 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn information-theoretic learning model based on importance sampling
Feb 23, 2023A crucial assumption underlying the most current theory of machine learning is that the training distribution is identical to the test distribution. However, this assumption may not hold in some real-world applications. In this paper, we develop a learning model based on principles of information theory by minimizing the worst-case loss at prescribed levels of uncertainty. We reformulate the empirical estimation of the risk functional and the distribution deviation constraint based on the importance sampling method. The objective of the proposed approach is to minimize the loss under maximum degradation and hence the resulting problem is a minimax problem which can be converted to an unconstrained minimum problem using the Lagrange method with the Lagrange multiplier $T$. We reveal that the minimization of the objective function under logarithmic transformation is equivalent to the minimization of the p-norm loss with $p=\frac{1}{T}$. We applied the proposed model to the face verification task on Racial Faces in the Wild datasets and showed that the proposed model performs better under large distribution deviations.
Importance Sampling Deterministic Annealing for Clustering
Feb 09, 2023


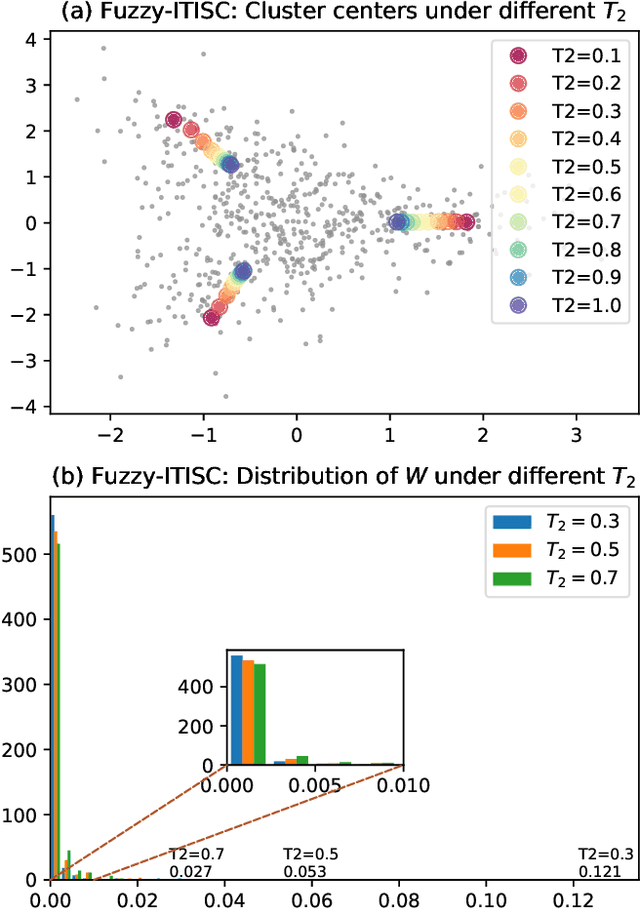
A current assumption of most clustering methods is that the training data and future data are taken from the same distribution. However, this assumption may not hold in some real-world scenarios. In this paper, we propose an importance sampling based deterministic annealing approach (ISDA) for clustering problems which minimizes the worst case of expected distortions under the constraint of distribution deviation. The distribution deviation constraint can be converted to the constraint over a set of weight distributions centered on the uniform distribution derived from importance sampling. The objective of the proposed approach is to minimize the loss under maximum degradation hence the resulting problem is a constrained minimax optimization problem which can be reformulated to an unconstrained problem using the Lagrange method and be solved by the quasi-newton algorithm. Experiment results on synthetic datasets and a real-world load forecasting problem validate the effectiveness of the proposed ISDA. Furthermore, we show that fuzzy c-means is a special case of ISDA with the logarithmic distortion. This observation sheds a new light on the relationship between fuzzy c-means and deterministic annealing clustering algorithms and provides an interesting physical and information-theoretical interpretation for fuzzy exponent $m$.
Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy
Dec 29, 2020



Multi-focus image fusion (MFF) is a popular technique to generate an all-in-focus image, where all objects in the scene are sharp. However, existing methods pay little attention to defocus spread effects of the real-world multi-focus images. Consequently, most of the methods perform badly in the areas near focus map boundaries. According to the idea that each local region in the fused image should be similar to the sharpest one among source images, this paper presents an optimization-based approach to reduce defocus spread effects. Firstly, a new MFF assessmentmetric is presented by combining the principle of structure similarity and detected focus maps. Then, MFF problem is cast into maximizing this metric. The optimization is solved by gradient ascent. Experiments conducted on the real-world dataset verify superiority of the proposed model. The codes are available at https://github.com/xsxjtu/MFF-SSIM.