 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWEncoder: Adversarial Watermarking Pre-trained Encoders in Contrastive Learning
Aug 08, 2022

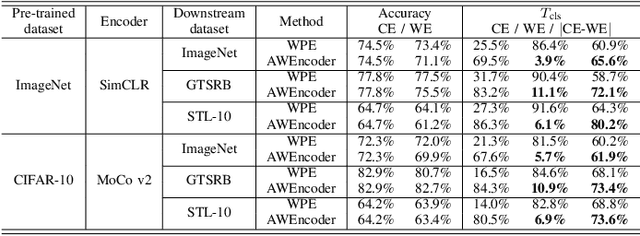
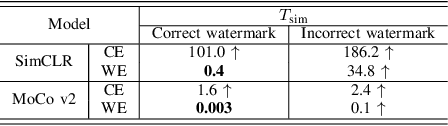
As a self-supervised learning paradigm, contrastive learning has been widely used to pre-train a powerful encoder as an effective feature extractor for various downstream tasks. This process requires numerous unlabeled training data and computational resources, which makes the pre-trained encoder become valuable intellectual property of the owner. However, the lack of a priori knowledge of downstream tasks makes it non-trivial to protect the intellectual property of the pre-trained encoder by applying conventional watermarking methods. To deal with this problem, in this paper, we introduce AWEncoder, an adversarial method for watermarking the pre-trained encoder in contrastive learning. First, as an adversarial perturbation, the watermark is generated by enforcing the training samples to be marked to deviate respective location and surround a randomly selected key image in the embedding space. Then, the watermark is embedded into the pre-trained encoder by further optimizing a joint loss function. As a result, the watermarked encoder not only performs very well for downstream tasks, but also enables us to verify its ownership by analyzing the discrepancy of output provided using the encoder as the backbone under both white-box and black-box conditions. Extensive experiments demonstrate that the proposed work enjoys pretty good effectiveness and robustness on different contrastive learning algorithms and downstream tasks, which has verified the superiority and applicability of the proposed work.
Demosaicing and Superresolution for Color Filter Array via Residual Image Reconstruction and Sparse Representation
Jul 04, 2013A framework of demosaicing and superresolution for color filter array (CFA) via residual image reconstruction and sparse representation is presented.Given the intermediate image produced by certain demosaicing and interpolation technique, a residual image between the final reconstruction image and the intermediate image is reconstructed using sparse representation.The final reconstruction image has richer edges and details than that of the intermediate image. Specifically, a generic dictionary is learned from a large set of composite training data composed of intermediate data and residual data. The learned dictionary implies a mapping between the two data. A specific dictionary adaptive to the input CFA is learned thereafter. Using the adaptive dictionary, the sparse coefficients of intermediate data are computed and transformed to predict residual image. The residual image is added back into the intermediate image to obtain the final reconstruction image. Experimental results demonstrate the state-of-the-art performance in terms of PSNR and subjective visual perception.
Robust Degraded Face Recognition Using Enhanced Local Frequency Descriptor and Multi-scale Competition
Oct 03, 2012
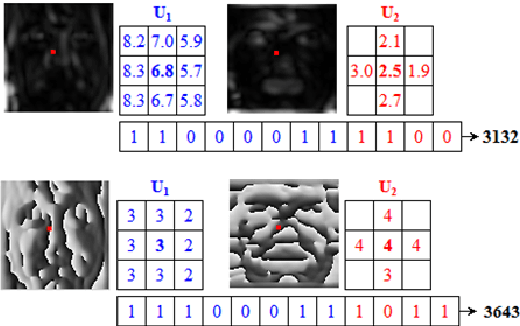


Recognizing degraded faces from low resolution and blurred images are common yet challenging task. Local Frequency Descriptor (LFD) has been proved to be effective for this task yet it is extracted from a spatial neighborhood of a pixel of a frequency plane independently regardless of correlations between frequencies. In addition, it uses a fixed window size named single scale of short-term Frequency transform (STFT). To explore the frequency correlations and preserve low resolution and blur insensitive simultaneously, we propose Enhanced LFD in which information in space and frequency is jointly utilized so as to be more descriptive and discriminative than LFD. The multi-scale competition strategy that extracts multiple descriptors corresponding to multiple window sizes of STFT and take one corresponding to maximum confidence as the final recognition result. The experiments conducted on Yale and FERET databases demonstrate that promising results have been achieved by the proposed Enhanced LFD and multi-scale competition strategy.
Blurred Image Classification based on Adaptive Dictionary
Oct 03, 2012
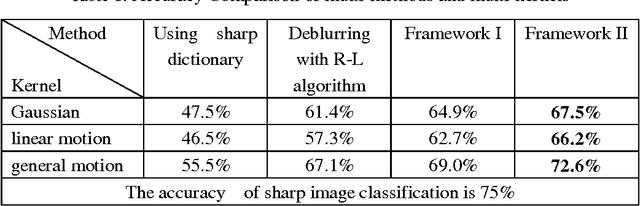

Two types of framework for blurred image classification based on adaptive dictionary are proposed. Given a blurred image, instead of image deblurring, the semantic category of the image is determined by blur insensitive sparse coefficients calculated depending on an adaptive dictionary. The dictionary is adaptive to the Point Spread Function (PSF) estimated from input blurred image. The PSF is assumed to be space invariant and inferred separately in one framework or updated combining with sparse coefficients calculation in an alternative and iterative algorithm in the other framework. The experiment has evaluated three types of blur, naming defocus blur, simple motion blur and camera shake blur. The experiment results confirm the effectiveness of the proposed frameworks.
* 10 pages,2 figures