 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYet Another Watermark for Large Language Models
Sep 16, 2025Existing watermarking methods for large language models (LLMs) mainly embed watermark by adjusting the token sampling prediction or post-processing, lacking intrinsic coupling with LLMs, which may significantly reduce the semantic quality of the generated marked texts. Traditional watermarking methods based on training or fine-tuning may be extendable to LLMs. However, most of them are limited to the white-box scenario, or very time-consuming due to the massive parameters of LLMs. In this paper, we present a new watermarking framework for LLMs, where the watermark is embedded into the LLM by manipulating the internal parameters of the LLM, and can be extracted from the generated text without accessing the LLM. Comparing with related methods, the proposed method entangles the watermark with the intrinsic parameters of the LLM, which better balances the robustness and imperceptibility of the watermark. Moreover, the proposed method enables us to extract the watermark under the black-box scenario, which is computationally efficient for use. Experimental results have also verified the feasibility, superiority and practicality. This work provides a new perspective different from mainstream works, which may shed light on future research.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Parallel Ranking of Ads and Creatives in Real-Time Advertising Systems
Dec 20, 2023
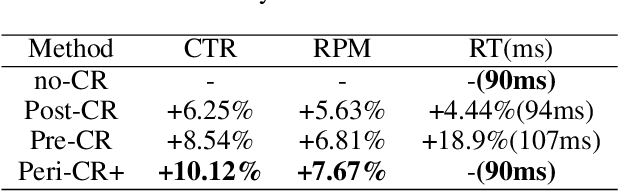
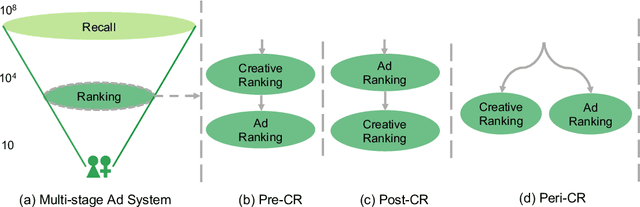
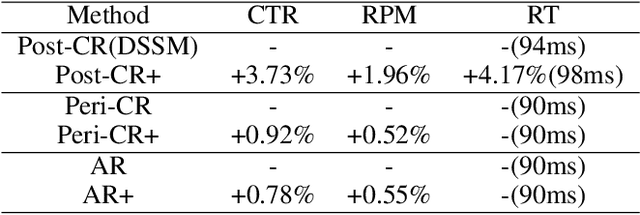
"Creativity is the heart and soul of advertising services". Effective creatives can create a win-win scenario: advertisers can reach target users and achieve marketing objectives more effectively, users can more quickly find products of interest, and platforms can generate more advertising revenue. With the advent of AI-Generated Content, advertisers now can produce vast amounts of creative content at a minimal cost. The current challenge lies in how advertising systems can select the most pertinent creative in real-time for each user personally. Existing methods typically perform serial ranking of ads or creatives, limiting the creative module in terms of both effectiveness and efficiency. In this paper, we propose for the first time a novel architecture for online parallel estimation of ads and creatives ranking, as well as the corresponding offline joint optimization model. The online architecture enables sophisticated personalized creative modeling while reducing overall latency. The offline joint model for CTR estimation allows mutual awareness and collaborative optimization between ads and creatives. Additionally, we optimize the offline evaluation metrics for the implicit feedback sorting task involved in ad creative ranking. We conduct extensive experiments to compare ours with two state-of-the-art approaches. The results demonstrate the effectiveness of our approach in both offline evaluations and real-world advertising platforms online in terms of response time, CTR, and CPM.
JPEG Steganalysis Based on Steganographic Feature Enhancement and Graph Attention Learning
Feb 05, 2023The purpose of image steganalysis is to determine whether the carrier image contains hidden information or not. Since JEPG is the most commonly used image format over social networks, steganalysis in JPEG images is also the most urgently needed to be explored. However, in order to detect whether secret information is hidden within JEPG images, the majority of existing algorithms are designed in conjunction with the popular computer vision related networks, without considering the key characteristics appeared in image steganalysis. It is crucial that the steganographic signal, as an extremely weak signal, can be enhanced during its representation learning process. Motivated by this insight, in this paper, we introduce a novel representation learning algorithm for JPEG steganalysis that is mainly consisting of a graph attention learning module and a feature enhancement module. The graph attention learning module is designed to avoid global feature loss caused by the local feature learning of convolutional neural network and reliance on depth stacking to extend the perceptual domain. The feature enhancement module is applied to prevent the stacking of convolutional layers from weakening the steganographic information. In addition, pretraining as a way to initialize the network weights with a large-scale dataset is utilized to enhance the ability of the network to extract discriminative features. We advocate pretraining with ALASKA2 for the model trained with BOSSBase+BOWS2. The experimental results indicate that the proposed algorithm outperforms previous arts in terms of detection accuracy, which has verified the superiority and applicability of the proposed work.