 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrace++: Loss-Resilient Real-Time Video Communication under High Network Latency
Paper and Code
May 21, 2023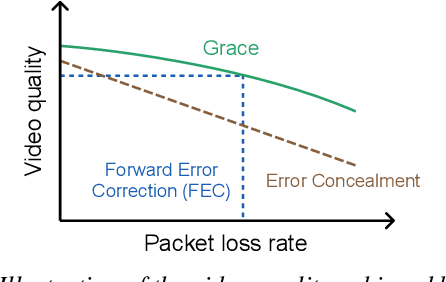

In real-time videos, resending any packets, especially in networks with high latency, can lead to stuttering, poor video quality, and user frustration. Despite extensive research, current real-time video systems still use redundancy to handle packet loss, thus compromising on quality in the the absence of packet loss. Since predicting packet loss is challenging, these systems only enhance their resilience to packet loss after it occurs, leaving some frames insufficiently protected against burst packet losses. They may also add too much redundancy even after the packet loss has subsided. We present Grace++, a new real-time video communication system. With Grace++, (i) a video frame can be decoded, as long as any non-empty subset of its packets are received, and (ii) the quality gracefully degrades as more packets are lost, and (iii) approximates that of a standard codec (like H.265) in absence of packet loss. To achieve this, Grace++ encodes and decodes frames by using neural networks (NNs). It uses a new packetization scheme that makes packet loss appear to have the same effect as randomly masking (zeroing) a subset of elements in the NN-encoded output, and the NN encoder and decoder are specially trained to achieve decent quality if a random subset of elements in the NN-encoded output are masked. Using various test videos and real network traces, we show that the quality of Grace++ is slightly lower than H.265 when no packets are lost, but significantly reduces the 95th percentile of frame delay (between encoding a frame and its decoding) by 2x when packet loss occurs compared to other loss-resilient schemes while achieving comparable quality. This is because Grace++ does not require retransmission of packets (unless all packets are lost) or skipping of frames.