 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation AI Model for Medical Image Segmentation
Nov 05, 2024Foundation models refer to artificial intelligence (AI) models that are trained on massive amounts of data and demonstrate broad generalizability across various tasks with high accuracy. These models offer versatile, one-for-many or one-for-all solutions, eliminating the need for developing task-specific AI models. Examples of such foundation models include the Chat Generative Pre-trained Transformer (ChatGPT) and the Segment Anything Model (SAM). These models have been trained on millions to billions of samples and have shown wide-ranging and accurate applications in numerous tasks such as text processing (using ChatGPT) and natural image segmentation (using SAM). In medical image segmentation - finding target regions in medical images - there is a growing need for these one-for-many or one-for-all foundation models. Such models could obviate the need to develop thousands of task-specific AI models, which is currently standard practice in the field. They can also be adapted to tasks with datasets too small for effective training. We discuss two paths to achieve foundation models for medical image segmentation and comment on progress, challenges, and opportunities. One path is to adapt or fine-tune existing models, originally developed for natural images, for use with medical images. The second path entails building models from scratch, exclusively training on medical images.
A Survey for Large Language Models in Biomedicine
Aug 29, 2024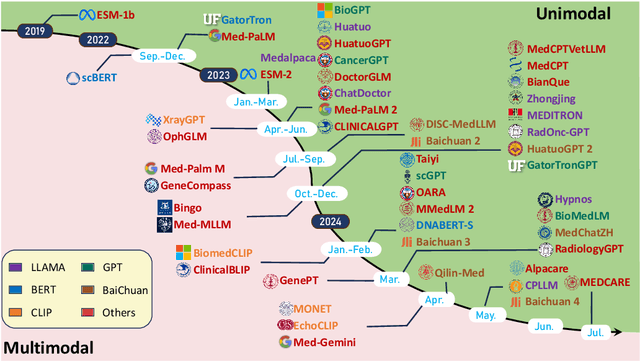
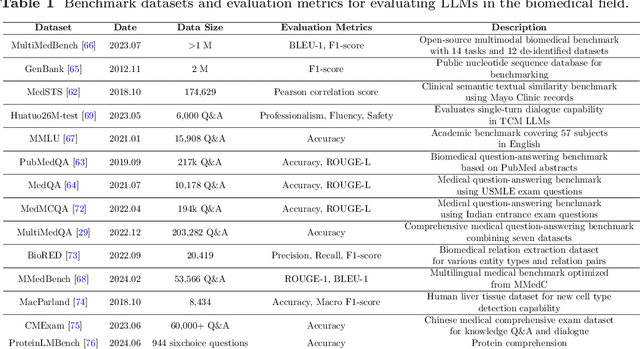
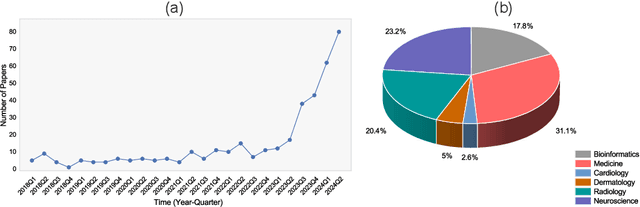
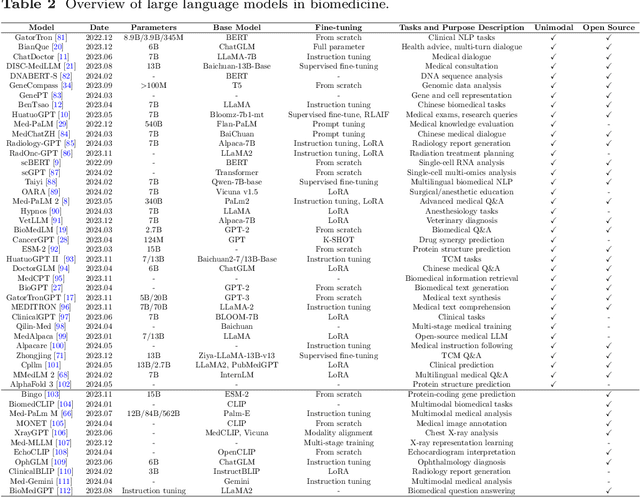
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
The Hidden Adversarial Vulnerabilities of Medical Federated Learning
Oct 21, 2023



In this paper, we delve into the susceptibility of federated medical image analysis systems to adversarial attacks. Our analysis uncovers a novel exploitation avenue: using gradient information from prior global model updates, adversaries can enhance the efficiency and transferability of their attacks. Specifically, we demonstrate that single-step attacks (e.g. FGSM), when aptly initialized, can outperform the efficiency of their iterative counterparts but with reduced computational demand. Our findings underscore the need to revisit our understanding of AI security in federated healthcare settings.
Tackling Heterogeneity in Medical Federated learning via Vision Transformers
Oct 13, 2023Optimization-based regularization methods have been effective in addressing the challenges posed by data heterogeneity in medical federated learning, particularly in improving the performance of underrepresented clients. However, these methods often lead to lower overall model accuracy and slower convergence rates. In this paper, we demonstrate that using Vision Transformers can substantially improve the performance of underrepresented clients without a significant trade-off in overall accuracy. This improvement is attributed to the Vision transformer's ability to capture long-range dependencies within the input data.
Fed-Safe: Securing Federated Learning in Healthcare Against Adversarial Attacks
Oct 12, 2023This paper explores the security aspects of federated learning applications in medical image analysis. Current robustness-oriented methods like adversarial training, secure aggregation, and homomorphic encryption often risk privacy compromises. The central aim is to defend the network against potential privacy breaches while maintaining model robustness against adversarial manipulations. We show that incorporating distributed noise, grounded in the privacy guarantees in federated settings, enables the development of a adversarially robust model that also meets federated privacy standards. We conducted comprehensive evaluations across diverse attack scenarios, parameters, and use cases in cancer imaging, concentrating on pathology, meningioma, and glioma. The results reveal that the incorporation of distributed noise allows for the attainment of security levels comparable to those of conventional adversarial training while requiring fewer retraining samples to establish a robust model.
Exploring adversarial attacks in federated learning for medical imaging
Oct 10, 2023Federated learning offers a privacy-preserving framework for medical image analysis but exposes the system to adversarial attacks. This paper aims to evaluate the vulnerabilities of federated learning networks in medical image analysis against such attacks. Employing domain-specific MRI tumor and pathology imaging datasets, we assess the effectiveness of known threat scenarios in a federated learning environment. Our tests reveal that domain-specific configurations can increase the attacker's success rate significantly. The findings emphasize the urgent need for effective defense mechanisms and suggest a critical re-evaluation of current security protocols in federated medical image analysis systems.
Using image-extracted features to determine heart rate and blink duration for driver sleepiness detection
Dec 08, 2019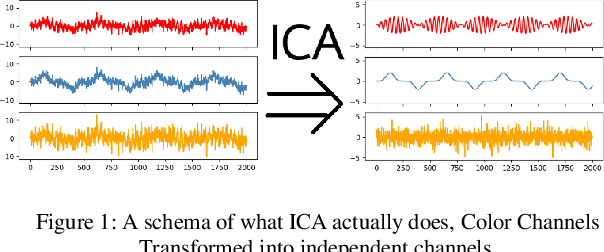
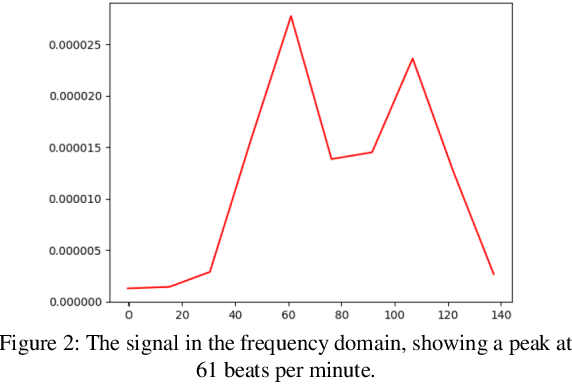


Heart rate and blink duration are two vital physiological signals which give information about cardiac activity and consciousness. Monitoring these two signals is crucial for various applications such as driver drowsiness detection. As there are several problems posed by the conventional systems to be used for continuous, long-term monitoring, a remote blink and ECG monitoring system can be used as an alternative. For estimating the blink duration, two strategies are used. In the first approach, pictures of open and closed eyes are fed into an Artificial Neural Network (ANN) to decide whether the eyes are open or close. In the second approach, they are classified and labeled using Linear Discriminant Analysis (LDA). The labeled images are then be used to determine the blink duration. For heart rate variability, two strategies are used to evaluate the passing blood volume: Independent Component Analysis (ICA); and a chrominance based method. Eye recognition yielded 78-92% accuracy in classifying open/closed eyes with ANN and 71-91% accuracy with LDA. Heart rate evaluations had a mean loss of around 16 Beats Per Minute (BPM) for the ICA strategy and 13 BPM for the chrominance based technique.