 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJD-BP: A Joint-Decision Generative Framework for Auto-Bidding and Pricing
Apr 07, 2026Auto-bidding services optimize real-time bidding strategies for advertisers under key performance indicator (KPI) constraints such as target return on investment and budget. However, uncertainties such as model prediction errors and feedback latency can cause bidding strategies to deviate from ex-post optimality, leading to inefficient allocation. To address this issue, we propose JD-BP, a Joint generative Decision framework for Bidding and Pricing. Unlike prior methods, JD-BP jointly outputs a bid value and a pricing correction term that acts additively with the payment rule such as GSP. To mitigate adverse effects of historical constraint violations, we design a memory-less Return-to-Go that encourages future value maximizing of bidding actions while the cumulated bias is handled by the pricing correction. Moreover, a trajectory augmentation algorithm is proposed to generate joint bidding-pricing trajectories from a (possibly arbitrary) base bidding policy, enabling efficient plug-and-play deployment of our algorithm from existing RL/generative bidding models. Finally, we employ an Energy-Based Direct Preference Optimization method in conjunction with a cross-attention module to enhance the joint learning performance of bidding and pricing correction. Offline experiments on the AuctionNet dataset demonstrate that JD-BP achieves state-of-the-art performance. Online A/B tests at JD.com confirm its practical effectiveness, showing a 4.70% increase in ad revenue and a 6.48% improvement in target cost.
RecBundle: A Next-Generation Geometric Paradigm for Explainable Recommender Systems
Mar 17, 2026Recommender systems are inherently dynamic feedback loops where prolonged local interactions accumulate into macroscopic structural degradation such as information cocoons. Existing representation learning paradigms are universally constrained by the assumption of a single flat space, forcing topologically grounded user associations and semantically driven historical interactions to be fitted within the same vector space. This excessive coupling of heterogeneous information renders it impossible for researchers to mechanistically distinguish and identify the sources of systemic bias. To overcome this theoretical bottleneck, we introduce Fiber Bundle from modern differential geometry and propose a novel geometric analysis paradigm for recommender systems. This theory naturally decouples the system space into two hierarchical layers: the base manifold formed by user interaction networks, and the fibers attached to individual user nodes that carry their dynamic preferences. Building upon this, we construct RecBundle, a framework oriented toward next-generation recommender systems that formalizes user collaboration as geometric connection and parallel transport on the base manifold, while mapping content evolution to holonomy transformations on fibers. From this foundation, we identify future application directions encompassing quantitative mechanisms for information cocoons and evolutionary bias, geometric meta-theory for adaptive recommendation, and novel inference architectures integrating large language models (LLMs). Empirical analysis on real-world MovieLens and Amazon Beauty datasets validates the effectiveness of this geometric framework.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Parallel Ranking of Ads and Creatives in Real-Time Advertising Systems
Dec 20, 2023
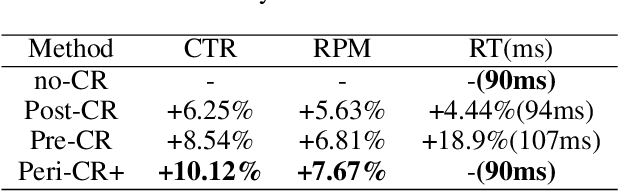
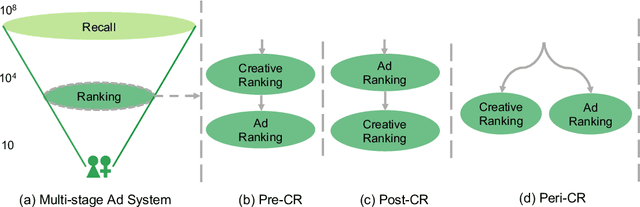
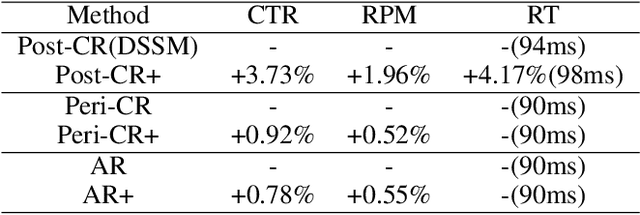
"Creativity is the heart and soul of advertising services". Effective creatives can create a win-win scenario: advertisers can reach target users and achieve marketing objectives more effectively, users can more quickly find products of interest, and platforms can generate more advertising revenue. With the advent of AI-Generated Content, advertisers now can produce vast amounts of creative content at a minimal cost. The current challenge lies in how advertising systems can select the most pertinent creative in real-time for each user personally. Existing methods typically perform serial ranking of ads or creatives, limiting the creative module in terms of both effectiveness and efficiency. In this paper, we propose for the first time a novel architecture for online parallel estimation of ads and creatives ranking, as well as the corresponding offline joint optimization model. The online architecture enables sophisticated personalized creative modeling while reducing overall latency. The offline joint model for CTR estimation allows mutual awareness and collaborative optimization between ads and creatives. Additionally, we optimize the offline evaluation metrics for the implicit feedback sorting task involved in ad creative ranking. We conduct extensive experiments to compare ours with two state-of-the-art approaches. The results demonstrate the effectiveness of our approach in both offline evaluations and real-world advertising platforms online in terms of response time, CTR, and CPM.
Unsupervised Editing for Counterfactual Stories
Dec 10, 2021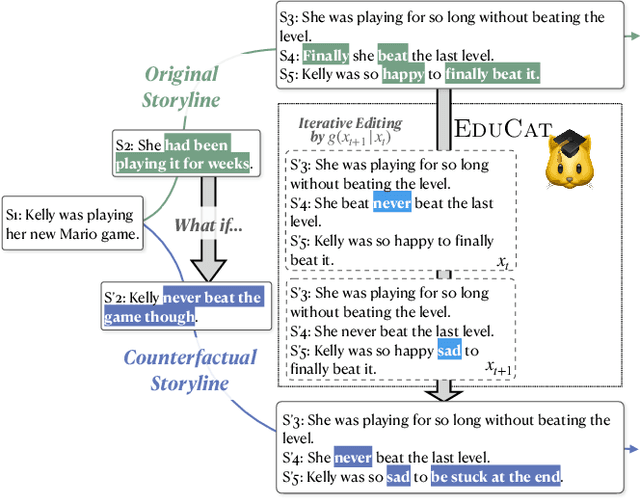

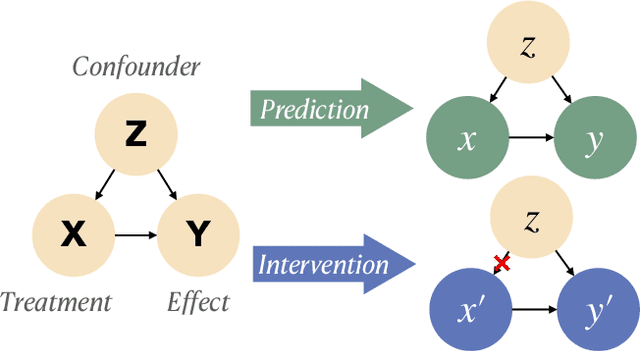
Creating what-if stories requires reasoning about prior statements and possible outcomes of the changed conditions. One can easily generate coherent endings under new conditions, but it would be challenging for current systems to do it with minimal changes to the original story. Therefore, one major challenge is the trade-off between generating a logical story and rewriting with minimal-edits. In this paper, we propose EDUCAT, an editing-based unsupervised approach for counterfactual story rewriting. EDUCAT includes a target position detection strategy based on estimating causal effects of the what-if conditions, which keeps the causal invariant parts of the story. EDUCAT then generates the stories under fluency, coherence and minimal-edits constraints. We also propose a new metric to alleviate the shortcomings of current automatic metrics and better evaluate the trade-off. We evaluate EDUCAT on a public counterfactual story rewriting benchmark. Experiments show that EDUCAT achieves the best trade-off over unsupervised SOTA methods according to both automatic and human evaluation. The resources of EDUCAT are available at: https://github.com/jiangjiechen/EDUCAT.
Probabilistic Graph Reasoning for Natural Proof Generation
Jul 06, 2021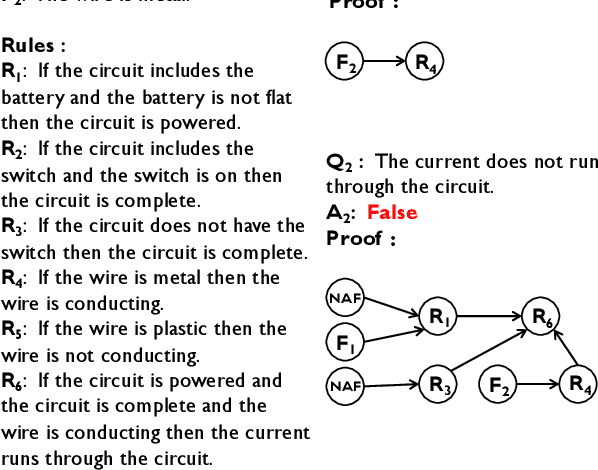
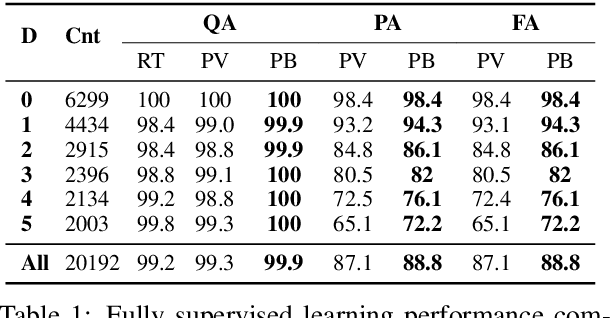
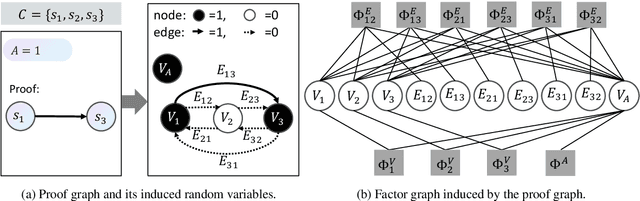
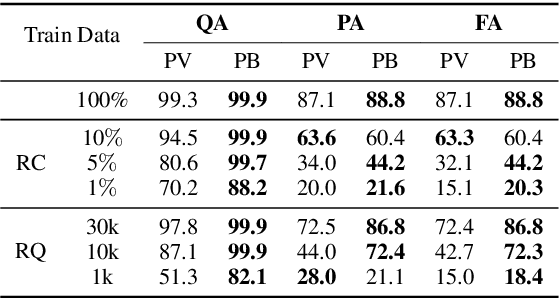
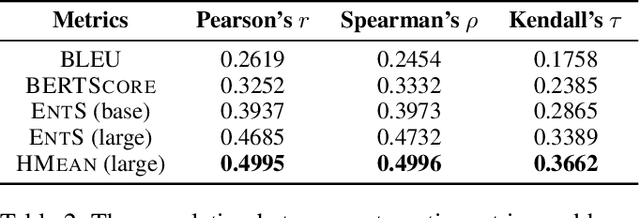
In this paper, we investigate the problem of reasoning over natural language statements. Prior neural based approaches do not explicitly consider the inter-dependency among answers and their proofs. In this paper, we propose PRobr, a novel approach for joint answer prediction and proof generation. PRobr defines a joint probabilistic distribution over all possible proof graphs and answers via an induced graphical model. We then optimize the model using variational approximation on top of neural textual representation. Experiments on multiple datasets under diverse settings (fully supervised, few-shot and zero-shot evaluation) verify the effectiveness of PRobr, e.g., achieving 10%-30% improvement on QA accuracy in few/zero-shot evaluation. Our codes and models can be found at https://github.com/changzhisun/PRobr/.
VOLT: Improving Vocabularization via Optimal Transport for Machine Translation
Dec 31, 2020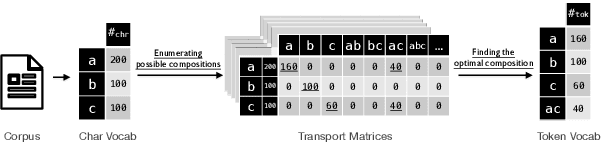
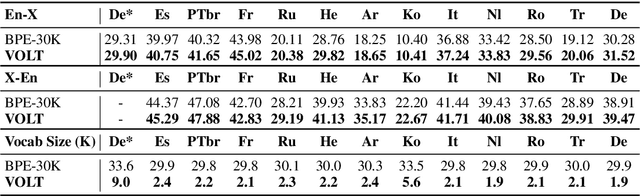
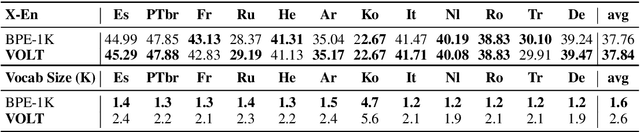
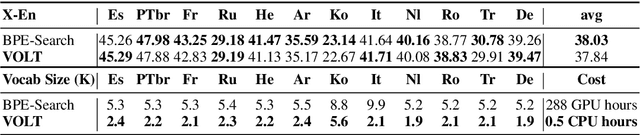
It is well accepted that the choice of token vocabulary largely affects the performance of machine translation. However, due to expensive trial costs, most studies only conduct simple trials with dominant approaches (e.g BPE) and commonly used vocabulary sizes. In this paper, we find an exciting relation between an information-theoretic feature and BLEU scores. With this observation, we formulate the quest of vocabularization -- finding the best token dictionary with a proper size -- as an optimal transport problem. We then propose VOLT, a simple and efficient vocabularization solution without the full and costly trial training. We evaluate our approach on multiple machine translation tasks, including WMT-14 English-German translation, TED bilingual translation, and TED multilingual translation. Empirical results show that VOLT beats widely-used vocabularies on diverse scenarios. For example, VOLT achieves 70% vocabulary size reduction and 0.6 BLEU gain on English-German translation. Also, one advantage of VOLT lies in its low resource consumption. Compared to naive BPE-search, VOLT reduces the search time from 288 GPU hours to 0.5 CPU hours.