 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroVQA++: High-Quality Microscopy Reasoning Dataset with Weakly Supervised Graphs for Multimodal Large Language Model
Nov 14, 2025Multimodal Large Language Models are increasingly applied to biomedical imaging, yet scientific reasoning for microscopy remains limited by the scarcity of large-scale, high-quality training data. We introduce MicroVQA++, a three-stage, large-scale and high-quality microscopy VQA corpus derived from the BIOMEDICA archive. Stage one bootstraps supervision from expert-validated figure-caption pairs sourced from peer-reviewed articles. Stage two applies HiCQA-Graph, a novel heterogeneous graph over images, captions, and QAs that fuses NLI-based textual entailment, CLIP-based vision-language alignment, and agent signals to identify and filter inconsistent samples. Stage three uses a MultiModal Large Language Model (MLLM) agent to generate multiple-choice questions (MCQ) followed by human screening. The resulting release comprises a large training split and a human-checked test split whose Bloom's level hard-sample distribution exceeds the MicroVQA benchmark. Our work delivers (i) a quality-controlled dataset that couples expert literature with graph-based filtering and human refinement; (ii) HiCQA-Graph, the first graph that jointly models (image, caption, QA) for cross-modal consistency filtering; (iii) evidence that careful data construction enables 4B-scale MLLMs to reach competitive microscopy reasoning performance (e.g., GPT-5) and achieve state-of-the-art performance among open-source MLLMs. Code and dataset will be released after the review process concludes.
Unifying Segment Anything in Microscopy with Multimodal Large Language Model
May 16, 2025Accurate segmentation of regions of interest in biomedical images holds substantial value in image analysis. Although several foundation models for biomedical segmentation have currently achieved excellent performance on certain datasets, they typically demonstrate sub-optimal performance on unseen domain data. We owe the deficiency to lack of vision-language knowledge before segmentation. Multimodal Large Language Models (MLLMs) bring outstanding understanding and reasoning capabilities to multimodal tasks, which inspires us to leverage MLLMs to inject Vision-Language Knowledge (VLK), thereby enabling vision models to demonstrate superior generalization capabilities on cross-domain datasets. In this paper, we propose using MLLMs to guide SAM in learning microscopy crose-domain data, unifying Segment Anything in Microscopy, named uLLSAM. Specifically, we propose the Vision-Language Semantic Alignment (VLSA) module, which injects VLK into Segment Anything Model (SAM). We find that after SAM receives global VLK prompts, its performance improves significantly, but there are deficiencies in boundary contour perception. Therefore, we further propose Semantic Boundary Regularization (SBR) to prompt SAM. Our method achieves performance improvements of 7.71% in Dice and 12.10% in SA across 9 in-domain microscopy datasets, achieving state-of-the-art performance. Our method also demonstrates improvements of 6.79% in Dice and 10.08% in SA across 10 out-ofdomain datasets, exhibiting strong generalization capabilities. Code is available at https://github.com/ieellee/uLLSAM.
FacialFlowNet: Advancing Facial Optical Flow Estimation with a Diverse Dataset and a Decomposed Model
Sep 09, 2024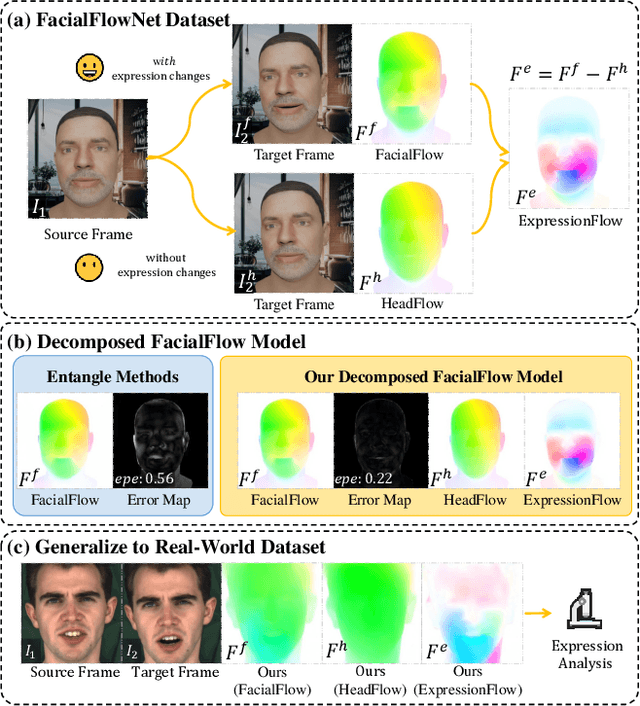


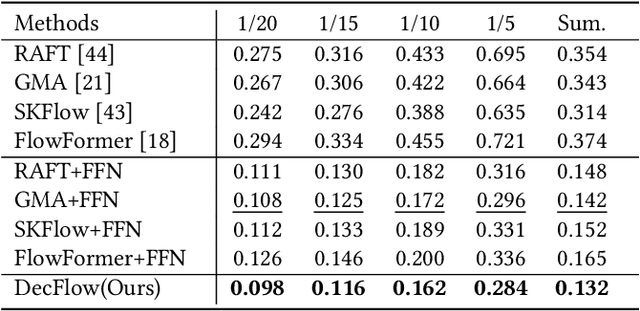
Facial movements play a crucial role in conveying altitude and intentions, and facial optical flow provides a dynamic and detailed representation of it. However, the scarcity of datasets and a modern baseline hinders the progress in facial optical flow research. This paper proposes FacialFlowNet (FFN), a novel large-scale facial optical flow dataset, and the Decomposed Facial Flow Model (DecFlow), the first method capable of decomposing facial flow. FFN comprises 9,635 identities and 105,970 image pairs, offering unprecedented diversity for detailed facial and head motion analysis. DecFlow features a facial semantic-aware encoder and a decomposed flow decoder, excelling in accurately estimating and decomposing facial flow into head and expression components. Comprehensive experiments demonstrate that FFN significantly enhances the accuracy of facial flow estimation across various optical flow methods, achieving up to an 11% reduction in Endpoint Error (EPE) (from 3.91 to 3.48). Moreover, DecFlow, when coupled with FFN, outperforms existing methods in both synthetic and real-world scenarios, enhancing facial expression analysis. The decomposed expression flow achieves a substantial accuracy improvement of 18% (from 69.1% to 82.1%) in micro-expressions recognition. These contributions represent a significant advancement in facial motion analysis and optical flow estimation. Codes and datasets can be found.
Low-latency Space-time Supersampling for Real-time Rendering
Dec 18, 2023With the rise of real-time rendering and the evolution of display devices, there is a growing demand for post-processing methods that offer high-resolution content in a high frame rate. Existing techniques often suffer from quality and latency issues due to the disjointed treatment of frame supersampling and extrapolation. In this paper, we recognize the shared context and mechanisms between frame supersampling and extrapolation, and present a novel framework, Space-time Supersampling (STSS). By integrating them into a unified framework, STSS can improve the overall quality with lower latency. To implement an efficient architecture, we treat the aliasing and warping holes unified as reshading regions and put forth two key components to compensate the regions, namely Random Reshading Masking (RRM) and Efficient Reshading Module (ERM). Extensive experiments demonstrate that our approach achieves superior visual fidelity compared to state-of-the-art (SOTA) methods. Notably, the performance is achieved within only 4ms, saving up to 75\% of time against the conventional two-stage pipeline that necessitates 17ms.
Context-Aware Iteration Policy Network for Efficient Optical Flow Estimation
Dec 14, 2023



Existing recurrent optical flow estimation networks are computationally expensive since they use a fixed large number of iterations to update the flow field for each sample. An efficient network should skip iterations when the flow improvement is limited. In this paper, we develop a Context-Aware Iteration Policy Network for efficient optical flow estimation, which determines the optimal number of iterations per sample. The policy network achieves this by learning contextual information to realize whether flow improvement is bottlenecked or minimal. On the one hand, we use iteration embedding and historical hidden cell, which include previous iterations information, to convey how flow has changed from previous iterations. On the other hand, we use the incremental loss to make the policy network implicitly perceive the magnitude of optical flow improvement in the subsequent iteration. Furthermore, the computational complexity in our dynamic network is controllable, allowing us to satisfy various resource preferences with a single trained model. Our policy network can be easily integrated into state-of-the-art optical flow networks. Extensive experiments show that our method maintains performance while reducing FLOPs by about 40%/20% for the Sintel/KITTI datasets.
Unsupervised Disentangling of Facial Representations with 3D-aware Latent Diffusion Models
Sep 15, 2023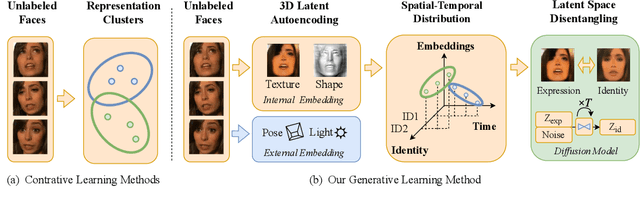
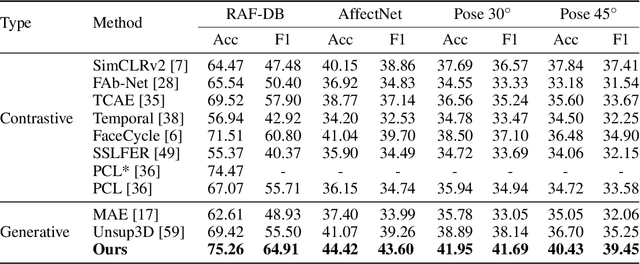
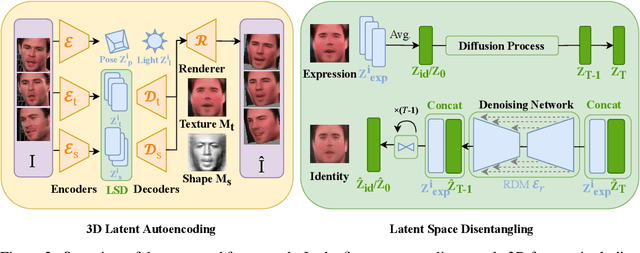
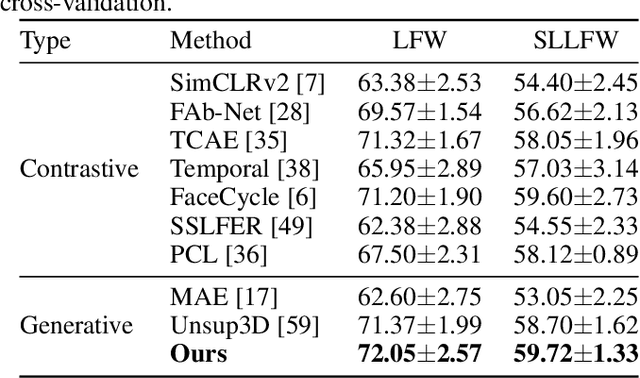
Unsupervised learning of facial representations has gained increasing attention for face understanding ability without heavily relying on large-scale annotated datasets. However, it remains unsolved due to the coupling of facial identities, expressions, and external factors like pose and light. Prior methods primarily focus on 2D factors and pixel-level consistency, leading to incomplete disentangling and suboptimal performance in downstream tasks. In this paper, we propose LatentFace, a novel unsupervised disentangling framework for facial expression and identity representation. We suggest the disentangling problem should be performed in latent space and propose the solution using a 3D-ware latent diffusion model. First, we introduce a 3D-aware autoencoder to encode face images into 3D latent embeddings. Second, we propose a novel representation diffusion model (RDM) to disentangle 3D latent into facial identity and expression. Consequently, our method achieves state-of-the-art performance in facial expression recognition and face verification among unsupervised facial representation learning models.
SAMFlow: Eliminating Any Fragmentation in Optical Flow with Segment Anything Model
Aug 16, 2023Optical Flow Estimation aims to find the 2D dense motion field between two frames. Due to the limitation of model structures and training datasets, existing methods often rely too much on local clues and ignore the integrity of objects, resulting in fragmented motion estimation. Through theoretical analysis, we find the pre-trained large vision models are helpful in optical flow estimation, and we notice that the recently famous Segment Anything Model (SAM) demonstrates a strong ability to segment complete objects, which is suitable for solving the fragmentation problem. We thus propose a solution to embed the frozen SAM image encoder into FlowFormer to enhance object perception. To address the challenge of in-depth utilizing SAM in non-segmentation tasks like optical flow estimation, we propose an Optical Flow Task-Specific Adaption scheme, including a Context Fusion Module to fuse the SAM encoder with the optical flow context encoder, and a Context Adaption Module to adapt the SAM features for optical flow task with Learned Task-Specific Embedding. Our proposed SAMFlow model reaches 0.86/2.10 clean/final EPE and 3.55/12.32 EPE/F1-all on Sintel and KITTI-15 training set, surpassing Flowformer by 8.5%/9.9% and 13.2%/16.3%. Furthermore, our model achieves state-of-the-art performance on the Sintel and KITTI-15 benchmarks, ranking #1 among all two-frame methods on Sintel clean pass.
Uncertainty-Guided Spatial Pruning Architecture for Efficient Frame Interpolation
Aug 12, 2023The video frame interpolation (VFI) model applies the convolution operation to all locations, leading to redundant computations in regions with easy motion. We can use dynamic spatial pruning method to skip redundant computation, but this method cannot properly identify easy regions in VFI tasks without supervision. In this paper, we develop an Uncertainty-Guided Spatial Pruning (UGSP) architecture to skip redundant computation for efficient frame interpolation dynamically. Specifically, pixels with low uncertainty indicate easy regions, where the calculation can be reduced without bringing undesirable visual results. Therefore, we utilize uncertainty-generated mask labels to guide our UGSP in properly locating the easy region. Furthermore, we propose a self-contrast training strategy that leverages an auxiliary non-pruning branch to improve the performance of our UGSP. Extensive experiments show that UGSP maintains performance but reduces FLOPs by 34%/52%/30% compared to baseline without pruning on Vimeo90K/UCF101/MiddleBury datasets. In addition, our method achieves state-of-the-art performance with lower FLOPs on multiple benchmarks.
MVFlow: Deep Optical Flow Estimation of Compressed Videos with Motion Vector Prior
Aug 04, 2023In recent years, many deep learning-based methods have been proposed to tackle the problem of optical flow estimation and achieved promising results. However, they hardly consider that most videos are compressed and thus ignore the pre-computed information in compressed video streams. Motion vectors, one of the compression information, record the motion of the video frames. They can be directly extracted from the compression code stream without computational cost and serve as a solid prior for optical flow estimation. Therefore, we propose an optical flow model, MVFlow, which uses motion vectors to improve the speed and accuracy of optical flow estimation for compressed videos. In detail, MVFlow includes a key Motion-Vector Converting Module, which ensures that the motion vectors can be transformed into the same domain of optical flow and then be utilized fully by the flow estimation module. Meanwhile, we construct four optical flow datasets for compressed videos containing frames and motion vectors in pairs. The experimental results demonstrate the superiority of our proposed MVFlow, which can reduce the AEPE by 1.09 compared to existing models or save 52% time to achieve similar accuracy to existing models.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 19, 2021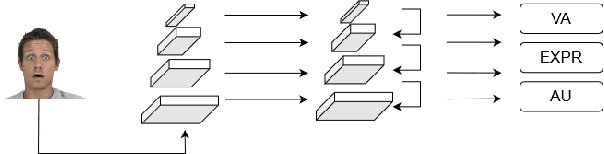
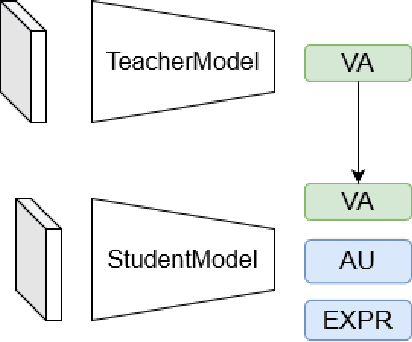
Affective Analysis is not a single task, and the valence-arousal value, expression class, and action unit can be predicted at the same time. Previous researches did not pay enough attention to the entanglement and hierarchical relation of these three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply a teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperforms other models. This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.