 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCGS: Progressive Compression of 3D Gaussian Splatting
Mar 11, 2025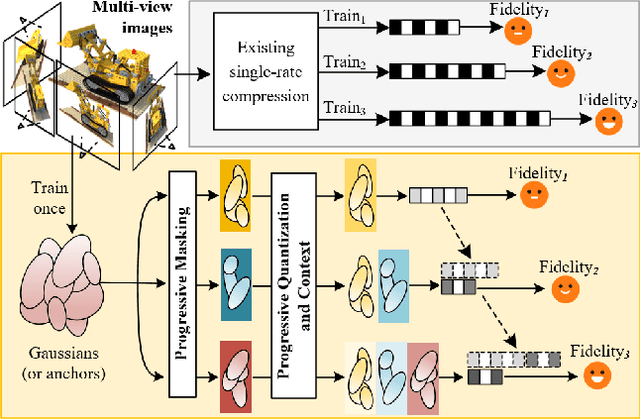
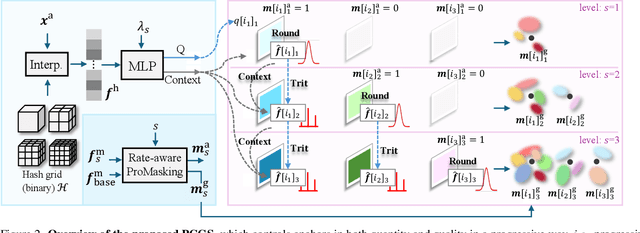
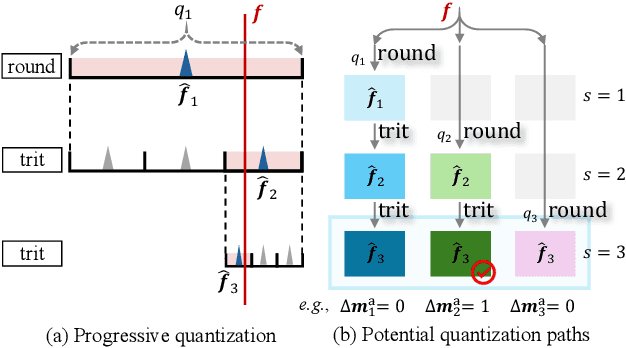
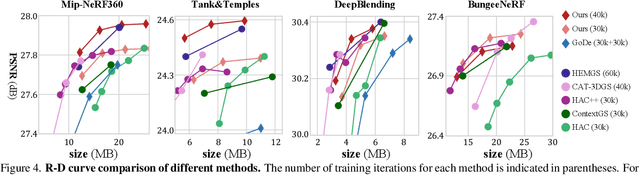
3D Gaussian Splatting (3DGS) achieves impressive rendering fidelity and speed for novel view synthesis. However, its substantial data size poses a significant challenge for practical applications. While many compression techniques have been proposed, they fail to efficiently utilize existing bitstreams in on-demand applications due to their lack of progressivity, leading to a waste of resource. To address this issue, we propose PCGS (Progressive Compression of 3D Gaussian Splatting), which adaptively controls both the quantity and quality of Gaussians (or anchors) to enable effective progressivity for on-demand applications. Specifically, for quantity, we introduce a progressive masking strategy that incrementally incorporates new anchors while refining existing ones to enhance fidelity. For quality, we propose a progressive quantization approach that gradually reduces quantization step sizes to achieve finer modeling of Gaussian attributes. Furthermore, to compact the incremental bitstreams, we leverage existing quantization results to refine probability prediction, improving entropy coding efficiency across progressive levels. Overall, PCGS achieves progressivity while maintaining compression performance comparable to SoTA non-progressive methods. Code available at: github.com/YihangChen-ee/PCGS.
Fast Feedforward 3D Gaussian Splatting Compression
Oct 10, 2024



With 3D Gaussian Splatting (3DGS) advancing real-time and high-fidelity rendering for novel view synthesis, storage requirements pose challenges for their widespread adoption. Although various compression techniques have been proposed, previous art suffers from a common limitation: for any existing 3DGS, per-scene optimization is needed to achieve compression, making the compression sluggish and slow. To address this issue, we introduce Fast Compression of 3D Gaussian Splatting (FCGS), an optimization-free model that can compress 3DGS representations rapidly in a single feed-forward pass, which significantly reduces compression time from minutes to seconds. To enhance compression efficiency, we propose a multi-path entropy module that assigns Gaussian attributes to different entropy constraint paths for balance between size and fidelity. We also carefully design both inter- and intra-Gaussian context models to remove redundancies among the unstructured Gaussian blobs. Overall, FCGS achieves a compression ratio of over 20X while maintaining fidelity, surpassing most per-scene SOTA optimization-based methods. Our code is available at: https://github.com/YihangChen-ee/FCGS.
A Survey for Large Language Models in Biomedicine
Aug 29, 2024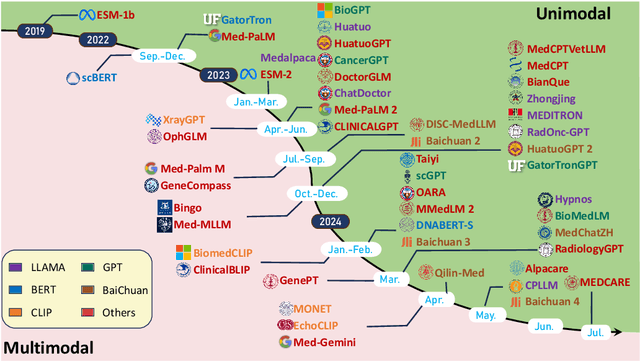
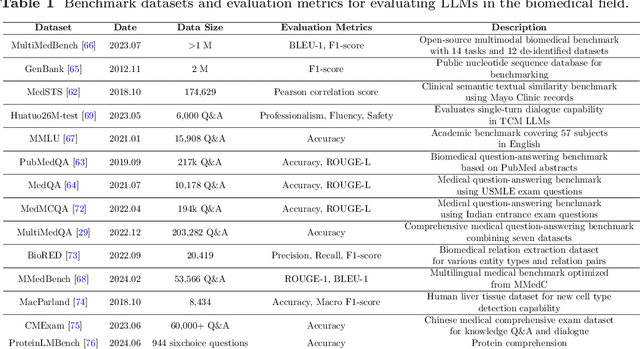
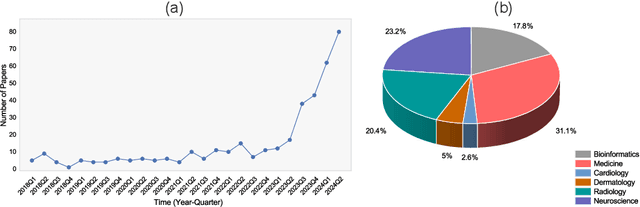
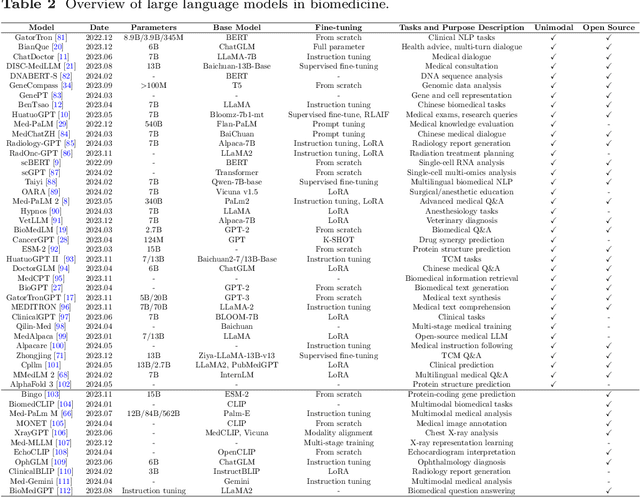
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
Towards Real-World HDR Video Reconstruction: A Large-Scale Benchmark Dataset and A Two-Stage Alignment Network
Apr 30, 2024As an important and practical way to obtain high dynamic range (HDR) video, HDR video reconstruction from sequences with alternating exposures is still less explored, mainly due to the lack of large-scale real-world datasets. Existing methods are mostly trained on synthetic datasets, which perform poorly in real scenes. In this work, to facilitate the development of real-world HDR video reconstruction, we present Real-HDRV, a large-scale real-world benchmark dataset for HDR video reconstruction, featuring various scenes, diverse motion patterns, and high-quality labels. Specifically, our dataset contains 500 LDRs-HDRs video pairs, comprising about 28,000 LDR frames and 4,000 HDR labels, covering daytime, nighttime, indoor, and outdoor scenes. To our best knowledge, our dataset is the largest real-world HDR video reconstruction dataset. Correspondingly, we propose an end-to-end network for HDR video reconstruction, where a novel two-stage strategy is designed to perform alignment sequentially. Specifically, the first stage performs global alignment with the adaptively estimated global offsets, reducing the difficulty of subsequent alignment. The second stage implicitly performs local alignment in a coarse-to-fine manner at the feature level using the adaptive separable convolution. Extensive experiments demonstrate that: (1) models trained on our dataset can achieve better performance on real scenes than those trained on synthetic datasets; (2) our method outperforms previous state-of-the-art methods. Our dataset is available at https://github.com/yungsyu99/Real-HDRV.
RFD-ECNet: Extreme Underwater Image Compression with Reference to Feature Dictionar
Aug 17, 2023Thriving underwater applications demand efficient extreme compression technology to realize the transmission of underwater images (UWIs) in very narrow underwater bandwidth. However, existing image compression methods achieve inferior performance on UWIs because they do not consider the characteristics of UWIs: (1) Multifarious underwater styles of color shift and distance-dependent clarity, caused by the unique underwater physical imaging; (2) Massive redundancy between different UWIs, caused by the fact that different UWIs contain several common ocean objects, which have plenty of similarities in structures and semantics. To remove redundancy among UWIs, we first construct an exhaustive underwater multi-scale feature dictionary to provide coarse-to-fine reference features for UWI compression. Subsequently, an extreme UWI compression network with reference to the feature dictionary (RFD-ECNet) is creatively proposed, which utilizes feature match and reference feature variant to significantly remove redundancy among UWIs. To align the multifarious underwater styles and improve the accuracy of feature match, an underwater style normalized block (USNB) is proposed, which utilizes underwater physical priors extracted from the underwater physical imaging model to normalize the underwater styles of dictionary features toward the input. Moreover, a reference feature variant module (RFVM) is designed to adaptively morph the reference features, improving the similarity between the reference and input features. Experimental results on four UWI datasets show that our RFD-ECNet is the first work that achieves a significant BD-rate saving of 31% over the most advanced VVC.
An information-theoretic learning model based on importance sampling
Feb 23, 2023A crucial assumption underlying the most current theory of machine learning is that the training distribution is identical to the test distribution. However, this assumption may not hold in some real-world applications. In this paper, we develop a learning model based on principles of information theory by minimizing the worst-case loss at prescribed levels of uncertainty. We reformulate the empirical estimation of the risk functional and the distribution deviation constraint based on the importance sampling method. The objective of the proposed approach is to minimize the loss under maximum degradation and hence the resulting problem is a minimax problem which can be converted to an unconstrained minimum problem using the Lagrange method with the Lagrange multiplier $T$. We reveal that the minimization of the objective function under logarithmic transformation is equivalent to the minimization of the p-norm loss with $p=\frac{1}{T}$. We applied the proposed model to the face verification task on Racial Faces in the Wild datasets and showed that the proposed model performs better under large distribution deviations.