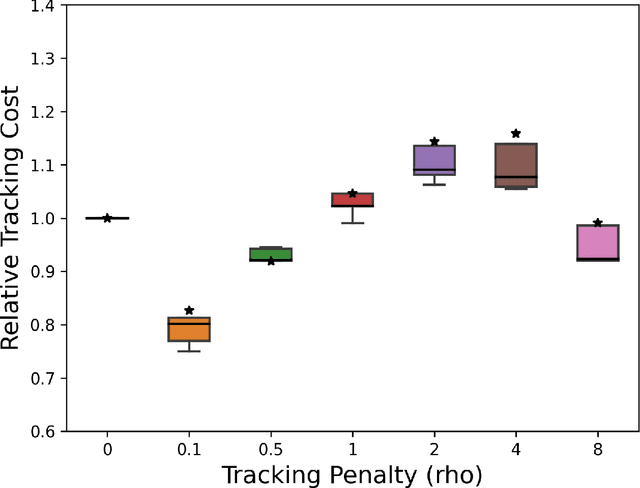
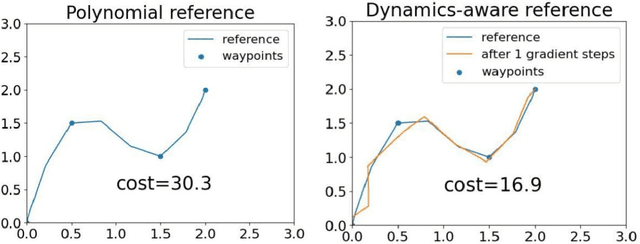
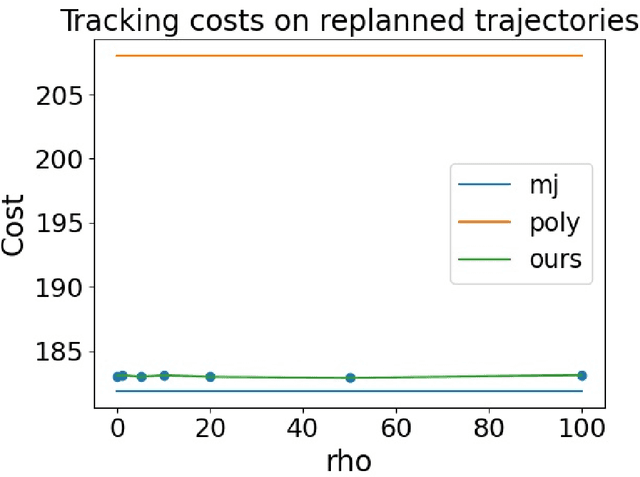
We consider joint trajectory generation and tracking control for under-actuated robotic systems. A common solution is to use a layered control architecture, where the top layer uses a simplified model of system dynamics for trajectory generation, and the low layer ensures approximate tracking of this trajectory via feedback control. While such layered control architectures are standard and work well in practice, selecting the simplified model used for trajectory generation typically relies on engineering intuition and experience. In this paper, we propose an alternative data-driven approach to dynamics-aware trajectory generation. We show that a suitable augmented Lagrangian reformulation of a global nonlinear optimal control problem results in a layered decomposition of the overall problem into trajectory planning and feedback control layers. Crucially, the resulting trajectory optimization is dynamics-aware, in that, it is modified with a tracking penalty regularizer encoding the dynamic feasibility of the generated trajectory. We show that this tracking penalty regularizer can be learned from system rollouts for independently-designed low layer feedback control policies, and instantiate our framework in the context of a unicycle and a quadrotor control problem in simulation. Further, we show that our approach handles the sim-to-real gap through experiments on the quadrotor hardware platform without any additional training. For both the synthetic unicycle example and the quadrotor system, our framework shows significant improvements in both computation time and dynamic feasibility in simulation and hardware experiments.
Toward Certified Robustness Against Real-World Distribution Shifts
Jun 09, 2022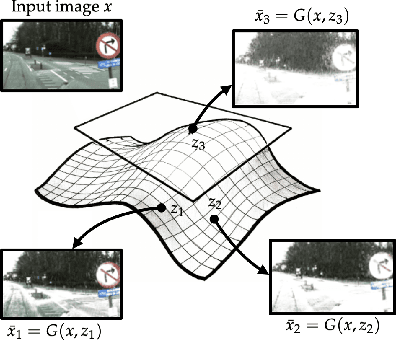
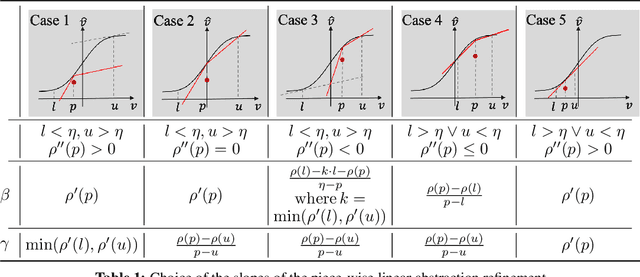
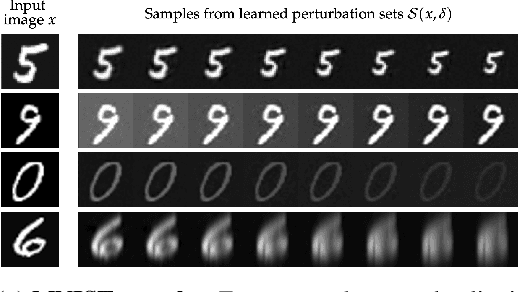
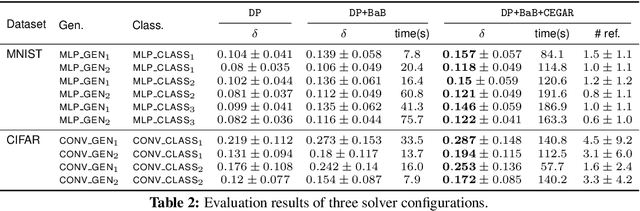
We consider the problem of certifying the robustness of deep neural networks against real-world distribution shifts. To do so, we bridge the gap between hand-crafted specifications and realistic deployment settings by proposing a novel neural-symbolic verification framework, in which we train a generative model to learn perturbations from data and define specifications with respect to the output of the learned model. A unique challenge arising from this setting is that existing verifiers cannot tightly approximate sigmoid activations, which are fundamental to many state-of-the-art generative models. To address this challenge, we propose a general meta-algorithm for handling sigmoid activations which leverages classical notions of counter-example-guided abstraction refinement. The key idea is to "lazily" refine the abstraction of sigmoid functions to exclude spurious counter-examples found in the previous abstraction, thus guaranteeing progress in the verification process while keeping the state-space small. Experiments on the MNIST and CIFAR-10 datasets show that our framework significantly outperforms existing methods on a range of challenging distribution shifts.
Decentralized Role Assignment in Multi-Agent Teams via Empirical Game-Theoretic Analysis
Sep 29, 2021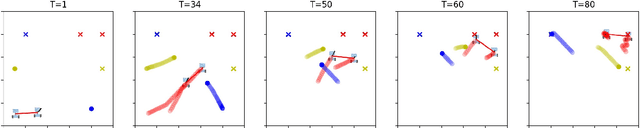
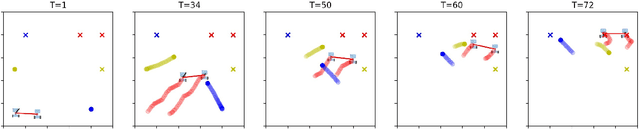
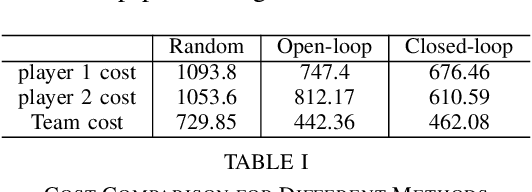
We propose a method, based on empirical game theory, for a robot operating as part of a team to choose its role within the team without explicitly communicating with team members, by leveraging its knowledge about the team structure. To do this, we formulate the role assignment problem as a dynamic game, and borrow tools from empirical game-theoretic analysis to analyze such games. Based on this game-theoretic formulation, we propose a distributed controller for each robot to dynamically decide on the best role to take. We demonstrate our method in simulations of a collaborative planar manipulation scenario in which each agent chooses from a set of feedback control policies at each instant. The agents can effectively collaborate without communication to manipulate the object while also avoiding collisions using our method.
Communication Topology Co-Design in Graph Recurrent Neural Network Based Distributed Control
Apr 28, 2021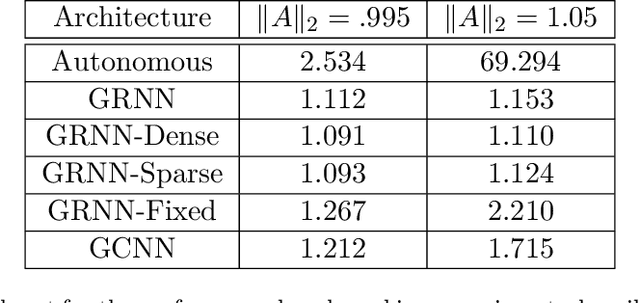
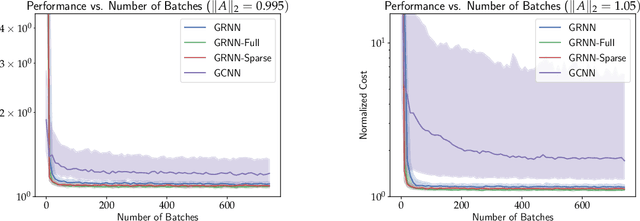
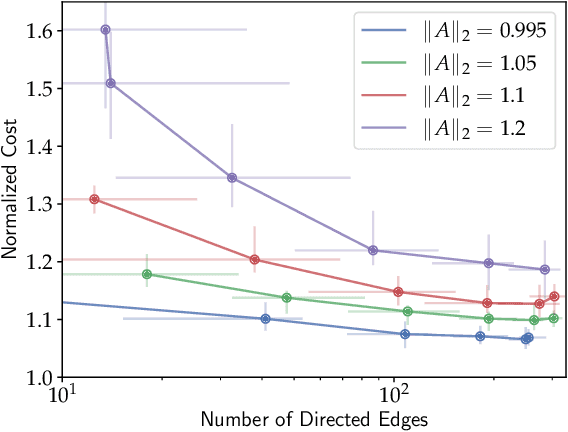

When designing large-scale distributed controllers, the information-sharing constraints between sub-controllers, as defined by a communication topology interconnecting them, are as important as the controller itself. Controllers implemented using dense topologies typically outperform those implemented using sparse topologies, but it is also desirable to minimize the cost of controller deployment. Motivated by the above, we introduce a compact but expressive graph recurrent neural network (GRNN) parameterization of distributed controllers that is well suited for distributed controller and communication topology co-design. Our proposed parameterization enjoys a local and distributed architecture, similar to previous Graph Neural Network (GNN)-based parameterizations, while further naturally allowing for joint optimization of the distributed controller and communication topology needed to implement it. We show that the distributed controller/communication topology co-design task can be posed as an $\ell_1$-regularized empirical risk minimization problem that can be efficiently solved using stochastic gradient methods. We run extensive simulations to study the performance of GRNN-based distributed controllers and show that (a) they achieve performance comparable to GNN-based controllers while having fewer free parameters, and (b) our method allows for performance/communication density tradeoff curves to be efficiently approximated.